 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Permutation-Aware Modeling for Temporal Set Prediction
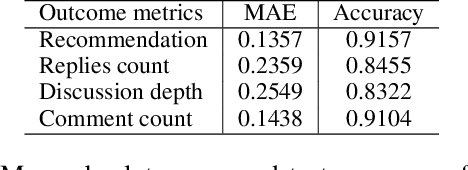
Apr 23, 2025Temporal set prediction involves forecasting the elements that will appear in the next set, given a sequence of prior sets, each containing a variable number of elements. Existing methods often rely on intricate architectures with substantial computational overhead, which hampers their scalability. In this work, we introduce a novel and scalable framework that leverages permutation-equivariant and permutation-invariant transformations to efficiently model set dynamics. Our approach significantly reduces both training and inference time while maintaining competitive performance. Extensive experiments on multiple public benchmarks show that our method achieves results on par with or superior to state-of-the-art models across several evaluation metrics. These results underscore the effectiveness of our model in enabling efficient and scalable temporal set prediction.
Biometrics in Extended Reality: A Review
Nov 14, 2024In the domain of Extended Reality (XR), particularly Virtual Reality (VR), extensive research has been devoted to harnessing this transformative technology in various real-world applications. However, a critical challenge that must be addressed before unleashing the full potential of XR in practical scenarios is to ensure robust security and safeguard user privacy. This paper presents a systematic survey of the utility of biometric characteristics applied in the XR environment. To this end, we present a comprehensive overview of the different types of biometric modalities used for authentication and representation of users in a virtual environment. We discuss different biometric vulnerability gateways in general XR systems for the first time in the literature along with taxonomy. A comprehensive discussion on generating and authenticating biometric-based photorealistic avatars in XR environments is presented with a stringent taxonomy. We also discuss the availability of different datasets that are widely employed in evaluating biometric authentication in XR environments together with performance evaluation metrics. Finally, we discuss the open challenges and potential future work that need to be addressed in the field of biometrics in XR.
RiskSEA : A Scalable Graph Embedding for Detecting On-chain Fraudulent Activities on the Ethereum Blockchain
Oct 03, 2024



Like any other useful technology, cryptocurrencies are sometimes used for criminal activities. While transactions are recorded on the blockchain, there exists a need for a more rapid and scalable method to detect addresses associated with fraudulent activities. We present RiskSEA, a scalable risk scoring system capable of effectively handling the dynamic nature of large-scale blockchain transaction graphs. The risk scoring system, which we implement for Ethereum, consists of 1. a scalable approach to generating node2vec embedding for entire set of addresses to capture the graph topology 2. transaction-based features to capture the transactional behavioral pattern of an address 3. a classifier model to generate risk score for addresses that combines the node2vec embedding and behavioral features. Efficiently generating node2vec embedding for large scale and dynamically evolving blockchain transaction graphs is challenging, we present two novel approaches for generating node2vec embeddings and effectively scaling it to the entire set of blockchain addresses: 1. node2vec embedding propagation and 2. dynamic node2vec embedding. We present a comprehensive analysis of the proposed approaches. Our experiments show that combining both behavioral and node2vec features boosts the classification performance significantly, and that the dynamic node2vec embeddings perform better than the node2vec propagated embeddings.
