 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Crawl
May 29, 2019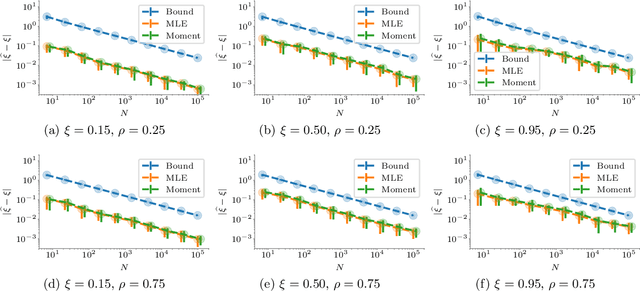
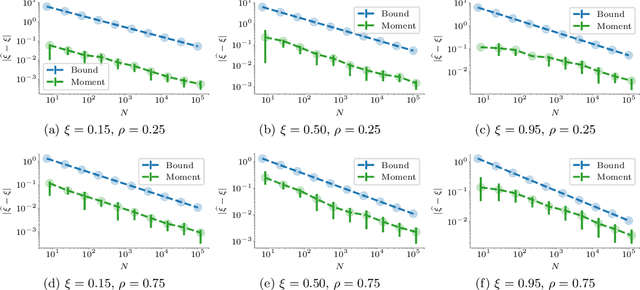
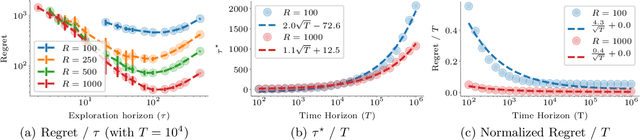
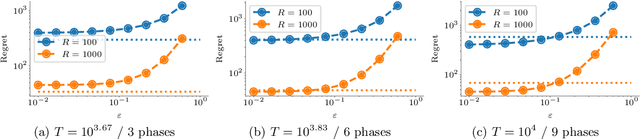
Web crawling is the problem of keeping a cache of webpages fresh, i.e., having the most recent copy available when a page is requested. This problem is usually coupled with the natural restriction that the bandwidth available to the web crawler is limited. The corresponding optimization problem was solved optimally by Azar et al. [2018] under the assumption that, for each webpage, both the elapsed time between two changes and the elapsed time between two requests follow a Poisson distribution with known parameters. In this paper, we study the same control problem but under the assumption that the change rates are unknown a priori, and thus we need to estimate them in an online fashion using only partial observations (i.e., single-bit signals indicating whether the page has changed since the last refresh). As a point of departure, we characterise the conditions under which one can solve the problem with such partial observability. Next, we propose a practical estimator and compute confidence intervals for it in terms of the elapsed time between the observations. Finally, we show that the explore-and-commit algorithm achieves an $\mathcal{O}(\sqrt{T})$ regret with a carefully chosen exploration horizon. Our simulation study shows that our online policy scales well and achieves close to optimal performance for a wide range of the parameters.
Optimal Non-Asymptotic Lower Bound on the Minimax Regret of Learning with Expert Advice
Nov 06, 2015We prove non-asymptotic lower bounds on the expectation of the maximum of $d$ independent Gaussian variables and the expectation of the maximum of $d$ independent symmetric random walks. Both lower bounds recover the optimal leading constant in the limit. A simple application of the lower bound for random walks is an (asymptotically optimal) non-asymptotic lower bound on the minimax regret of online learning with expert advice.
Scale-Free Algorithms for Online Linear Optimization
Jul 01, 2015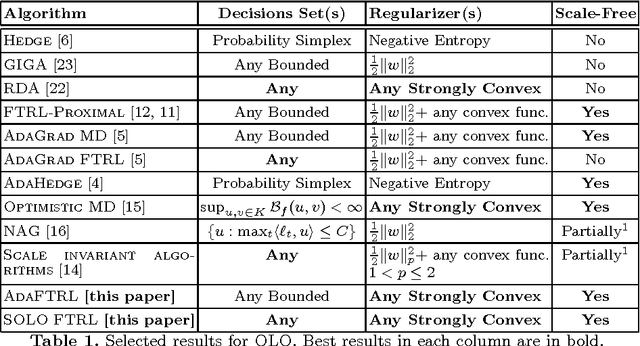
We design algorithms for online linear optimization that have optimal regret and at the same time do not need to know any upper or lower bounds on the norm of the loss vectors. We achieve adaptiveness to norms of loss vectors by scale invariance, i.e., our algorithms make exactly the same decisions if the sequence of loss vectors is multiplied by any positive constant. Our algorithms work for any decision set, bounded or unbounded. For unbounded decisions sets, these are the first truly adaptive algorithms for online linear optimization.
Online Least Squares Estimation with Self-Normalized Processes: An Application to Bandit Problems
Feb 14, 2011
The analysis of online least squares estimation is at the heart of many stochastic sequential decision making problems. We employ tools from the self-normalized processes to provide a simple and self-contained proof of a tail bound of a vector-valued martingale. We use the bound to construct a new tighter confidence sets for the least squares estimate. We apply the confidence sets to several online decision problems, such as the multi-armed and the linearly parametrized bandit problems. The confidence sets are potentially applicable to other problems such as sleeping bandits, generalized linear bandits, and other linear control problems. We improve the regret bound of the Upper Confidence Bound (UCB) algorithm of Auer et al. (2002) and show that its regret is with high-probability a problem dependent constant. In the case of linear bandits (Dani et al., 2008), we improve the problem dependent bound in the dimension and number of time steps. Furthermore, as opposed to the previous result, we prove that our bound holds for small sample sizes, and at the same time the worst case bound is improved by a logarithmic factor and the constant is improved.
Learning Low-Density Separators
Jan 22, 2009
We define a novel, basic, unsupervised learning problem - learning the lowest density homogeneous hyperplane separator of an unknown probability distribution. This task is relevant to several problems in machine learning, such as semi-supervised learning and clustering stability. We investigate the question of existence of a universally consistent algorithm for this problem. We propose two natural learning paradigms and prove that, on input unlabeled random samples generated by any member of a rich family of distributions, they are guaranteed to converge to the optimal separator for that distribution. We complement this result by showing that no learning algorithm for our task can achieve uniform learning rates (that are independent of the data generating distribution).