 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSKIPNet: Spatial Attention Skip Connections for Enhanced Brain Tumor Classification
Dec 10, 2024Early detection of brain tumors through magnetic resonance imaging (MRI) is essential for timely treatment, yet access to diagnostic facilities remains limited in remote areas. Gliomas, the most common primary brain tumors, arise from the carcinogenesis of glial cells in the brain and spinal cord, with glioblastoma patients having a median survival time of less than 14 months. MRI serves as a non-invasive and effective method for tumor detection, but manual segmentation of brain MRI scans has traditionally been a labor-intensive task for neuroradiologists. Recent advancements in computer-aided design (CAD), machine learning (ML), and deep learning (DL) offer promising solutions for automating this process. This study proposes an automated deep learning model for brain tumor detection and classification using MRI data. The model, incorporating spatial attention, achieved 96.90% accuracy, enhancing the aggregation of contextual information for better pattern recognition. Experimental results demonstrate that the proposed approach outperforms baseline models, highlighting its robustness and potential for advancing automated MRI-based brain tumor analysis.
Gait Cycle Reconstruction and Human Identification from Occluded Sequences
Jun 20, 2022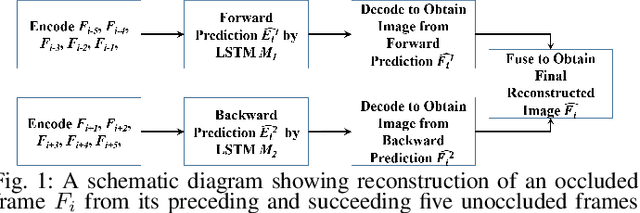
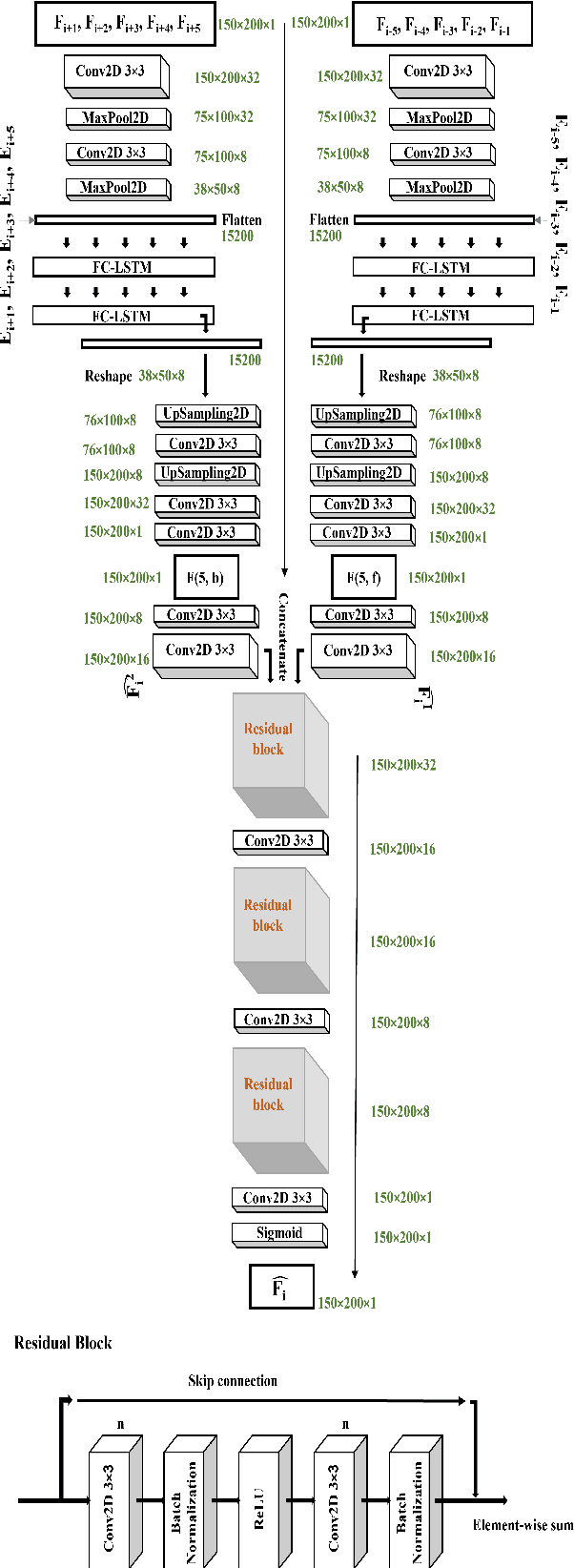
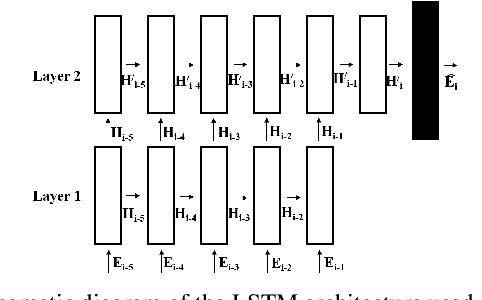

Gait-based person identification from videos captured at surveillance sites using Computer Vision-based techniques is quite challenging since these walking sequences are usually corrupted with occlusion, and a complete cycle of gait is not always available. In this work, we propose an effective neural network-based model to reconstruct the occluded frames in an input sequence before carrying out gait recognition. Specifically, we employ LSTM networks to predict an embedding for each occluded frame both from the forward and the backward directions, and next fuse the predictions from the two LSTMs by employing a network of residual blocks and convolutional layers. While the LSTMs are trained to minimize the mean-squared loss, the fusion network is trained to optimize the pixel-wise cross-entropy loss between the ground-truth and the reconstructed samples. Evaluation of our approach has been done using synthetically occluded sequences generated from the OU-ISIR LP and CASIA-B data and real-occluded sequences present in the TUM-IITKGP data. The effectiveness of the proposed reconstruction model has been verified through the Dice score and gait-based recognition accuracy using some popular gait recognition methods. Comparative study with existing occlusion handling methods in gait recognition highlights the superiority of our proposed occlusion reconstruction approach over the others.