Deep Learning Based Named Entity Recognition Models for Recipes
Feb 27, 2024
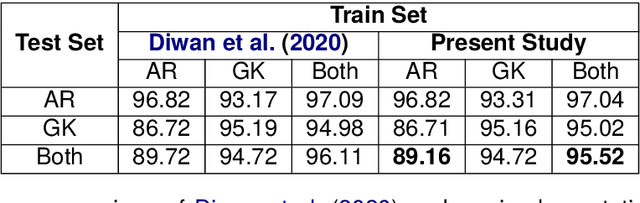


Food touches our lives through various endeavors, including flavor, nourishment, health, and sustainability. Recipes are cultural capsules transmitted across generations via unstructured text. Automated protocols for recognizing named entities, the building blocks of recipe text, are of immense value for various applications ranging from information extraction to novel recipe generation. Named entity recognition is a technique for extracting information from unstructured or semi-structured data with known labels. Starting with manually-annotated data of 6,611 ingredient phrases, we created an augmented dataset of 26,445 phrases cumulatively. Simultaneously, we systematically cleaned and analyzed ingredient phrases from RecipeDB, the gold-standard recipe data repository, and annotated them using the Stanford NER. Based on the analysis, we sampled a subset of 88,526 phrases using a clustering-based approach while preserving the diversity to create the machine-annotated dataset. A thorough investigation of NER approaches on these three datasets involving statistical, fine-tuning of deep learning-based language models and few-shot prompting on large language models (LLMs) provides deep insights. We conclude that few-shot prompting on LLMs has abysmal performance, whereas the fine-tuned spaCy-transformer emerges as the best model with macro-F1 scores of 95.9%, 96.04%, and 95.71% for the manually-annotated, augmented, and machine-annotated datasets, respectively.
CaM-Gen:Causally-aware Metric-guided Text Generation
Oct 24, 2020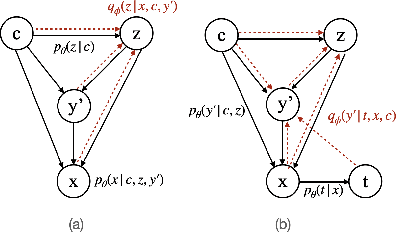
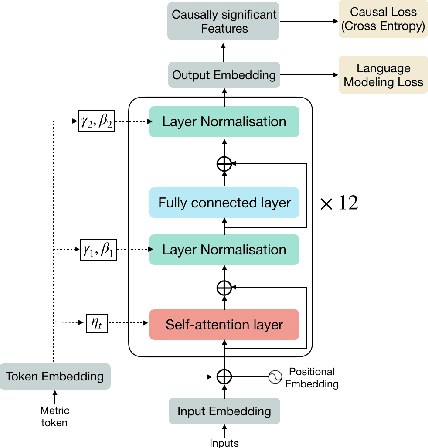
Content is created for a well-defined purpose, often described by a metric or a signal represented in the form of structured information. The relationship between the metrics or the goal of a target content and the content itself are non-trivial. While large scale language models show promising text generation capabilities, guiding and informing the generated text with external metrics is challenging. These metrics and the content tend to have inherent relationships and not all of them may directly impact the content. We introduce a CaM-Gen: Causally-aware Generative Networks guided by user-defined input metrics incorporating the causal relationships between the metric and the content features. We leverage causal inference techniques to identify the causally significant aspects of text that leads to the target metric and then explicitly guide the generative model towards these by a feedback mechanism. We propose this mechanism for variational autoencoder-based and transformer-based generative models. The proposed models beat baselines in terms of the target metric accuracy while maintaining the fluency and the language quality of the generated text. To the best of our knowledge, this is one of the early attempts at incorporating a metric-guide using causal inference towards controlled generation.
