 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Digital Sous Chef -- A Comparative Study on Fine-Tuning Language Models for Recipe Generation
Aug 20, 2025We established a rigorous benchmark for text-based recipe generation, a fundamental task in natural language generation. We present a comprehensive comparative study contrasting a fine-tuned GPT-2 large (774M) model against the GPT-2 small (124M) model and traditional LSTM/RNN baselines on the 5-cuisine corpus from RecipeDB. Our key contribution is a targeted tokenization strategy that augments the vocabulary with 23 common fraction tokens and custom structural markers. This approach addresses a critical limitation of generic tokenizers by preserving essential recipe structures and precise numerical quantities, thereby enhancing domain specificity. Performance is evaluated using a comprehensive suite of seven automatic metrics spanning fluency (BLEU-4, METEOR), coherence (ROUGE-L), semantic relevance (BERTScore), and diversity. Our experiments show that the large transformer-based approach yields a >20% relative improvement in BERTScore (F1) (0.92 vs 0.72) over the best recurrent baseline, while reducing perplexity by 69.8%. We conclude with a discussion of remaining challenges, particularly regarding factual accuracy, and outline how this foundational study paves the way for integrating real-world constraints and multi-modal inputs in advanced recipe generation research.
Machine learning and natural language processing models to predict the extent of food processing
Dec 23, 2024The dramatic increase in consumption of ultra-processed food has been associated with numerous adverse health effects. Given the public health consequences linked to ultra-processed food consumption, it is highly relevant to build computational models to predict the processing of food products. We created a range of machine learning, deep learning, and NLP models to predict the extent of food processing by integrating the FNDDS dataset of food products and their nutrient profiles with their reported NOVA processing level. Starting with the full nutritional panel of 102 features, we further implemented coarse-graining of features to 65 and 13 nutrients by dropping flavonoids and then by considering the 13-nutrient panel of FDA, respectively. LGBM Classifier and Random Forest emerged as the best model for 102 and 65 nutrients, respectively, with an F1-score of 0.9411 and 0.9345 and MCC of 0.8691 and 0.8543. For the 13-nutrient panel, Gradient Boost achieved the best F1-score of 0.9284 and MCC of 0.8425. We also implemented NLP based models, which exhibited state-of-the-art performance. Besides distilling nutrients critical for model performance, we present a user-friendly web server for predicting processing level based on the nutrient panel of a food product: https://cosylab.iiitd.edu.in/food-processing/.
Deep Learning Based Named Entity Recognition Models for Recipes
Feb 27, 2024
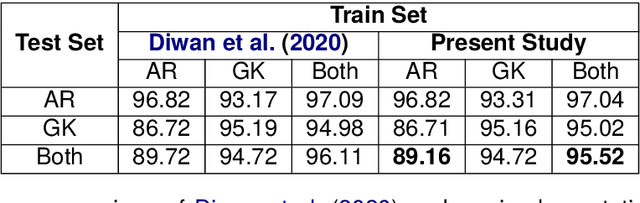


Food touches our lives through various endeavors, including flavor, nourishment, health, and sustainability. Recipes are cultural capsules transmitted across generations via unstructured text. Automated protocols for recognizing named entities, the building blocks of recipe text, are of immense value for various applications ranging from information extraction to novel recipe generation. Named entity recognition is a technique for extracting information from unstructured or semi-structured data with known labels. Starting with manually-annotated data of 6,611 ingredient phrases, we created an augmented dataset of 26,445 phrases cumulatively. Simultaneously, we systematically cleaned and analyzed ingredient phrases from RecipeDB, the gold-standard recipe data repository, and annotated them using the Stanford NER. Based on the analysis, we sampled a subset of 88,526 phrases using a clustering-based approach while preserving the diversity to create the machine-annotated dataset. A thorough investigation of NER approaches on these three datasets involving statistical, fine-tuning of deep learning-based language models and few-shot prompting on large language models (LLMs) provides deep insights. We conclude that few-shot prompting on LLMs has abysmal performance, whereas the fine-tuned spaCy-transformer emerges as the best model with macro-F1 scores of 95.9%, 96.04%, and 95.71% for the manually-annotated, augmented, and machine-annotated datasets, respectively.
