 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale randomized experiment reveals machine learning helps people learn and remember more effectively
Oct 09, 2020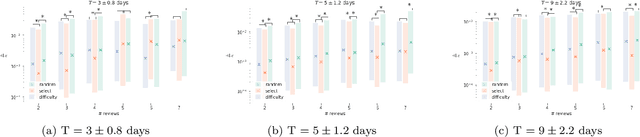
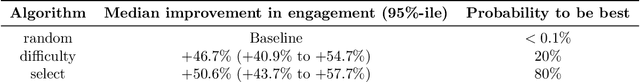
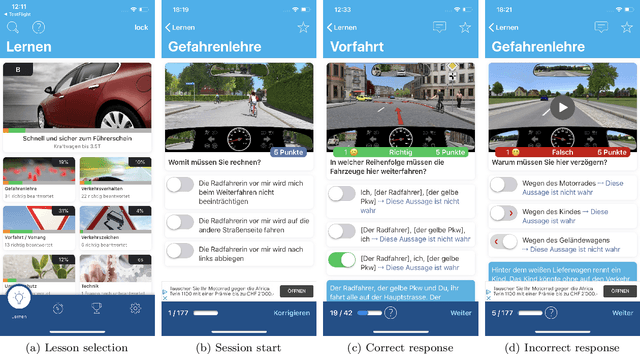

Machine learning has typically focused on developing models and algorithms that would ultimately replace humans at tasks where intelligence is required. In this work, rather than replacing humans, we focus on unveiling the potential of machine learning to improve how people learn and remember factual material. To this end, we perform a large-scale randomized controlled trial with thousands of learners from a popular learning app in the area of mobility. After controlling for the length and frequency of study, we find that learners whose study sessions are optimized using machine learning remember the content over $\sim$67% longer than those whose study sessions are generated using two alternative heuristics. Our randomized controlled trial also reveals that the learners whose study sessions are optimized using machine learning are $\sim$50% more likely to return to the app within 4-7 days.
Classification of Cuisines from Sequentially Structured Recipes
Apr 26, 2020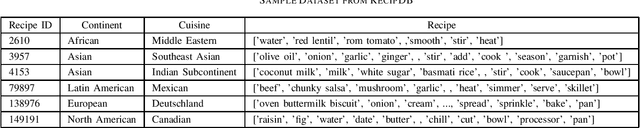
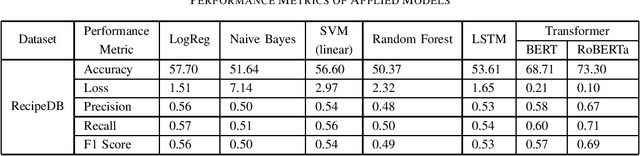
Cultures across the world are distinguished by the idiosyncratic patterns in their cuisines. These cuisines are characterized in terms of their substructures such as ingredients, cooking processes and utensils. A complex fusion of these substructures intrinsic to a region defines the identity of a cuisine. Accurate classification of cuisines based on their culinary features is an outstanding problem and has hitherto been attempted to solve by accounting for ingredients of a recipe as features. Previous studies have attempted cuisine classification by using unstructured recipes without accounting for details of cooking techniques. In reality, the cooking processes/techniques and their order are highly significant for the recipe's structure and hence for its classification. In this article, we have implemented a range of classification techniques by accounting for this information on the RecipeDB dataset containing sequential data on recipes. The state-of-the-art RoBERTa model presented the highest accuracy of 73.30% among a range of classification models from Logistic Regression and Naive Bayes to LSTMs and Transformers.
Can A User Anticipate What Her Followers Want?