RGait-NET: An Effective Network for Recovering Missing Information from Occluded Gait Cycles
Jan 20, 2020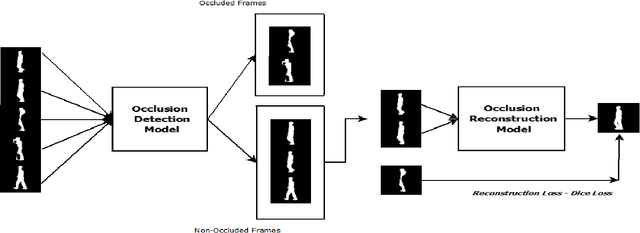
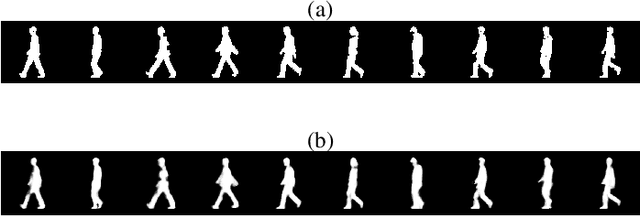
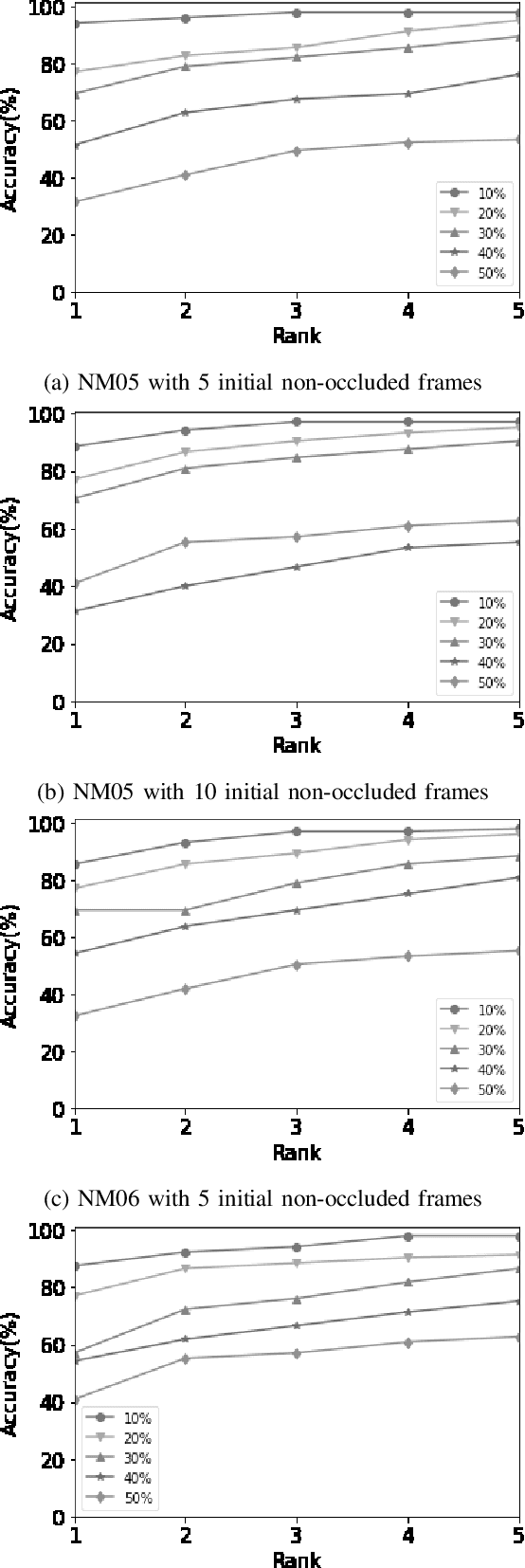
Gait of a person refers to his/her walking pattern, and according to medical studies gait of every individual is unique. Over the past decade, several computer vision-based gait recognition approaches have been proposed in which walking information corresponding to a complete gait cycle has been used to construct gait features for person identification. These methods compute gait features with the inherent assumption that a complete gait cycle is always available. However, in most public places occlusion is an inevitable occurrence, and due to this, only a fraction of a gait cycle gets captured by the monitoring camera. Unavailability of complete gait cycle information drastically affects the accuracy of the extracted features, and till date, only a few occlusion handling strategies to gait recognition have been proposed. But none of these performs reliably and robustly in the presence of a single cycle with incomplete information, and because of this practical application of gait recognition is quite limited. In this work, we develop deep learning-based algorithm to accurately identify the affected frames as well as predict the missing frames to reconstruct a complete gait cycle. While occlusion detection has been carried out by employing a VGG-16 model, the model for frame reconstruction is based on Long-Short Term Memory network that has been trained to optimize a multi-objective function based on dice coefficient and cross-entropy loss. The effectiveness of the proposed occlusion reconstruction algorithm is evaluated by computing the accuracy of the popular Gait Energy Feature on the reconstructed sequence. Experimental evaluation on public data sets and comparative analysis with other occlusion handling methods verify the effectiveness of our approach.