Dish detection in food platters: A framework for automated diet logging and nutrition management
May 12, 2023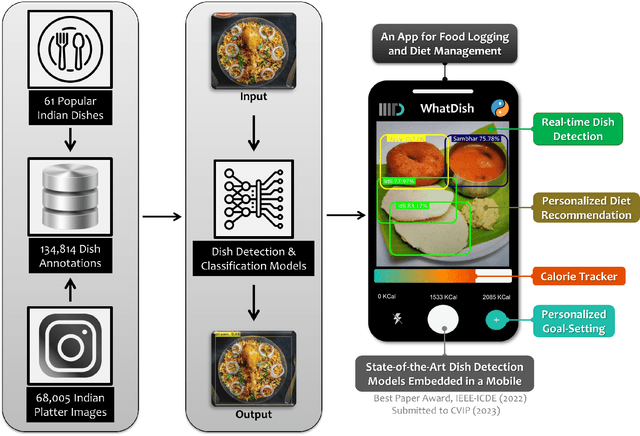

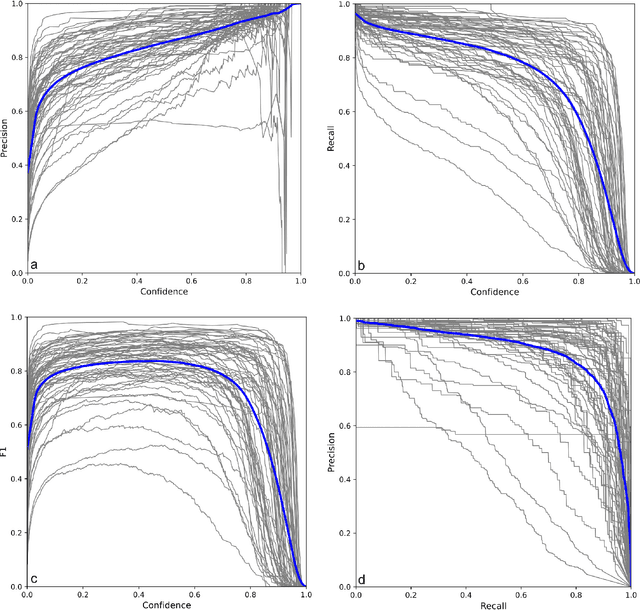
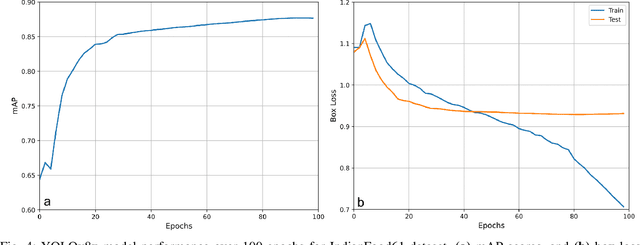
Diet is central to the epidemic of lifestyle disorders. Accurate and effortless diet logging is one of the significant bottlenecks for effective diet management and calorie restriction. Dish detection from food platters is a challenging problem due to a visually complex food layout. We present an end-to-end computational framework for diet management, from data compilation, annotation, and state-of-the-art model identification to its mobile app implementation. As a case study, we implement the framework in the context of Indian food platters known for their complex presentation that poses a challenge for the automated detection of dishes. Starting with the 61 most popular Indian dishes, we identify the state-of-the-art model through a comparative analysis of deep-learning-based object detection architectures. Rooted in a meticulous compilation of 68,005 platter images with 134,814 manual dish annotations, we first compare ten architectures for multi-label classification to identify ResNet152 (mAP=84.51%) as the best model. YOLOv8x (mAP=87.70%) emerged as the best model architecture for dish detection among the eight deep-learning models implemented after a thorough performance evaluation. By comparing with the state-of-the-art model for the IndianFood10 dataset, we demonstrate the superior object detection performance of YOLOv8x for this subset and establish Resnet152 as the best architecture for multi-label classification. The models thus trained on richly annotated data can be extended to include dishes from across global cuisines. The proposed framework is demonstrated through a proof-of-concept mobile application with diverse applications for diet logging, food recommendation systems, nutritional interventions, and mitigation of lifestyle disorders.
