 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHD-TTA: Hypothesis-Driven Test-Time Adaptation for Safer Brain Tumor Segmentation
Feb 23, 2026Standard Test-Time Adaptation (TTA) methods typically treat inference as a blind optimization task, applying generic objectives to all or filtered test samples. In safety-critical medical segmentation, this lack of selectivity often causes the tumor mask to spill into healthy brain tissue or degrades predictions that were already correct. We propose Hypothesis-Driven TTA, a novel framework that reformulates adaptation as a dynamic decision process. Rather than forcing a single optimization trajectory, our method generates intuitive competing geometric hypotheses: compaction (is the prediction noisy? trim artifacts) versus inflation (is the valid tumor under-segmented? safely inflate to recover). It then employs a representation-guided selector to autonomously identify the safest outcome based on intrinsic texture consistency. Additionally, a pre-screening Gatekeeper prevents negative transfer by skipping adaptation on confident cases. We validate this proof-of-concept on a cross-domain binary brain tumor segmentation task, applying a source model trained on adult BraTS gliomas to unseen pediatric and more challenging meningioma target domains. HD-TTA improves safety-oriented outcomes (Hausdorff Distance (HD95) and Precision) over several state-of-the-art representative baselines in the challenging safety regime, reducing the HD95 by approximately 6.4 mm and improving Precision by over 4%, while maintaining comparable Dice scores. These results demonstrate that resolving the safety-adaptation trade-off via explicit hypothesis selection is a viable, robust path for safe clinical model deployment. Code will be made publicly available upon acceptance.
Harmonizing Intra-coherence and Inter-divergence in Ensemble Attacks for Adversarial Transferability
