 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two-Timescale Reinforcement Learning with the Tightest Finite-Time Bound
Dec 04, 2019


Policy evaluation in reinforcement learning is often conducted using two-timescale stochastic approximation, which results in various gradient temporal difference methods such as GTD(0), GTD2, and TDC. Here, we provide convergence rate bounds for this suite of algorithms. Algorithms such as these have two iterates, $\theta_n$ and $w_n,$ which are updated using two distinct stepsize sequences, $\alpha_n$ and $\beta_n,$ respectively. Assuming $\alpha_n = n^{-\alpha}$ and $\beta_n = n^{-\beta}$ with $1 > \alpha > \beta > 0,$ we show that, with high probability, the two iterates converge to their respective solutions $\theta^*$ and $w^*$ at rates given by $\|\theta_n - \theta^*\| = \tilde{O}( n^{-\alpha/2})$ and $\|w_n - w^*\| = \tilde{O}(n^{-\beta/2});$ here, $\tilde{O}$ hides logarithmic terms. Via comparable lower bounds, we show that these bounds are, in fact, tight. To the best of our knowledge, ours is the first finite-time analysis which achieves these rates. While it was known that the two timescale components decouple asymptotically, our results depict this phenomenon more explicitly by showing that it in fact happens from some finite time onwards. Lastly, compared to existing works, our result applies to a broader family of stepsizes, including non-square summable ones.
Learning to Crawl
May 29, 2019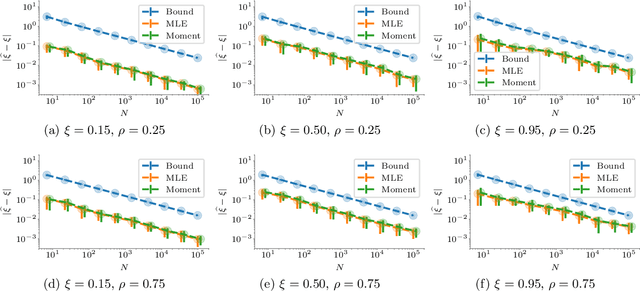
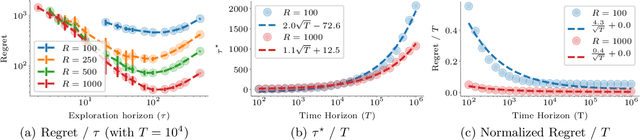
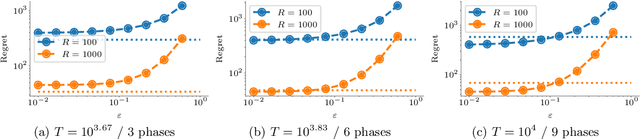
Web crawling is the problem of keeping a cache of webpages fresh, i.e., having the most recent copy available when a page is requested. This problem is usually coupled with the natural restriction that the bandwidth available to the web crawler is limited. The corresponding optimization problem was solved optimally by Azar et al. [2018] under the assumption that, for each webpage, both the elapsed time between two changes and the elapsed time between two requests follow a Poisson distribution with known parameters. In this paper, we study the same control problem but under the assumption that the change rates are unknown a priori, and thus we need to estimate them in an online fashion using only partial observations (i.e., single-bit signals indicating whether the page has changed since the last refresh). As a point of departure, we characterise the conditions under which one can solve the problem with such partial observability. Next, we propose a practical estimator and compute confidence intervals for it in terms of the elapsed time between the observations. Finally, we show that the explore-and-commit algorithm achieves an $\mathcal{O}(\sqrt{T})$ regret with a carefully chosen exploration horizon. Our simulation study shows that our online policy scales well and achieves close to optimal performance for a wide range of the parameters.
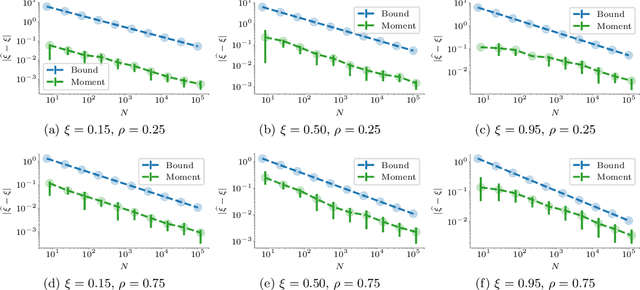
Finite Sample Analysis of Two-Timescale Stochastic Approximation with Applications to Reinforcement Learning
Jun 04, 2018

Two-timescale Stochastic Approximation (SA) algorithms are widely used in Reinforcement Learning (RL). Their iterates have two parts that are updated using distinct stepsizes. In this work, we develop a novel recipe for their finite sample analysis. Using this, we provide a concentration bound, which is the first such result for a two-timescale SA. The type of bound we obtain is known as `lock-in probability'. We also introduce a new projection scheme, in which the time between successive projections increases exponentially. This scheme allows one to elegantly transform a lock-in probability into a convergence rate result for projected two-timescale SA. From this latter result, we then extract key insights on stepsize selection. As an application, we finally obtain convergence rates for the projected two-timescale RL algorithms GTD(0), GTD2, and TDC.