Object Detection in Indian Food Platters using Transfer Learning with YOLOv4
May 10, 2022
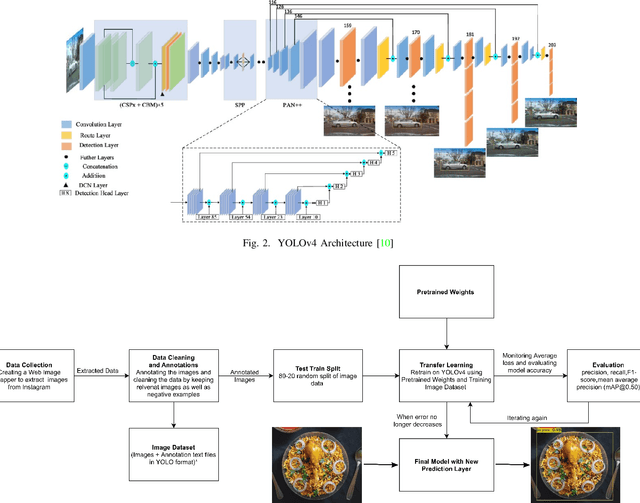

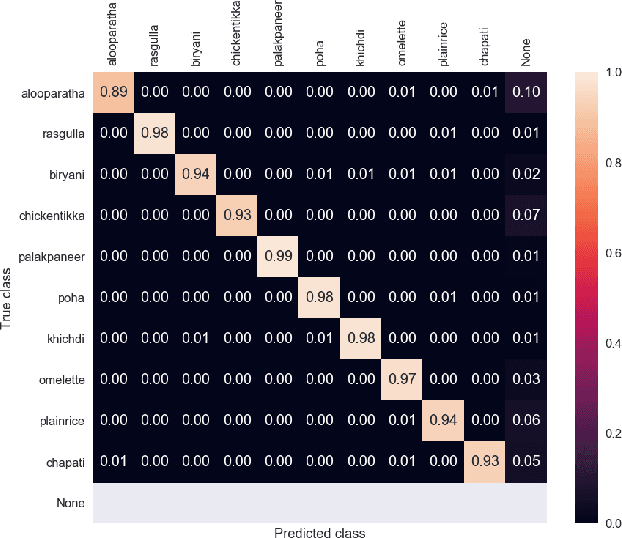
Object detection is a well-known problem in computer vision. Despite this, its usage and pervasiveness in the traditional Indian food dishes has been limited. Particularly, recognizing Indian food dishes present in a single photo is challenging due to three reasons: 1. Lack of annotated Indian food datasets 2. Non-distinct boundaries between the dishes 3. High intra-class variation. We solve these issues by providing a comprehensively labelled Indian food dataset- IndianFood10, which contains 10 food classes that appear frequently in a staple Indian meal and using transfer learning with YOLOv4 object detector model. Our model is able to achieve an overall mAP score of 91.8% and f1-score of 0.90 for our 10 class dataset. We also provide an extension of our 10 class dataset- IndianFood20, which contains 10 more traditional Indian food classes.
Classification of Cuisines from Sequentially Structured Recipes
Apr 26, 2020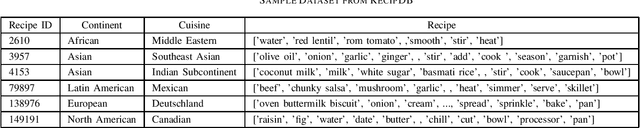
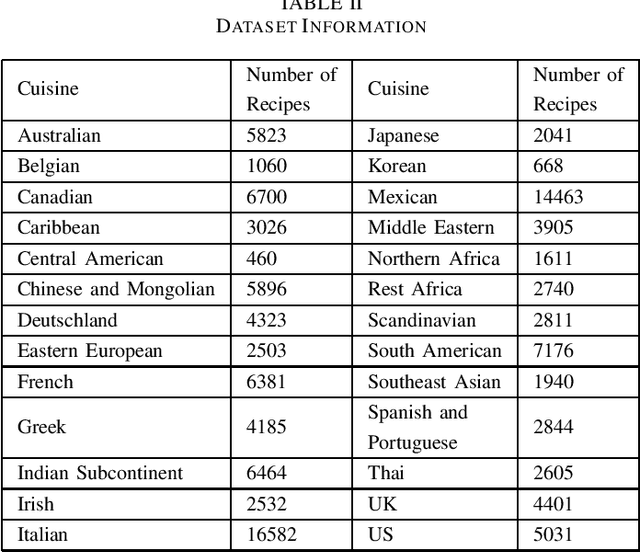
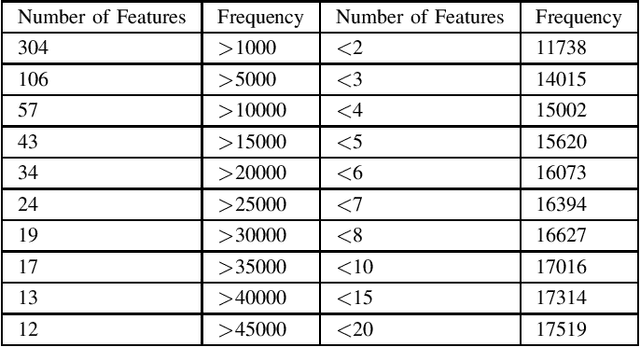
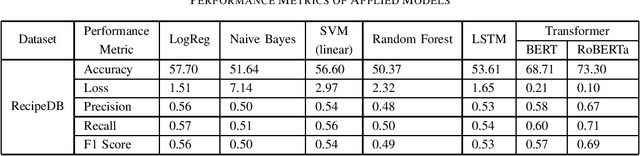
Cultures across the world are distinguished by the idiosyncratic patterns in their cuisines. These cuisines are characterized in terms of their substructures such as ingredients, cooking processes and utensils. A complex fusion of these substructures intrinsic to a region defines the identity of a cuisine. Accurate classification of cuisines based on their culinary features is an outstanding problem and has hitherto been attempted to solve by accounting for ingredients of a recipe as features. Previous studies have attempted cuisine classification by using unstructured recipes without accounting for details of cooking techniques. In reality, the cooking processes/techniques and their order are highly significant for the recipe's structure and hence for its classification. In this article, we have implemented a range of classification techniques by accounting for this information on the RecipeDB dataset containing sequential data on recipes. The state-of-the-art RoBERTa model presented the highest accuracy of 73.30% among a range of classification models from Logistic Regression and Naive Bayes to LSTMs and Transformers.