May 02, 2025The development of model ensemble attacks has significantly improved the transferability of adversarial examples, but this progress also poses severe threats to the security of deep neural networks. Existing methods, however, face two critical challenges: insufficient capture of shared gradient directions across models and a lack of adaptive weight allocation mechanisms. To address these issues, we propose a novel method Harmonized Ensemble for Adversarial Transferability (HEAT), which introduces domain generalization into adversarial example generation for the first time. HEAT consists of two key modules: Consensus Gradient Direction Synthesizer, which uses Singular Value Decomposition to synthesize shared gradient directions; and Dual-Harmony Weight Orchestrator which dynamically balances intra-domain coherence, stabilizing gradients within individual models, and inter-domain diversity, enhancing transferability across models. Experimental results demonstrate that HEAT significantly outperforms existing methods across various datasets and settings, offering a new perspective and direction for adversarial attack research.
Local-peak scale-invariant feature transform for fast and random image stitching
May 14, 2024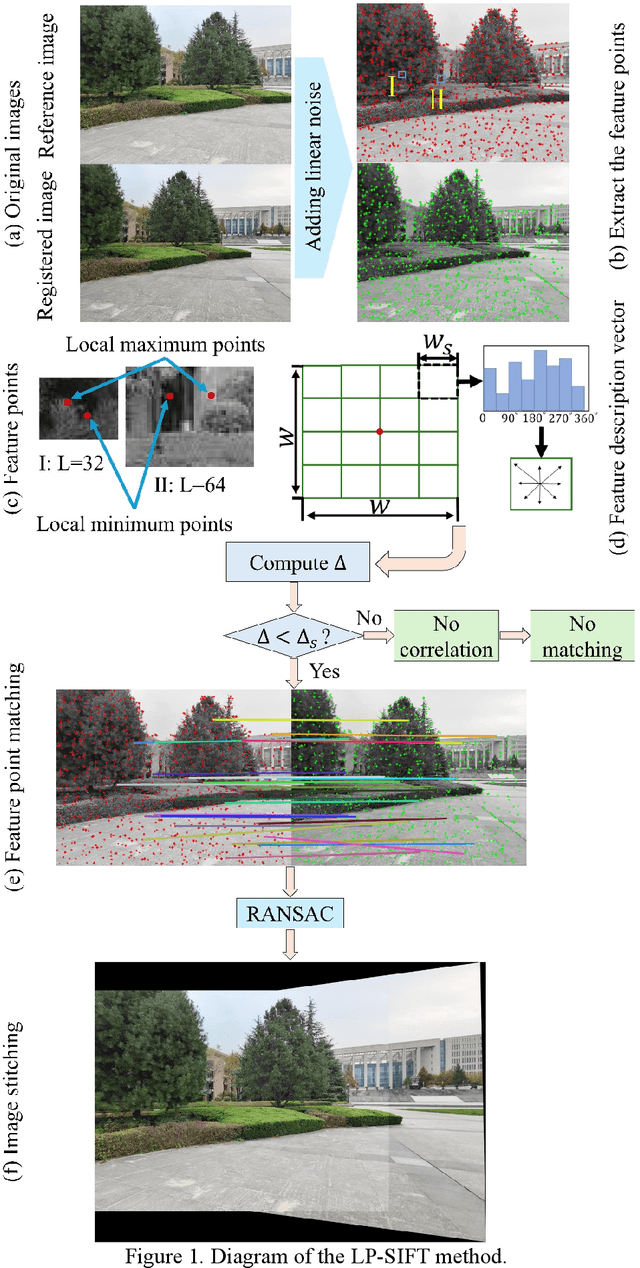

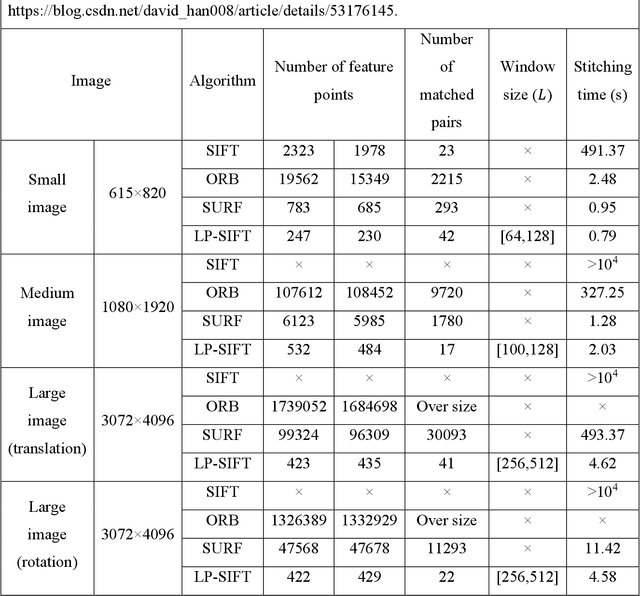
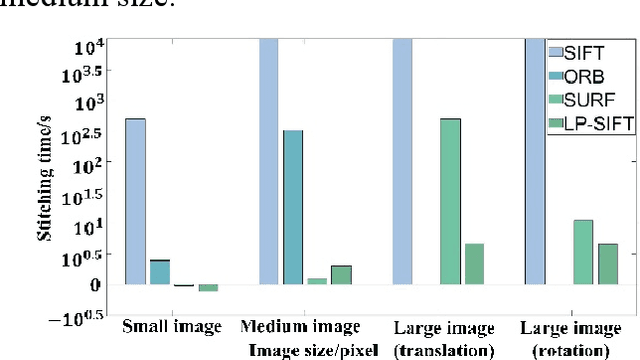
Image stitching aims to construct a wide field of view with high spatial resolution, which cannot be achieved in a single exposure. Typically, conventional image stitching techniques, other than deep learning, require complex computation and thus computational pricy, especially for stitching large raw images. In this study, inspired by the multiscale feature of fluid turbulence, we developed a fast feature point detection algorithm named local-peak scale-invariant feature transform (LP-SIFT), based on the multiscale local peaks and scale-invariant feature transform method. By combining LP-SIFT and RANSAC in image stitching, the stitching speed can be improved by orders, compared with the original SIFT method. Nine large images (over 2600*1600 pixels), arranged randomly without prior knowledge, can be stitched within 158.94 s. The algorithm is highly practical for applications requiring a wide field of view in diverse application scenes, e.g., terrain mapping, biological analysis, and even criminal investigation.
