 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-guided surrogate learning enables zero-shot control of turbulent wings
Apr 13, 2026Turbulent boundary layers over aerodynamic surfaces are a major source of aircraft drag, yet their control remains challenging due to multiscale dynamics and spatial variability, particularly under adverse pressure gradients. Reinforcement learning has outperformed state-of-the-art strategies in canonical flows, but its application to realistic geometries is limited by computational cost and transferability. Here we show that these limitations can be overcome by exploiting local structures of wall-bounded turbulence. Policies are trained in turbulent channel flows matched to wing boundary-layer statistics and deployed directly onto a NACA4412 wing at $Re_c=2\times10^5$ without further training, being the so-called zero-shot control. This achieves a 28.7% reduction in skin-friction drag and a 10.7% reduction in total drag, outperforming the state-of-the-art opposition control by 40% in friction drag reduction and 5% in total drag. Training cost is reduced by four orders of magnitude relative to on-wing training, enabling scalable flow control.
Modeling subgrid scale production rates on complex meshes using graph neural networks
Mar 20, 2026Large-eddy simulations (LES) require closures for filtered production rates because the resolved fields do not contain all correlations that govern chemical source terms. We develop a graph neural network (GNN) that predicts filtered species production rates on non-uniform meshes from inputs of filtered mass fractions and temperature. Direct numerical simulations of turbulent premixed hydrogen-methane jet flames with hydrogen fractions of 10%, 50%, and 80% provide the dataset. All fields are Favre filtered with the filter width matched to the operating mesh, and learning is performed on subdomain graphs constructed from mesh-point connectivity. A compact set of reactants, intermediates, and products is used, and their filtered production rates form the targets. The model is trained on 10% and 80% blends and evaluated on the unseen 50% blend to test cross-composition generalization. The GNN is compared against an unclosed reference that evaluates rates at the filtered state, and a convolutional neural network baseline that requires remeshing. Across in-distribution and out-of-distribution cases, the GNN yields lower errors and closer statistical agreement with the reference data. Furthermore, the model demonstrates robust generalization across varying filter widths without retraining, maintaining bounded errors at coarser spatial resolutions. A backward facing step configuration further confirms prediction efficacy on a practically relevant geometry. These results highlight the capability of GNNs as robust data-driven closure models for LES on complex meshes.
Super-resolution of turbulent reacting flows on complex meshes using graph neural networks
Mar 01, 2026State-of-the-art deep learning models have been extensively utilized to reconstruct small-scale structures from coarse-grained data in turbulent flows. However, their application has predominantly been restricted to structured uniform meshes, limiting their applicability to data associated with complex geometries that are typically simulated on structured non-uniform or unstructured meshes. Machine learning (ML) models based on graph neural networks (GNNs), known for their ability to process unstructured data, offer a promising alternative. In this study, we leverage the inherent flexibility of GNNs featuring message passing layers to develop a methodology for reconstructing unresolved small-scale structures from low-resolution data on complex meshes. The accuracy of the proposed approach is demonstrated using two cases: a reacting channel flow on a structured non-uniform mesh, and a reacting hydrogen fueled internal combustion (IC) engine featuring an unstructured mesh. Evaluation of results based on visual agreement, statistical metrics, and cumulative error reduction indicates the effectiveness of the method in accurately reconstructing fine-scale features. Overall, this study provides a pathway for integrating data-driven small-scale reconstruction and subgrid-scale modeling to enhance the accuracy of coarse-grained simulations on complex meshes.
Towards prediction of turbulent flows at high Reynolds numbers using high performance computing data and deep learning
Oct 28, 2022In this paper, deep learning (DL) methods are evaluated in the context of turbulent flows. Various generative adversarial networks (GANs) are discussed with respect to their suitability for understanding and modeling turbulence. Wasserstein GANs (WGANs) are then chosen to generate small-scale turbulence. Highly resolved direct numerical simulation (DNS) turbulent data is used for training the WGANs and the effect of network parameters, such as learning rate and loss function, is studied. Qualitatively good agreement between DNS input data and generated turbulent structures is shown. A quantitative statistical assessment of the predicted turbulent fields is performed.