Sep 19, 2019
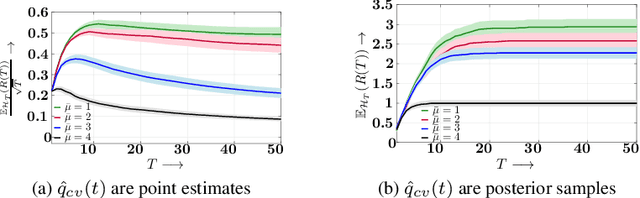
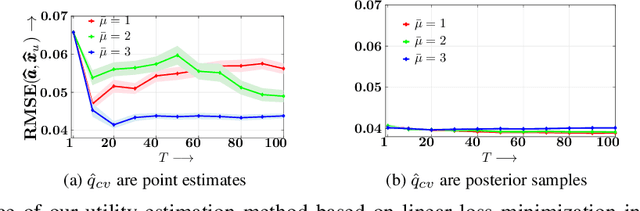
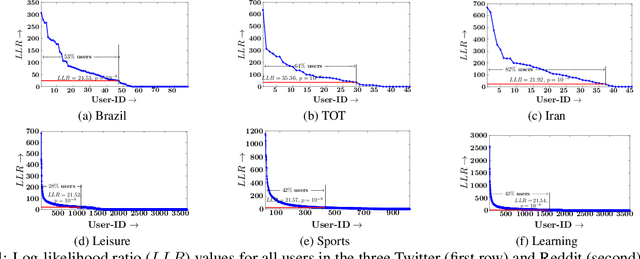
Whenever a social media user decides to share a story, she is typically pleased to receive likes, comments, shares, or, more generally, feedback from her followers. As a result, she may feel compelled to use the feedback she receives to (re-)estimate her followers' preferences and decides which stories to share next to receive more (positive) feedback. Under which conditions can she succeed? In this work, we first look into this problem from a theoretical perspective and then provide a set of practical algorithms to identify and characterize such behavior in social media. More specifically, we address the above problem from the viewpoint of sequential decision making and utility maximization. For a wide variety of utility functions, we first show that, to succeed, a user needs to actively trade off exploitation-- sharing stories which lead to more (positive) feedback--and exploration-- sharing stories to learn about her followers' preferences. However, exploration is not necessary if a user utilizes the feedback her followers provide to other users in addition to the feedback she receives. Then, we develop a utility estimation framework for observation data, which relies on statistical hypothesis testing to determine whether a user utilizes the feedback she receives from each of her followers to decide what to post next. Experiments on synthetic data illustrate our theoretical findings and show that our estimation framework is able to accurately recover users' underlying utility functions. Experiments on several real datasets gathered from Twitter and Reddit reveal that up to 82% (43%) of the Twitter (Reddit) users in our datasets do use the feedback they receive to decide what to post next.
Learning to Crawl
May 29, 2019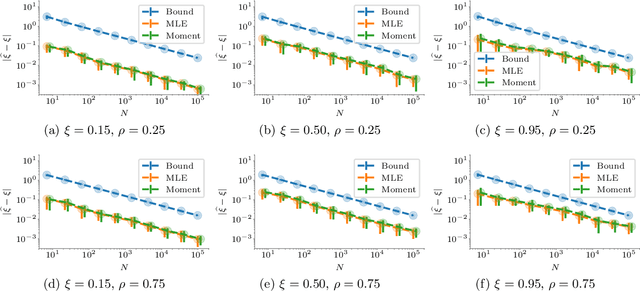
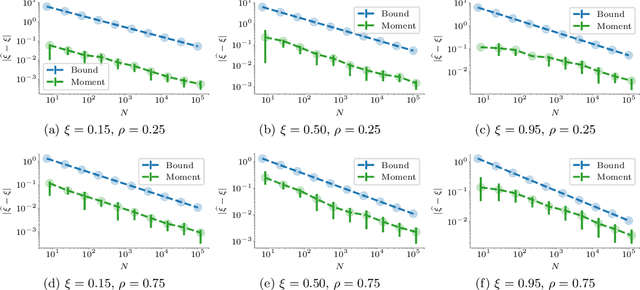
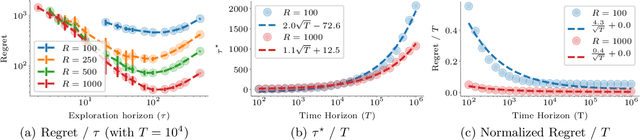
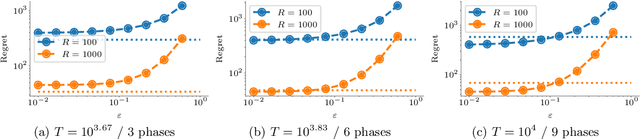
Web crawling is the problem of keeping a cache of webpages fresh, i.e., having the most recent copy available when a page is requested. This problem is usually coupled with the natural restriction that the bandwidth available to the web crawler is limited. The corresponding optimization problem was solved optimally by Azar et al. [2018] under the assumption that, for each webpage, both the elapsed