BGaitR-Net: Occluded Gait Sequence reconstructionwith temporally constrained model for gait recognition
Oct 18, 2021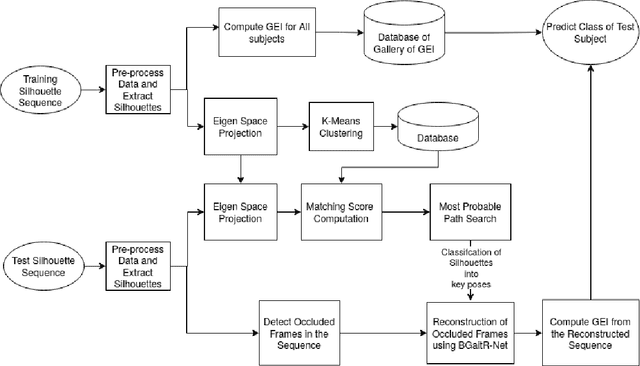
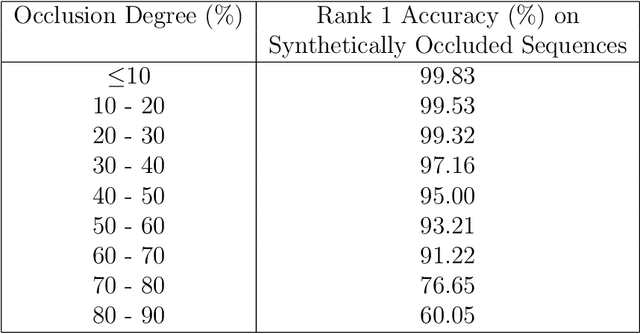

Recent advancements in computational resources and Deep Learning methodologies has significantly benefited development of intelligent vision-based surveillance applications. Gait recognition in the presence of occlusion is one of the challenging research topics in this area, and the solutions proposed by researchers to date lack in robustness and also dependent of several unrealistic constraints, which limits their practical applicability. We improve the state-of-the-art by developing novel deep learning-based algorithms to identify the occluded frames in an input sequence and next reconstruct these occluded frames by exploiting the spatio-temporal information present in the gait sequence. The multi-stage pipeline adopted in this work consists of key pose mapping, occlusion detection and reconstruction, and finally gait recognition. While the key pose mapping and occlusion detection phases are done %using Constrained KMeans Clustering and via a graph sorting algorithm, reconstruction of occluded frames is done by fusing the key pose-specific information derived in the previous step along with the spatio-temporal information contained in a gait sequence using a Bi-Directional Long Short Time Memory. This occlusion reconstruction model has been trained using synthetically occluded CASIA-B and OU-ISIR data, and the trained model is termed as Bidirectional Gait Reconstruction Network BGait-R-Net. Our LSTM-based model reconstructs occlusion and generates frames that are temporally consistent with the periodic pattern of a gait cycle, while simultaneously preserving the body structure.
Speech Fusion to Face: Bridging the Gap Between Human's Vocal Characteristics and Facial Imaging
Jun 10, 2020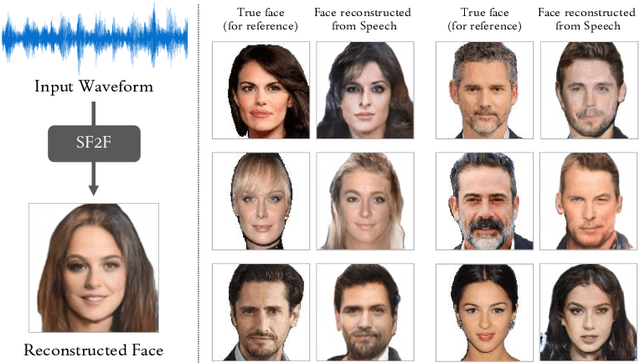
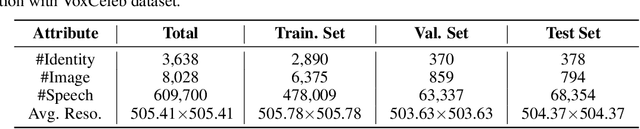
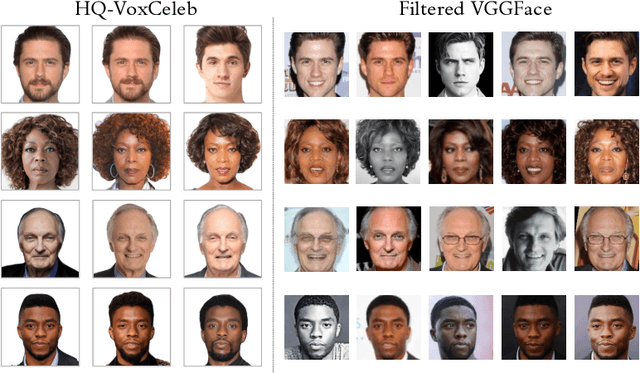

While deep learning technologies are now capable of generating realistic images confusing humans, the research efforts are turning to the synthesis of images for more concrete and application-specific purposes. Facial image generation based on vocal characteristics from speech is one of such important yet challenging tasks. It is the key enabler to influential use cases of image generation, especially for business in public security and entertainment. Existing solutions to the problem of speech2face renders limited image quality and fails to preserve facial similarity due to the lack of quality dataset for training and appropriate integration of vocal features. In this paper, we investigate these key technical challenges and propose Speech Fusion to Face, or SF2F in short, attempting to address the issue of facial image quality and the poor connection between vocal feature domain and modern image generation models. By adopting new strategies on data model and training, we demonstrate dramatic performance boost over state-of-the-art solution, by doubling the recall of individual identity, and lifting the quality score from 15 to 19 based on the mutual information score with VGGFace classifier.