An Improved Deep Learning Approach For Product Recognition on Racks in Retail Stores
Feb 26, 2022

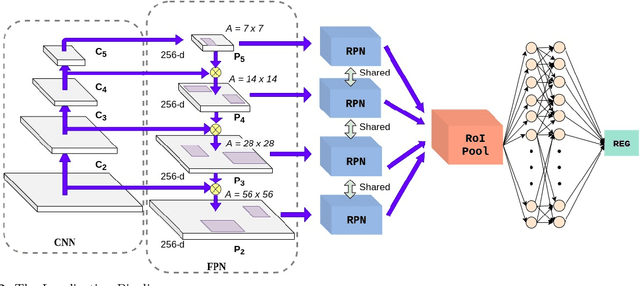

Automated product recognition in retail stores is an important real-world application in the domain of Computer Vision and Pattern Recognition. In this paper, we consider the problem of automatically identifying the classes of the products placed on racks in retail stores from an image of the rack and information about the query/product images. We improve upon the existing approaches in terms of effectiveness and memory requirement by developing a two-stage object detection and recognition pipeline comprising of a Faster-RCNN-based object localizer that detects the object regions in the rack image and a ResNet-18-based image encoder that classifies the detected regions into the appropriate classes. Each of the models is fine-tuned using appropriate data sets for better prediction and data augmentation is performed on each query image to prepare an extensive gallery set for fine-tuning the ResNet-18-based product recognition model. This encoder is trained using a triplet loss function following the strategy of online-hard-negative-mining for improved prediction. The proposed models are lightweight and can be connected in an end-to-end manner during deployment for automatically identifying each product object placed in a rack image. Extensive experiments using Grozi-32k and GP-180 data sets verify the effectiveness of the proposed model.
Exploiting Temporal Attention Features for Effective Denoising in Videos
Aug 27, 2020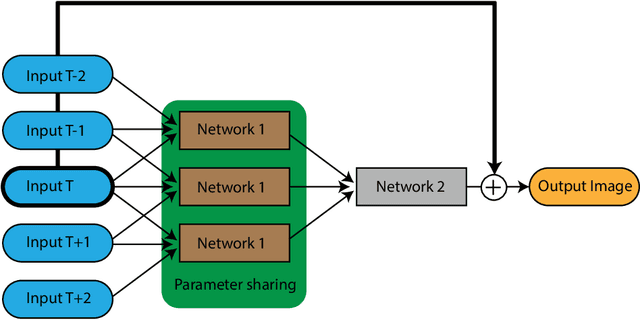

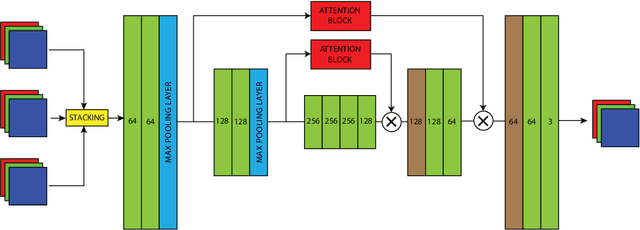
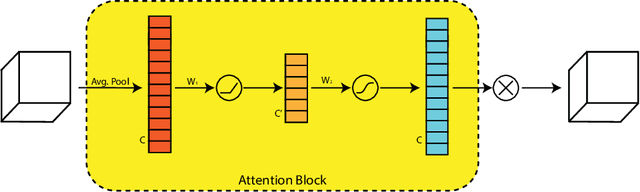
Video Denoising is one of the fundamental tasks of any videoprocessing pipeline. It is different from image denoising due to the tem-poral aspects of video frames, and any image denoising approach appliedto videos will result in flickering. The proposed method makes use oftemporal as well as spatial dimensions of video frames as part of a two-stage pipeline. Each stage in the architecture named as Spatio-TemporalNetwork uses a channel-wise attention mechanism to forward the encodersignal to the decoder side. The Attention Block used in this paper usessoft attention to ranks the filters for better training.