time between two changes and the elapsed time between two requests follow a Poisson distribution with known parameters. In this paper, we study the same control problem but under the assumption that the change rates are unknown a priori, and thus we need to estimate them in an online fashion using only partial observations (i.e., single-bit signals indicating whether the page has changed since the last refresh). As a point of departure, we characterise the conditions under which one can solve the problem with such partial observability. Next, we propose a practical estimator and compute confidence intervals for it in terms of the elapsed time between the observations. Finally, we show that the explore-and-commit algorithm achieves an $\mathcal{O}(\sqrt{T})$ regret with a carefully chosen exploration horizon. Our simulation study shows that our online policy scales well and achieves close to optimal performance for a wide range of the parameters.
Deep Reinforcement Learning of Marked Temporal Point Processes
Nov 06, 2018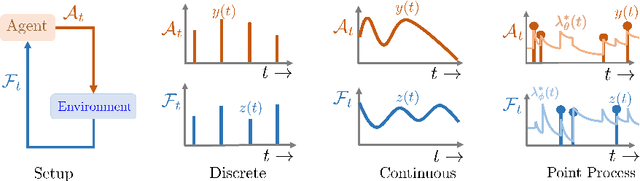

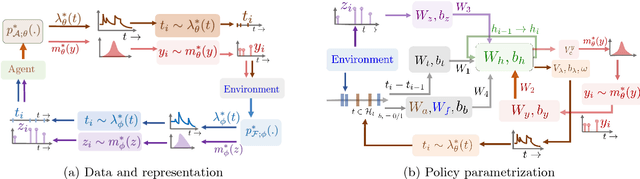
In a wide variety of applications, humans interact with a complex environment by means of asynchronous stochastic discrete events in continuous time. Can we design online interventions that will help humans achieve certain goals in such asynchronous setting? In this paper, we address the above problem from the perspective of deep reinforcement learning of marked temporal point processes, where both the actions taken by an agent and the feedback it receives from the environment are asynchronous stochastic discrete events characterized using marked temporal point processes. In doing so, we define the agent's policy using the intensity and mark distribution of the corresponding process and then derive a flexible policy gradient method, which embeds the agent's actions and the feedback it receives into real-valued vectors using deep recurrent neural networks. Our method does not make any assumptions on the functional form of the intensity and mark distribution of the feedback and it allows for arbitrarily complex reward functions. We apply our methodology to two different applications in personalized teaching and viral marketing and, using data gathered from Duolingo and Twitter, we show that it may be able to find interventions to help learners and marketers achieve their goals more effectively than alternatives.