3D Deep Learning on Medical Images: A Review
Apr 01, 2020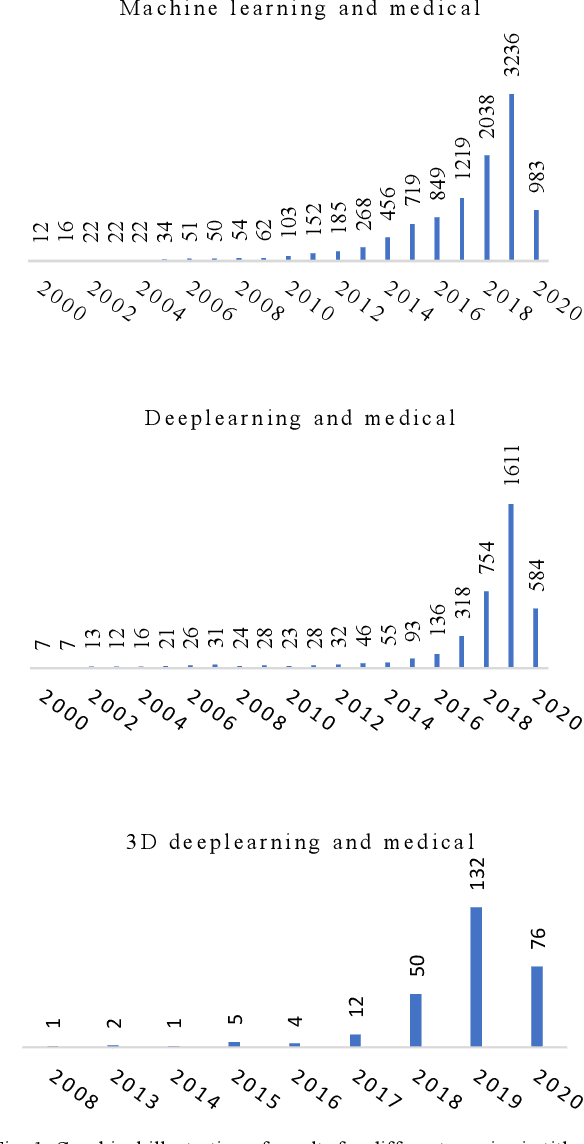
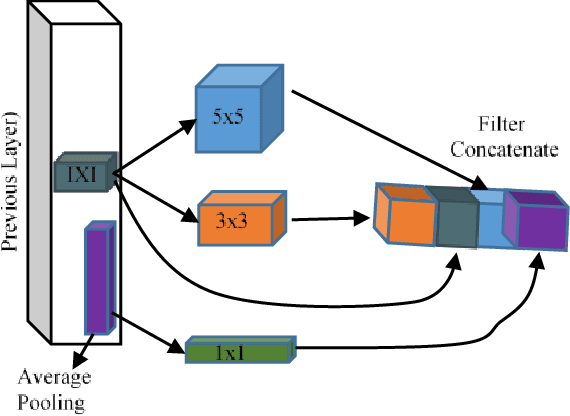
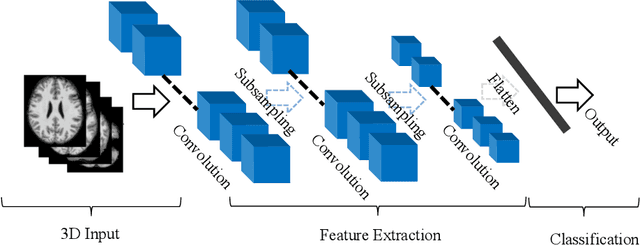
The rapid advancements in machine learning, graphics processing technologies and availability of medical imaging data has led to a rapid increase in use of machine learning models in the medical domain. This was exacerbated by the rapid advancements in convolutional neural network (CNN) based architectures, which were adopted by the medical imaging community to assist clinicians in disease diagnosis. Since the grand success of AlexNet in 2012, CNNs have been increasingly used in medical image analysis to improve the efficiency of human clinicians. In recent years, three-dimensional (3D) CNNs have been employed for analysis of medical images. In this paper, we trace the history of how the 3D CNN was developed from its machine learning roots, brief mathematical description of 3D CNN and the preprocessing steps required for medical images before feeding them to 3D CNNs. We review the significant research in the field of 3D medical imaging analysis using 3D CNNs (and its variants) in different medical areas such as classification, segmentation, detection, and localization. We conclude by discussing the challenges associated with the use of 3D CNNs in the medical imaging domain (and the use of deep learning models, in general) and possible future trends in the field.