A Named Entity Based Approach to Model Recipes
Apr 25, 2020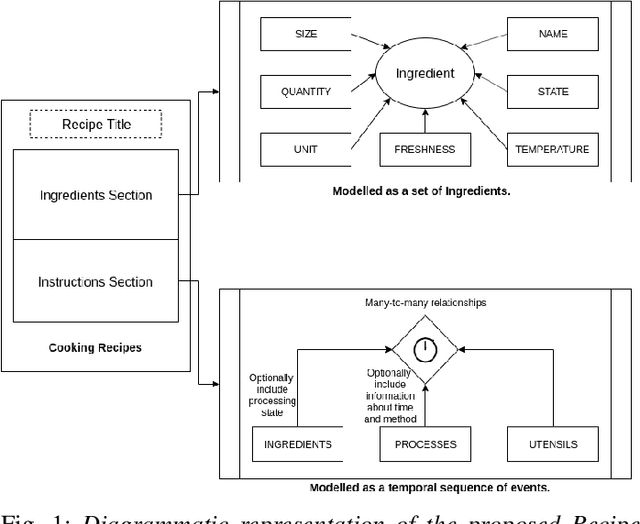
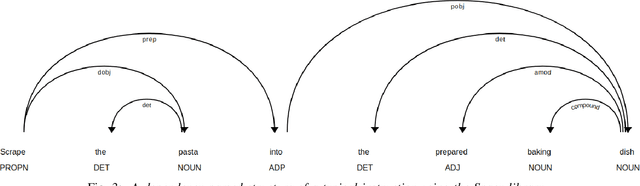
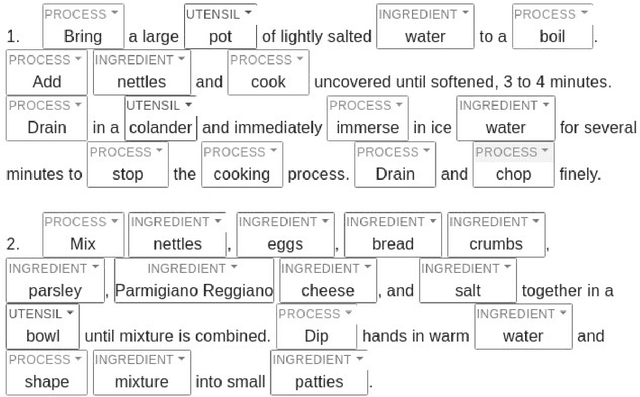
Traditional cooking recipes follow a structure which can be modelled very well if the rules and semantics of the different sections of the recipe text are analyzed and represented accurately. We propose a structure that can accurately represent the recipe as well as a pipeline to infer the best representation of the recipe in this uniform structure. The Ingredients section in a recipe typically lists down the ingredients required and corresponding attributes such as quantity, temperature, and processing state. This can be modelled by defining these attributes and their values. The physical entities which make up a recipe can be broadly classified into utensils, ingredients and their combinations that are related by cooking techniques. The instruction section lists down a series of events in which a cooking technique or process is applied upon these utensils and ingredients. We model these relationships in the form of tuples. Thus, using a combination of these methods we model cooking recipe in the dataset RecipeDB to show the efficacy of our method. This mined information model can have several applications which include translating recipes between languages, determining similarity between recipes, generation of novel recipes and estimation of the nutritional profile of recipes. For the purpose of recognition of ingredient attributes, we train the Named Entity Relationship (NER) models and analyze the inferences with the help of K-Means clustering. Our model presented with an F1 score of 0.95 across all datasets. We use a similar NER tagging model for labelling cooking techniques (F1 score = 0.88) and utensils (F1 score = 0.90) within the instructions section. Finally, we determine the temporal sequence of relationships between ingredients, utensils and cooking techniques for modeling the instruction steps.