Multi-objective Bandits: Optimizing the Generalized Gini Index
Jun 15, 2017
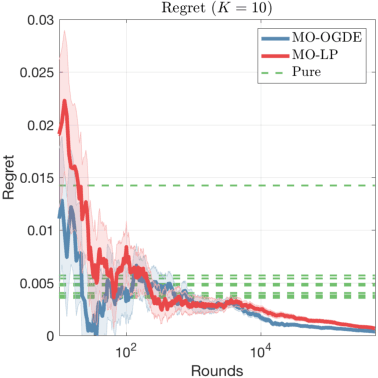
We study the multi-armed bandit (MAB) problem where the agent receives a vectorial feedback that encodes many possibly competing objectives to be optimized. The goal of the agent is to find a policy, which can optimize these objectives simultaneously in a fair way. This multi-objective online optimization problem is formalized by using the Generalized Gini Index (GGI) aggregation function. We propose an online gradient descent algorithm which exploits the convexity of the GGI aggregation function, and controls the exploration in a careful way achieving a distribution-free regret $\tilde{\bigO} (T^{-1/2} )$ with high probability. We test our algorithm on synthetic data as well as on an electric battery control problem where the goal is to trade off the use of the different cells of a battery in order to balance their respective degradation rates.
Distributed Clustering of Linear Bandits in Peer to Peer Networks
Jun 07, 2016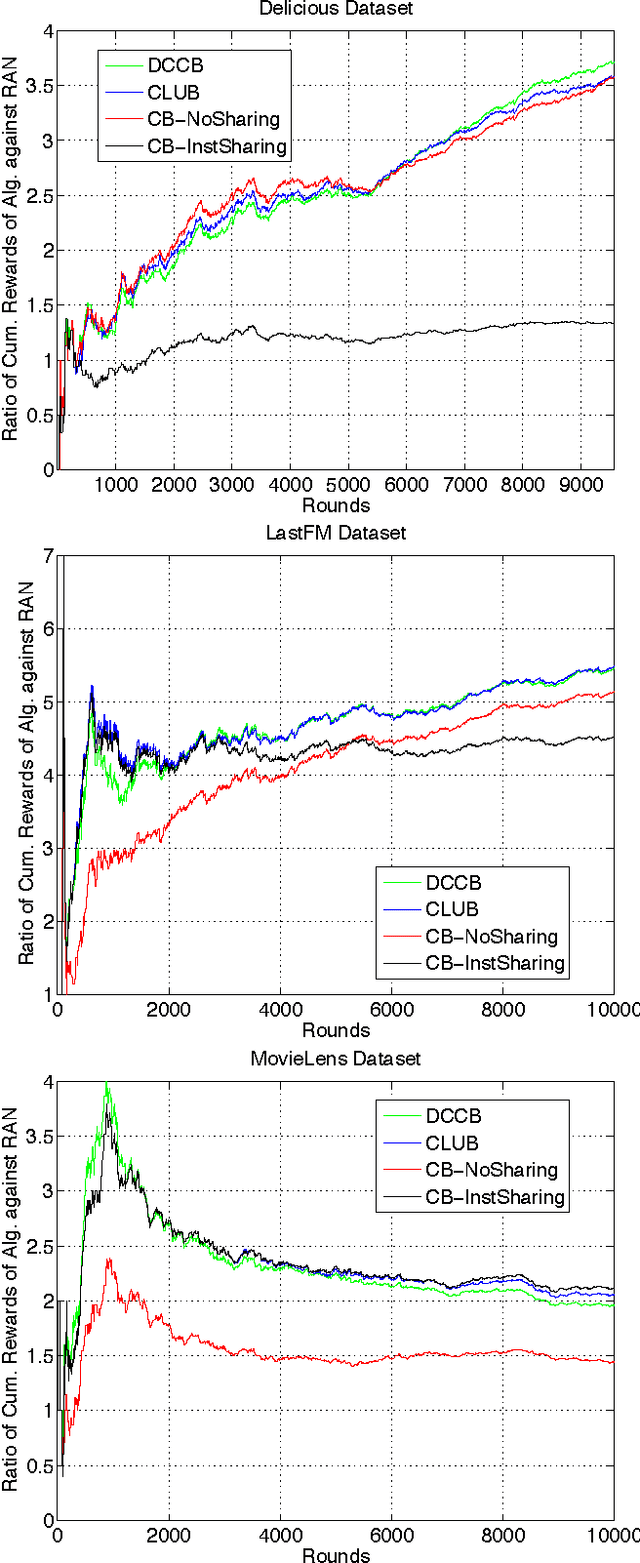
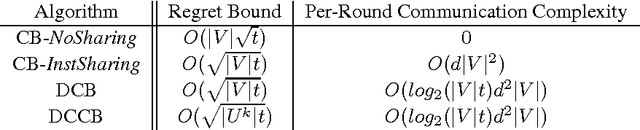
We provide two distributed confidence ball algorithms for solving linear bandit problems in peer to peer networks with limited communication capabilities. For the first, we assume that all the peers are solving the same linear bandit problem, and prove that our algorithm achieves the optimal asymptotic regret rate of any centralised algorithm that can instantly communicate information between the peers. For the second, we assume that there are clusters of peers solving the same bandit problem within each cluster, and we prove that our algorithm discovers these clusters, while achieving the optimal asymptotic regret rate within each one. Through experiments on several real-world datasets, we demonstrate the performance of proposed algorithms compared to the state-of-the-art.