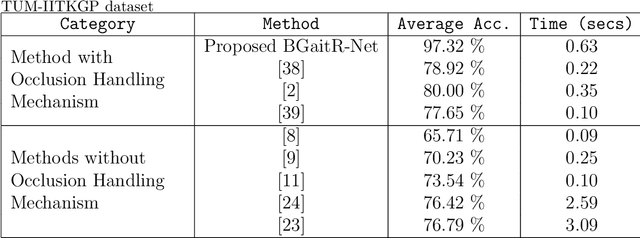
RGait-NET: An Effective Network for Recovering Missing Information from Occluded Gait Cycles
Jan 20, 2020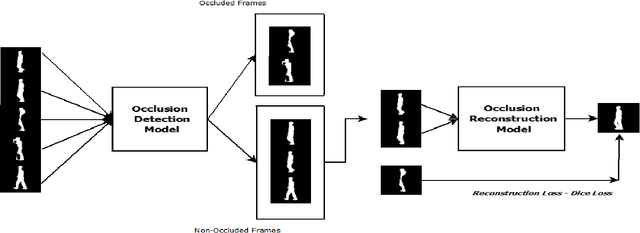
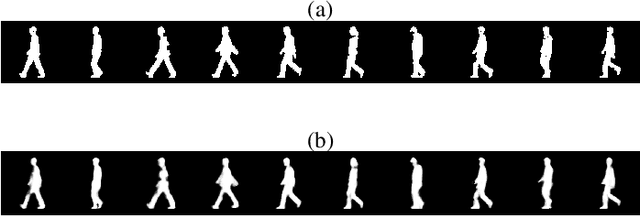
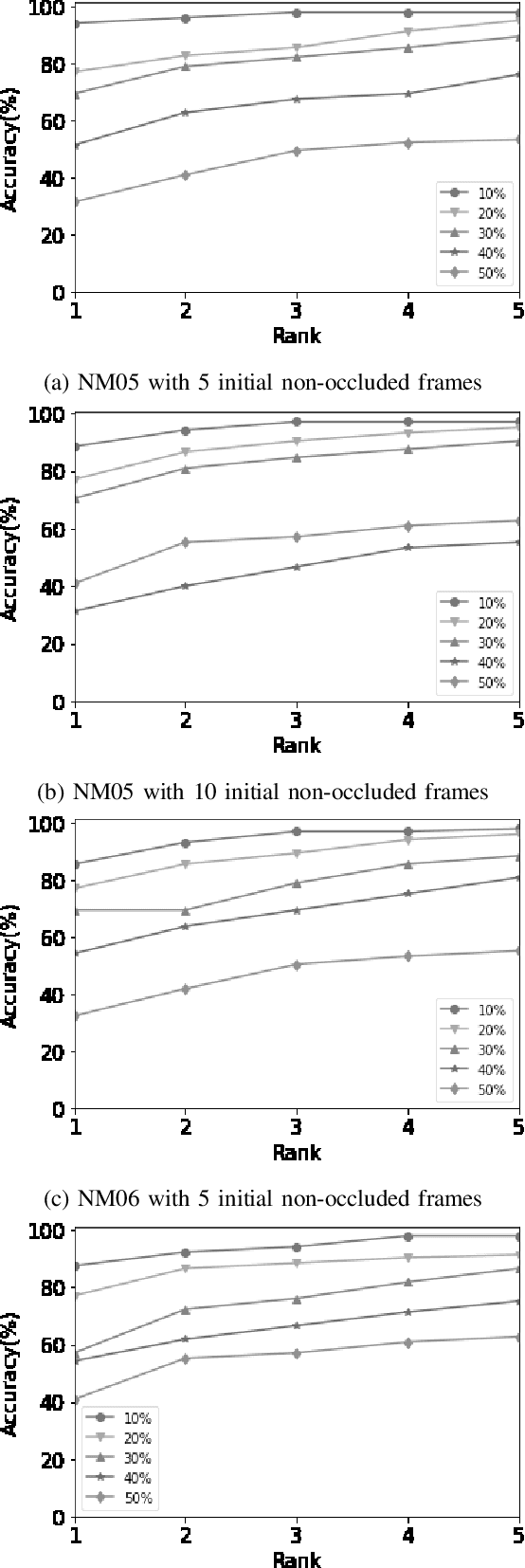
Gait of a person refers to his/her walking pattern, and according to medical studies gait of every individual is unique. Over the past decade, several computer vision-based gait recognition approaches have been proposed in which walking information corresponding to a complete gait cycle has been used to construct gait features for person identification. These methods compute gait features with the inherent assumption that a complete gait cycle is always available. However, in most public places occlusion is an inevitable occurrence, and due to this, only a fraction of a gait cycle gets captured by the monitoring camera. Unavailability of complete gait cycle information drastically affects the accuracy of the extracted features, and till date, only a few occlusion handling strategies to gait recognition have been proposed. But none of these performs reliably and robustly in the presence of a single cycle with incomplete information, and because of this practical application of gait recognition is quite limited. In this work, we develop deep learning-based algorithm to accurately identify the affected frames as well as predict the missing frames to reconstruct a complete gait cycle. While occlusion detection has been carried out by employing a VGG-16 model, the model for frame reconstruction is based on Long-Short Term Memory network that has been trained to optimize a multi-objective function based on dice coefficient and cross-entropy loss. The effectiveness of the proposed occlusion reconstruction algorithm is evaluated by computing the accuracy of the popular Gait Energy Feature on the reconstructed sequence. Experimental evaluation on public data sets and comparative analysis with other occlusion handling methods verify the effectiveness of our approach.