Stochastic Optimal Control of Epidemic Processes in Networks
Oct 30, 2018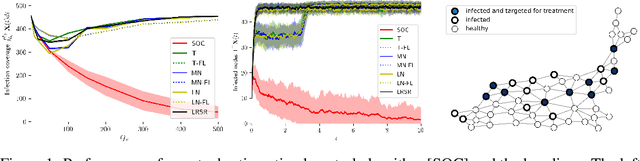
We approach the development of models and control strategies of susceptible-infected-susceptible (SIS) epidemic processes from the perspective of marked temporal point processes and stochastic optimal control of stochastic differential equations (SDEs) with jumps. In contrast to previous work, this novel perspective is particularly well-suited to make use of fine-grained data about disease outbreaks, and it lets us overcome the shortcomings of current control strategies. Our control strategy resorts to treatment intensities to determine who to treat and when to do so, to minimize the amount of infected individuals over time. Preliminary experiments with synthetic data show that our control strategy consistently outperforms several alternatives. Looking into the future, we believe our methodology provides a promising step towards the development of practical data-driven control strategies of epidemic processes.
Optimizing Human Learning
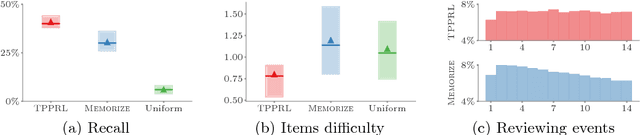
Mar 10, 2018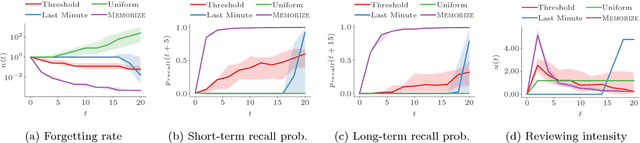
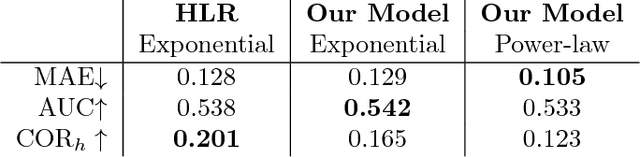

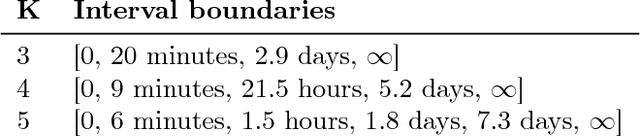
Spaced repetition is a technique for efficient memorization which uses repeated, spaced review of content to improve long-term retention. Can we find the optimal reviewing schedule to maximize the benefits of spaced repetition? In this paper, we introduce a novel, flexible representation of spaced repetition using the framework of marked temporal point processes and then address the above question as an optimal control problem for stochastic differential equations with jumps. For two well-known human memory models, we show that the optimal reviewing schedule is given by the recall probability of the content to be learned. As a result, we can then develop a simple, scalable online algorithm, Memorize, to sample the optimal reviewing times. Experiments on both synthetic and real data gathered from Duolingo, a popular language-learning online platform, show that our algorithm may be able to help learners memorize more effectively than alternatives.
On the Complexity of Opinions and Online Discussions
Feb 19, 2018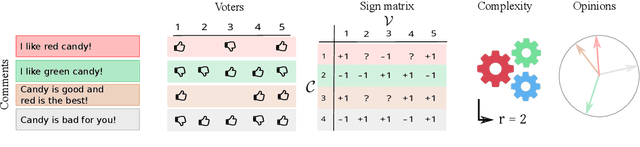
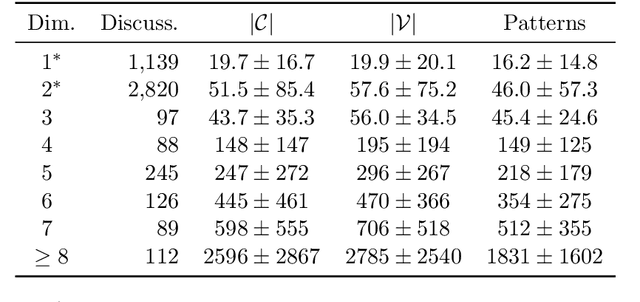
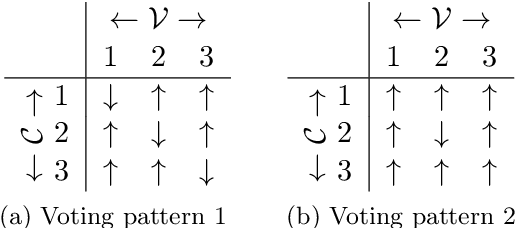
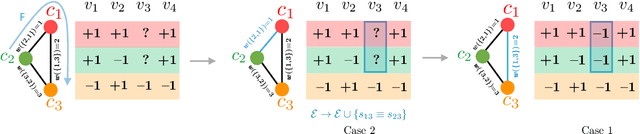