Deep Learning based Person Re-identification
May 07, 2020
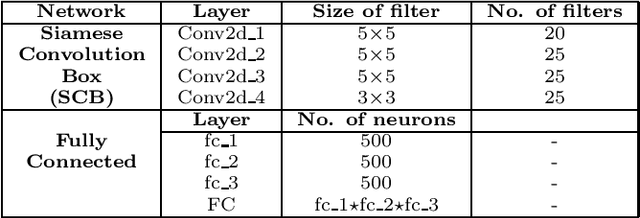
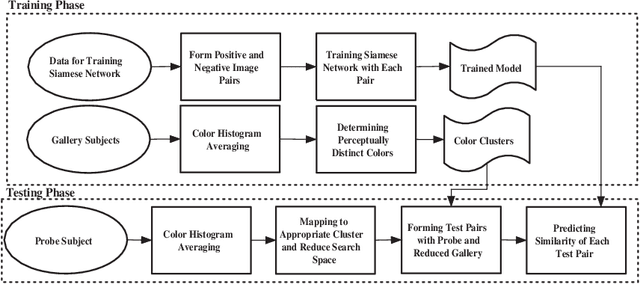

Automated person re-identification in a multi-camera surveillance setup is very important for effective tracking and monitoring crowd movement. In the recent years, few deep learning based re-identification approaches have been developed which are quite accurate but time-intensive, and hence not very suitable for practical purposes. In this paper, we propose an efficient hierarchical re-identification approach in which color histogram based comparison is first employed to find the closest matches in the gallery set, and next deep feature based comparison is carried out using Siamese network. Reduction in search space after the first level of matching helps in achieving a fast response time as well as improving the accuracy of prediction by the Siamese network by eliminating vastly dissimilar elements. A silhouette part-based feature extraction scheme is adopted in each level of hierarchy to preserve the relative locations of the different body structures and make the appearance descriptors more discriminating in nature. The proposed approach has been evaluated on five public data sets and also a new data set captured by our team in our laboratory. Results reveal that it outperforms most state-of-the-art approaches in terms of overall accuracy.
RGait-NET: An Effective Network for Recovering Missing Information from Occluded Gait Cycles
Jan 20, 2020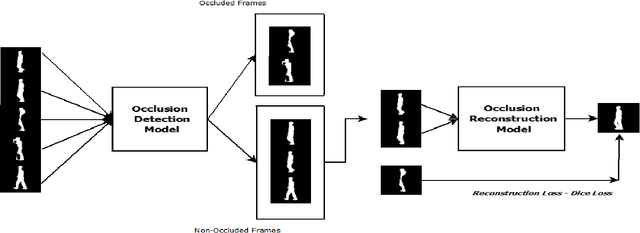
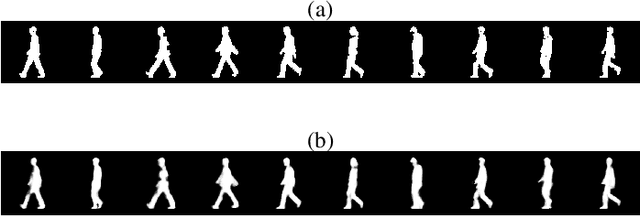
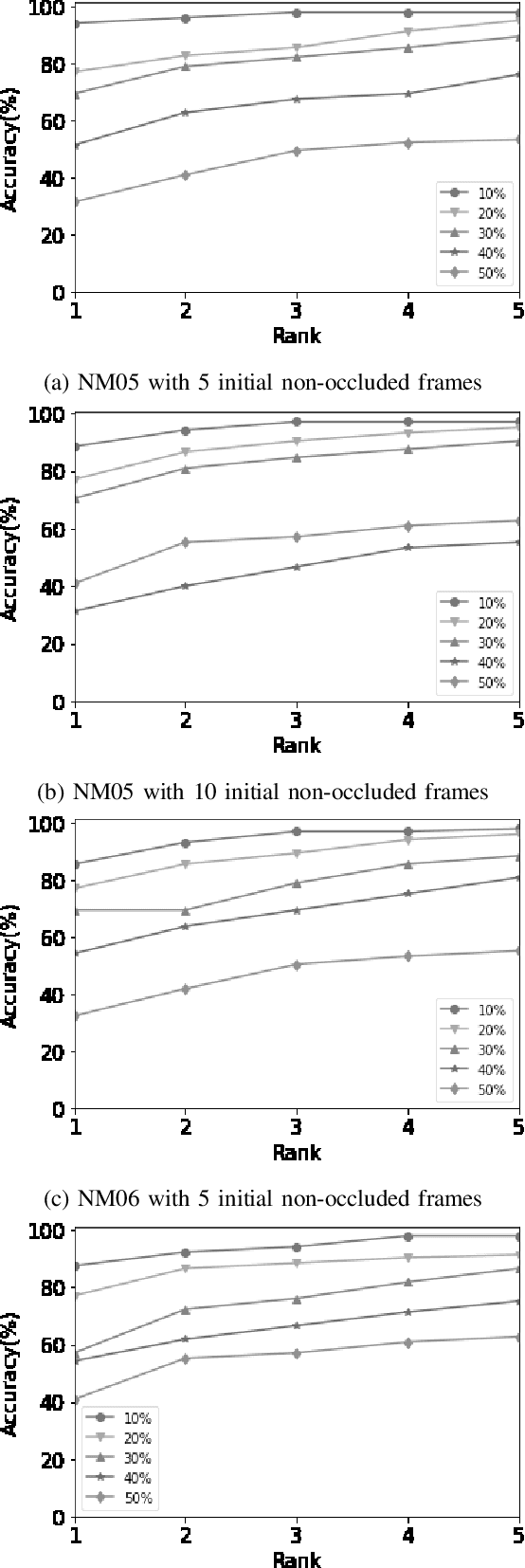
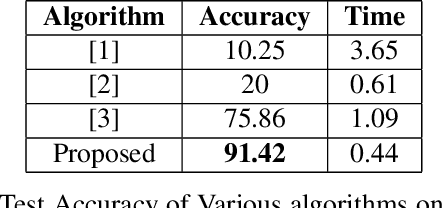