Fully Automated Image De-fencing using Conditional Generative Adversarial Networks
Aug 19, 2019

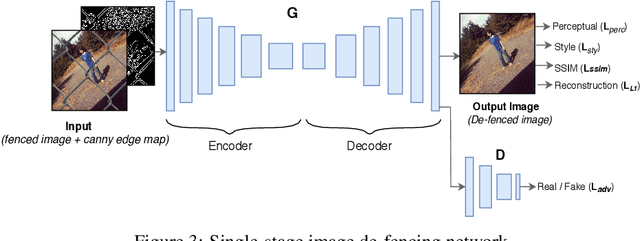

Image de-fencing is one of the important aspects of recreational photography in which the objective is to remove the fence texture present in an image and generate an aesthetically pleasing version of the same image without the fence texture. In this paper, we aim to develop an automated and effective technique for fence removal and image reconstruction using conditional Generative Adversarial Networks (cGANs). These networks have been successfully applied in several domains of Computer Vision focusing on image generation and rendering. Our initial approach is based on a two-stage architecture involving two cGANs that generate the fence mask and the inpainted image, respectively. Training of these networks is carried out independently and, during evaluation, the input image is passed through the two generators in succession to obtain the de-fenced image. The results obtained from this approach are satisfactory, but the response time is long since the image has to pass through two sets of convolution layers. To reduce the response time, we propose a second approach involving only a single cGAN architecture that is trained using the ground-truth of fenced de-fenced image pairs along with the edge map of the fenced image produced by the Canny Filter. Incorporation of the edge map helps the network to precisely detect the edges present in the input image, and also imparts it an ability to carry out high quality de-fencing in an efficient manner, even in the presence of a fewer number of layers as compared to the two-stage network. Qualitative and quantitative experimental results reported in the manuscript reveal that the de-fenced images generated by the single-stage de-fencing network have similar visual quality to those produced by the two-stage network. Comparative performance analysis also emphasizes the effectiveness of our approach over state-of-the-art image de-fencing techniques.