In an increasingly polarized world, demagogues who reduce complexity down to simple arguments based on emotion are gaining in popularity. Are opinions and online discussions falling into demagoguery? In this work, we aim to provide computational tools to investigate this question and, by doing so, explore the nature and complexity of online discussions and their space of opinions, uncovering where each participant lies. More specifically, we present a modeling framework to construct latent representations of opinions in online discussions which are consistent with human judgements, as measured by online voting. If two opinions are close in the resulting latent space of opinions, it is because humans think they are similar. Our modeling framework is theoretically grounded and establishes a surprising connection between opinion and voting models and the sign-rank of a matrix. Moreover, it also provides a set of practical algorithms to both estimate the dimension of the latent space of opinions and infer where opinions expressed by the participants of an online discussion lie in this space. Experiments on a large dataset from Yahoo! News, Yahoo! Finance, Yahoo! Sports, and the Newsroom app suggest that unidimensional opinion models may be often unable to accurately represent online discussions, provide insights into human judgements and opinions, and show that our framework is able to circumvent language nuances such as sarcasm or humor by relying on human judgements instead of textual analysis.
Steering Social Activity: A Stochastic Optimal Control Point Of View
Feb 19, 2018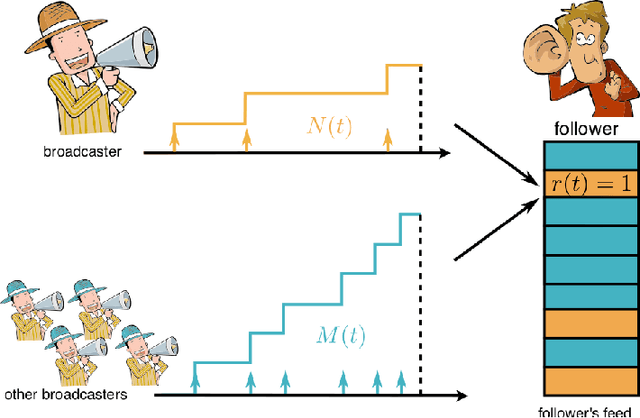
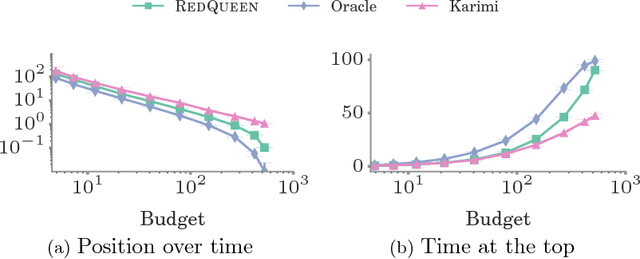
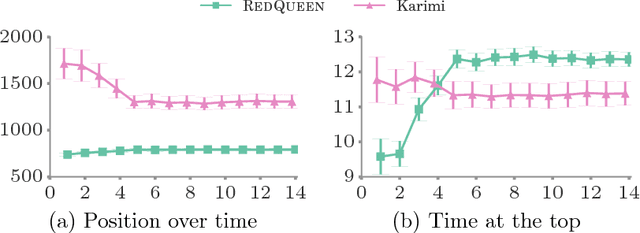
User engagement in online social networking depends critically on the level of social activity in the corresponding platform--the number of online actions, such as posts, shares or replies, taken by their users. Can we design data-driven algorithms to increase social activity? At a user level, such algorithms may increase activity by helping users decide when to take an action to be more likely to be noticed by their peers. At a network level, they may increase activity by incentivizing a few influential users to take more actions, which in turn will trigger additional actions by other users. In this paper, we model social activity using the framework of marked temporal point processes, derive an alternate representation of these processes using stochastic differential equations (SDEs) with jumps and, exploiting this alternate representation, develop two efficient online algorithms with provable guarantees to steer social activity both at a user and at a network level. In doing so, we establish a previously unexplored connection between optimal control of jump SDEs and doubly stochastic marked temporal point processes, which is of independent interest. Finally, we experiment both with synthetic and real data gathered from Twitter and show that our algorithms consistently steer social activity more effectively than the state of the art.