Applying Physics-Informed Enhanced Super-Resolution Generative Adversarial Networks to Turbulent Premixed Combustion and Engine-like Flame Kernel Direct Numerical Simulation Data
Oct 28, 2022Models for finite-rate-chemistry in underresolved flows still pose one of the main challenges for predictive simulations of complex configurations. The problem gets even more challenging if turbulence is involved. This work advances the recently developed PIESRGAN modeling approach to turbulent premixed combustion. For that, the physical information processed by the network and considered in the loss function are adjusted, the training process is smoothed, and especially effects from density changes are considered. The resulting model provides good results for a priori and a posteriori tests on direct numerical simulation data of a fully turbulent premixed flame kernel. The limits of the modeling approach are discussed. Finally, the model is employed to compute further realizations of the premixed flame kernel, which are analyzed with a scale-sensitive framework regarding their cycle-to-cycle variations. The work shows that the data-driven PIESRGAN subfilter model can very accurately reproduce direct numerical simulation data on much coarser meshes, which is hardly possible with classical subfilter models, and enables studying statistical processes more efficiently due to the smaller computing cost.
Applying Physics-Informed Enhanced Super-Resolution Generative Adversarial Networks to Finite-Rate-Chemistry Flows and Predicting Lean Premixed Gas Turbine Combustors
Oct 28, 2022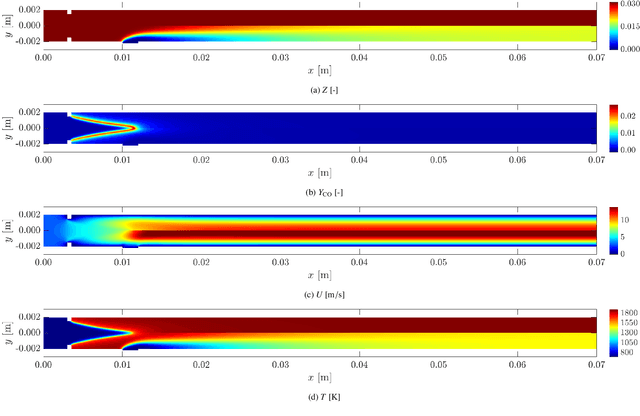

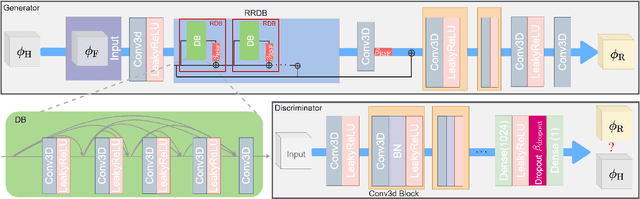
The accurate prediction of small scales in underresolved flows is still one of the main challenges in predictive simulations of complex configurations. Over the last few years, data-driven modeling has become popular in many fields as large, often extensively labeled datasets are now available and training of large neural networks has become possible on graphics processing units (GPUs) that speed up the learning process tremendously. In fact, the successful application of deep neural networks in fluid dynamics, such as for underresolved reactive flows, is still challenging. This work advances the recently introduced PIESRGAN to reactive finite-rate-chemistry flows. However, since combustion chemistry typically acts on the smallest scales, the original approach needs to be extended. Therefore, the modeling approach of PIESRGAN is modified to accurately account for the challenges in the context of laminar finite-rate-chemistry flows. The modified PIESRGAN-based model gives good agreement in a priori and a posteriori tests in a laminar lean premixed combustion setup. Furthermore, a reduced PIESRGAN-based model is presented that solves only the major species on a reconstructed field and employs PIERSGAN lookup for the remaining species, utilizing staggering in time. The advantages of the discriminator-supported training are shown, and the usability of the new model demonstrated in the context of a model gas turbine combustor.