On the self-similarity of line segments in decaying homogeneous isotropic turbulence
Sep 20, 2018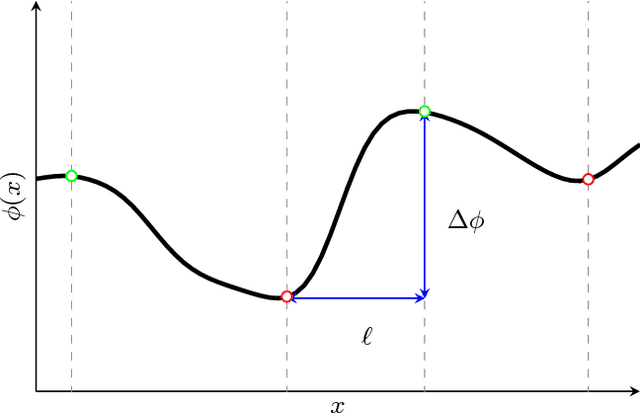

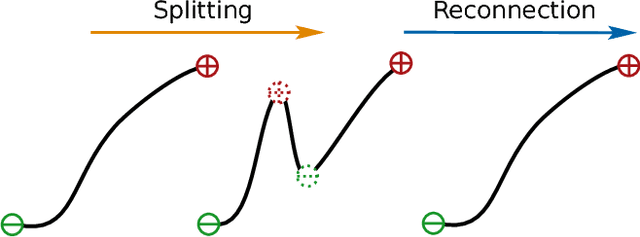
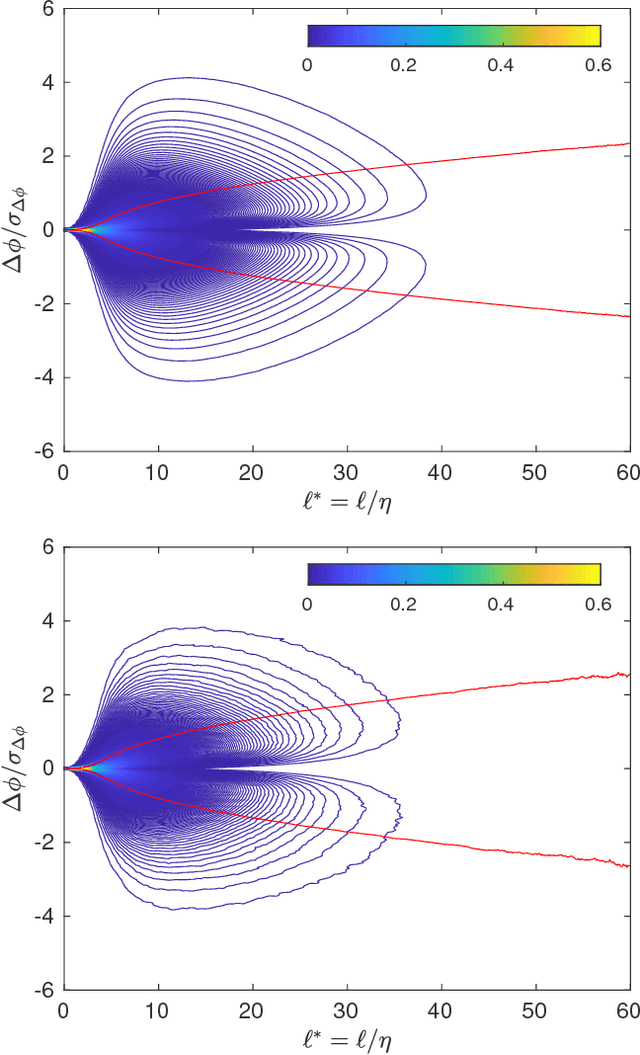
The self-similarity of a passive scalar in homogeneous isotropic decaying turbulence is investigated by the method of line segments (M. Gauding et al., Physics of Fluids 27.9 (2015): 095102). The analysis is based on a highly resolved direct numerical simulation of decaying turbulence. The method of line segments is used to perform a decomposition of the scalar field into smaller sub-units based on the extremal points of the scalar along a straight line. These sub-units (the so-called line segments) are parameterized by their length $\ell$ and the difference $\Delta\phi$ of the scalar field between the ending points. Line segments can be understood as thin local convective-diffusive structures in which diffusive processes are enhanced by compressive strain. From DNS, it is shown that the marginal distribution function of the length~$\ell$ assumes complete self-similarity when re-scaled by the mean length $\ell_m$. The joint statistics of $\Delta\phi$ and $\ell$, from which the local gradient $g=\Delta\phi/\ell$ can be defined, play an important role in understanding the turbulence mixing and flow structure. Large values of $g$ occur at a small but finite length scale. Statistics of $g$ are characterized by rare but strong deviations that exceed the standard deviation by more than one order of magnitude. It is shown that these events break complete self-similarity of line segments, which confirms the standard paradigm of turbulence that intense events (which are known as internal intermittency) are not self-similar.