Gait of a person refers to his/her walking pattern, and according to medical studies gait of every individual is unique. Over the past decade, several computer vision-based gait recognition approaches have been proposed in which walking information corresponding to a complete gait cycle has been used to construct gait features for person identification. These methods compute gait features with the inherent assumption that a complete gait cycle is always available. However, in most public places occlusion is an inevitable occurrence, and due to this, only a fraction of a gait cycle gets captured by the monitoring camera. Unavailability of complete gait cycle information drastically affects the accuracy of the extracted features, and till date, only a few occlusion handling strategies to gait recognition have been proposed. But none of these performs reliably and robustly in the presence of a single cycle with incomplete information, and because of this practical application of gait recognition is quite limited. In this work, we develop deep learning-based algorithm to accurately identify the affected frames as well as predict the missing frames to reconstruct a complete gait cycle. While occlusion detection has been carried out by employing a VGG-16 model, the model for frame reconstruction is based on Long-Short Term Memory network that has been trained to optimize a multi-objective function based on dice coefficient and cross-entropy loss. The effectiveness of the proposed occlusion reconstruction algorithm is evaluated by computing the accuracy of the popular Gait Energy Feature on the reconstructed sequence. Experimental evaluation on public data sets and comparative analysis with other occlusion handling methods verify the effectiveness of our approach.