Unsupervised Histopathology Image Synthesis
Dec 13, 2017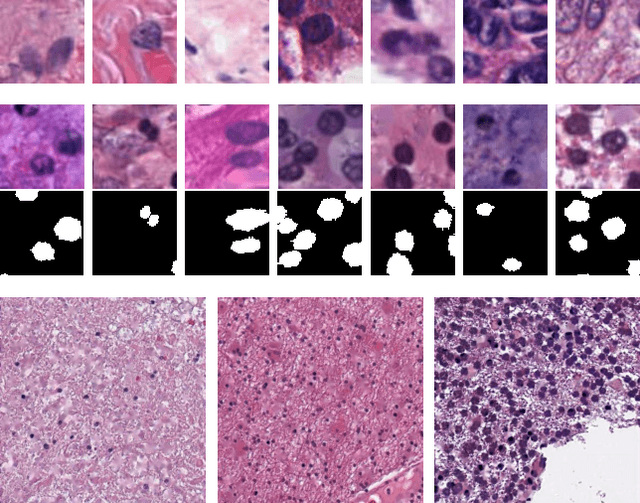
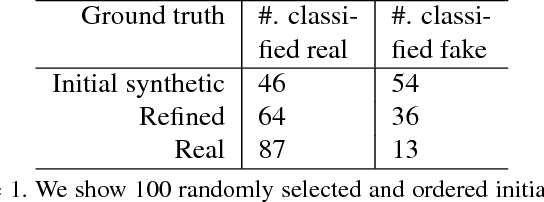
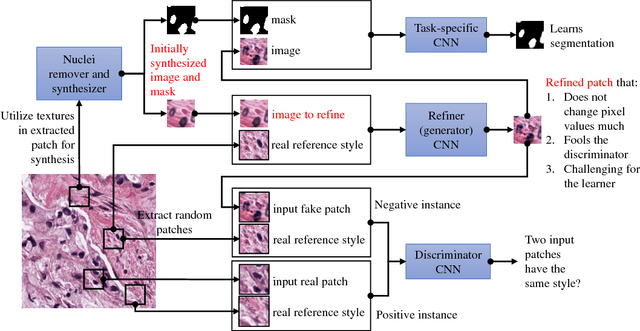
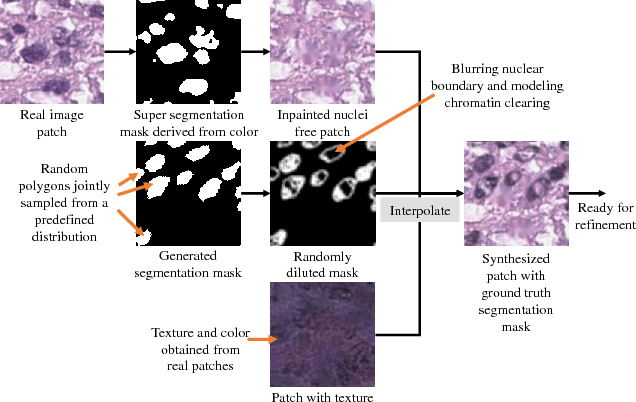
Hematoxylin and Eosin stained histopathology image analysis is essential for the diagnosis and study of complicated diseases such as cancer. Existing state-of-the-art approaches demand extensive amount of supervised training data from trained pathologists. In this work we synthesize in an unsupervised manner, large histopathology image datasets, suitable for supervised training tasks. We propose a unified pipeline that: a) generates a set of initial synthetic histopathology images with paired information about the nuclei such as segmentation masks; b) refines the initial synthetic images through a Generative Adversarial Network (GAN) to reference styles; c) trains a task-specific CNN and boosts the performance of the task-specific CNN with on-the-fly generated adversarial examples. Our main contribution is that the synthetic images are not only realistic, but also representative (in reference styles) and relatively challenging for training task-specific CNNs. We test our method for nucleus segmentation using images from four cancer types. When no supervised data exists for a cancer type, our method without supervision cost significantly outperforms supervised methods which perform across-cancer generalization. Even when supervised data exists for all cancer types, our approach without supervision cost performs better than supervised methods.