apk2vec: Semi-supervised multi-view representation learning for profiling Android applications
Sep 15, 2018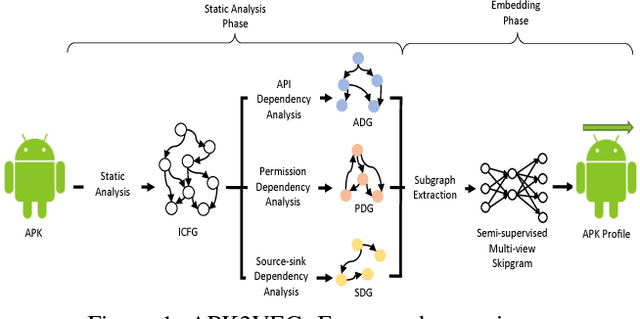
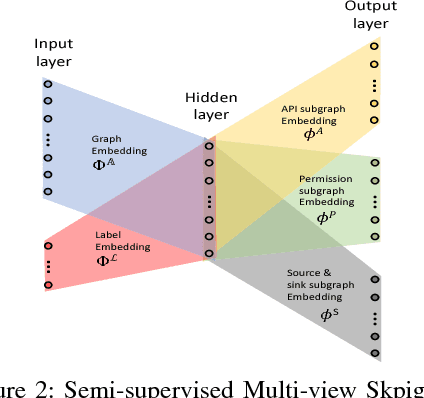
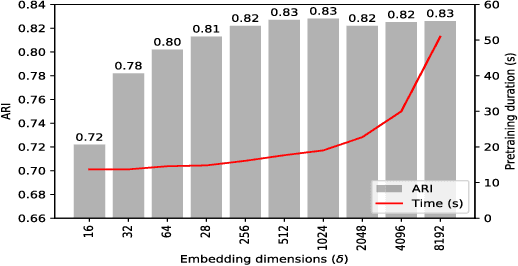
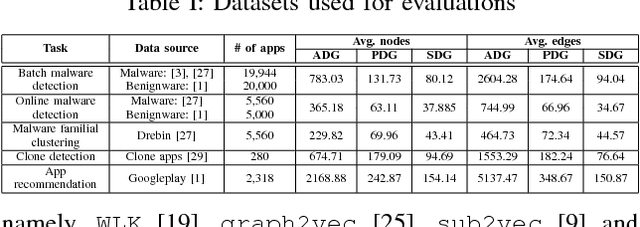
Building behavior profiles of Android applications (apps) with holistic, rich and multi-view information (e.g., incorporating several semantic views of an app such as API sequences, system calls, etc.) would help catering downstream analytics tasks such as app categorization, recommendation and malware analysis significantly better. Towards this goal, we design a semi-supervised Representation Learning (RL) framework named apk2vec to automatically generate a compact representation (aka profile/embedding) for a given app. More specifically, apk2vec has the three following unique characteristics which make it an excellent choice for largescale app profiling: (1) it encompasses information from multiple semantic views such as API sequences, permissions, etc., (2) being a semi-supervised embedding technique, it can make use of labels associated with apps (e.g., malware family or app category labels) to build high quality app profiles, and (3) it combines RL and feature hashing which allows it to efficiently build profiles of apps that stream over time (i.e., online learning). The resulting semi-supervised multi-view hash embeddings of apps could then be used for a wide variety of downstream tasks such as the ones mentioned above. Our extensive evaluations with more than 42,000 apps demonstrate that apk2vec's app profiles could significantly outperform state-of-the-art techniques in four app analytics tasks namely, malware detection, familial clustering, app clone detection and app recommendation.