Fully Automated Image De-fencing using Conditional Generative Adversarial Networks
Aug 19, 2019

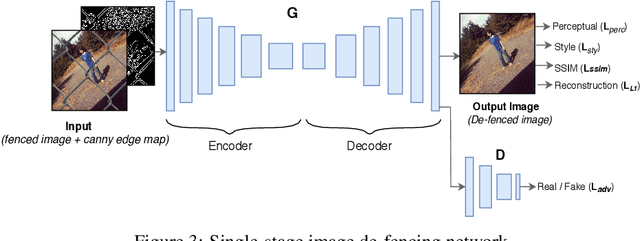

Image de-fencing is one of the important aspects of recreational photography in which the objective is to remove the fence texture present in an image and generate an aesthetically pleasing version of the same image without the fence texture. In this paper, we aim to develop an automated and effective technique for fence removal and image reconstruction using conditional Generative Adversarial Networks (cGANs). These networks have been successfully applied in several domains of Computer Vision focusing on image generation and rendering. Our initial approach is based on a two-stage architecture involving two cGANs that generate the fence mask and the inpainted image, respectively. Training of these networks is carried out independently and, during evaluation, the input image is passed through the two generators in succession to obtain the de-fenced image. The results obtained from this approach are satisfactory, but the response time is long since the image has to pass through two sets of convolution layers. To reduce the response time, we propose a second approach involving only a single cGAN architecture that is trained using the ground-truth of fenced de-fenced image pairs along with the edge map of the fenced image produced by the Canny Filter. Incorporation of the edge map helps the network to precisely detect the edges present in the input image, and also imparts it an ability to carry out high quality de-fencing in an efficient manner, even in the presence of a fewer number of layers as compared to the two-stage network. Qualitative and quantitative experimental results reported in the manuscript reveal that the de-fenced images generated by the single-stage de-fencing network have similar visual quality to those produced by the two-stage network. Comparative performance analysis also emphasizes the effectiveness of our approach over state-of-the-art image de-fencing techniques.
Broad Neural Network for Change Detection in Aerial Images
Feb 28, 2019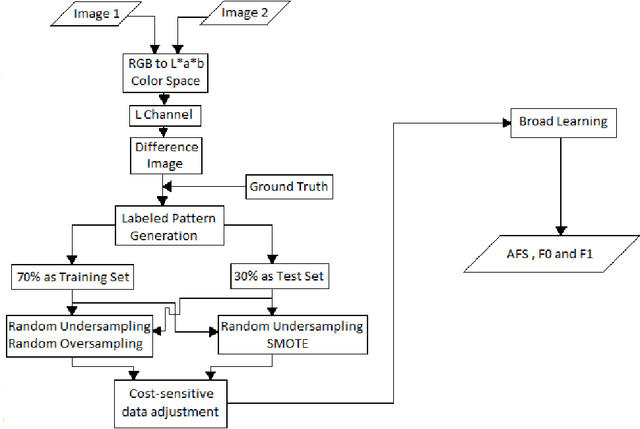
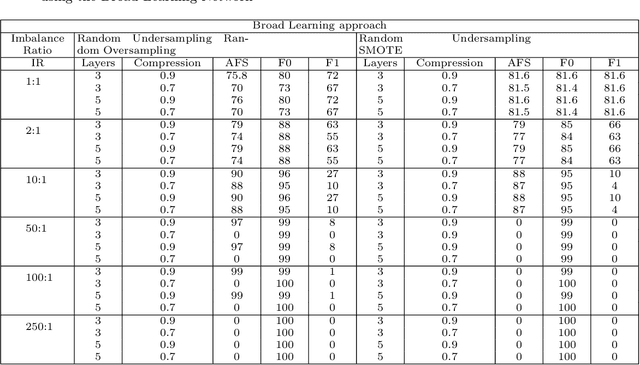
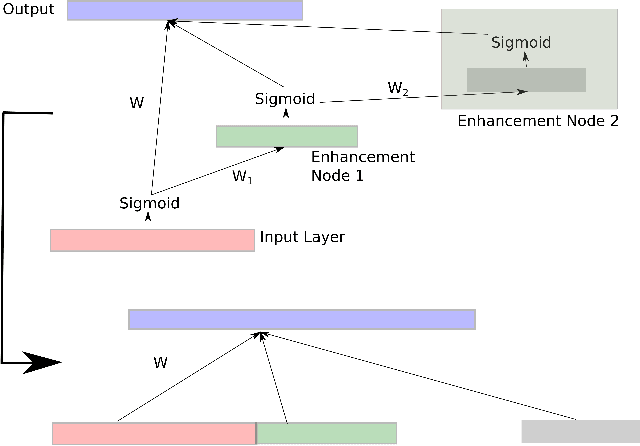
A change detection system takes as input two images of a region captured at two different times, and predicts which pixels in the region have undergone change over the time period. Since pixel-based analysis can be erroneous due to noise, illumination difference and other factors, contextual information is usually used to determine the class of a pixel (changed or not). This contextual information is taken into account by considering a pixel of the difference image along with its neighborhood. With the help of ground truth information, the labeled patterns are generated. Finally, Broad Learning classifier is used to get prediction about the class of each pixel. Results show that Broad Learning can classify the data set with a significantly higher F-Score than that of Multilayer Perceptron. Performance comparison has also been made with other popular classifiers, namely Multilayer Perceptron and Random Forest.