Uncovering the Dynamics of Crowdlearning and the Value of Knowledge
Dec 14, 2016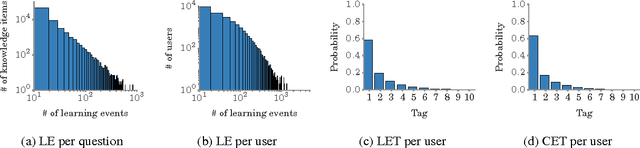
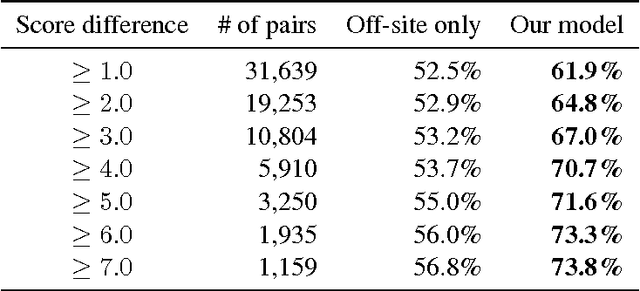
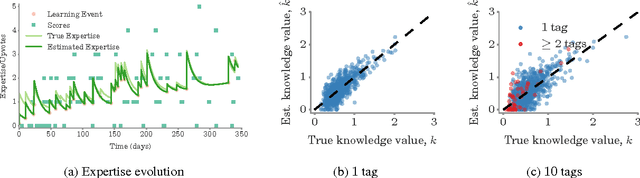
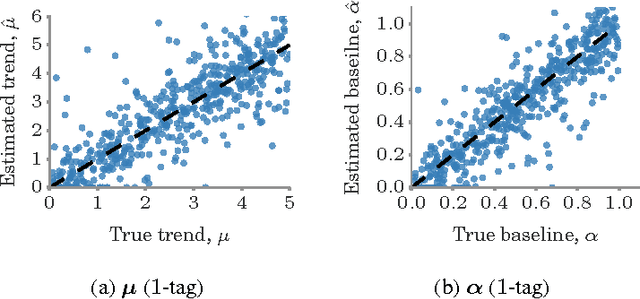
Learning from the crowd has become increasingly popular in the Web and social media. There is a wide variety of crowdlearning sites in which, on the one hand, users learn from the knowledge that other users contribute to the site, and, on the other hand, knowledge is reviewed and curated by the same users using assessment measures such as upvotes or likes. In this paper, we present a probabilistic modeling framework of crowdlearning, which uncovers the evolution of a user's expertise over time by leveraging other users' assessments of her contributions. The model allows for both off-site and on-site learning and captures forgetting of knowledge. We then develop a scalable estimation method to fit the model parameters from millions of recorded learning and contributing events. We show the effectiveness of our model by tracing activity of ~25 thousand users in Stack Overflow over a 4.5 year period. We find that answers with high knowledge value are rare. Newbies and experts tend to acquire less knowledge than users in the middle range. Prolific learners tend to be also proficient contributors that post answers with high knowledge value.