Applying Physics-Informed Enhanced Super-Resolution Generative Adversarial Networks to Turbulent Non-Premixed Combustion on Non-Uniform Meshes and Demonstration of an Accelerated Simulation Workflow
Oct 28, 2022



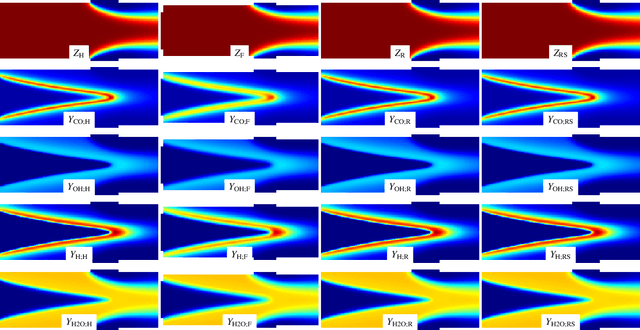
This paper extends the methodology to use physics-informed enhanced super-resolution generative adversarial networks (PIESRGANs) for LES subfilter modeling in turbulent flows with finite-rate chemistry and shows a successful application to a non-premixed temporal jet case. This is an important topic considering the need for more efficient and carbon-neutral energy devices to fight the climate change. Multiple a priori and a posteriori results are presented and discussed. As part of this, the impact of the underlying mesh on the prediction quality is emphasized, and a multi-mesh approach is developed. It is demonstrated how LES based on PIESRGAN can be employed to predict cases at Reynolds numbers which were not used for training. Finally, the amount of data needed for a successful prediction is elaborated.
Pandemic Drugs at Pandemic Speed: Accelerating COVID-19 Drug Discovery with Hybrid Machine Learning- and Physics-based Simulations on High Performance Computers
Mar 04, 2021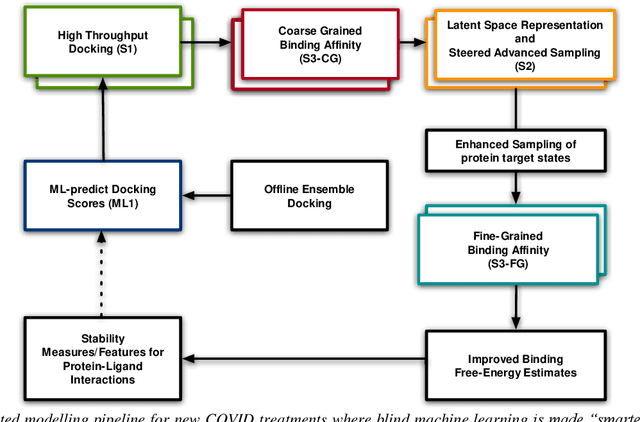

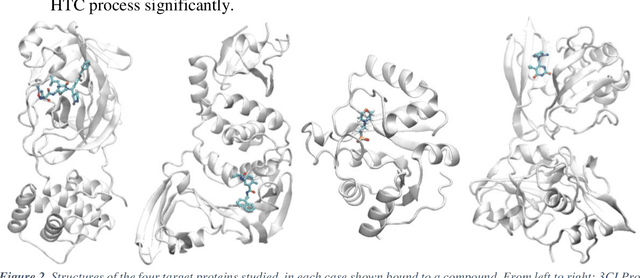
The race to meet the challenges of the global pandemic has served as a reminder that the existing drug discovery process is expensive, inefficient and slow. There is a major bottleneck screening the vast number of potential small molecules to shortlist lead compounds for antiviral drug development. New opportunities to accelerate drug discovery lie at the interface between machine learning methods, in this case developed for linear accelerators, and physics-based methods. The two in silico methods, each have their own advantages and limitations which, interestingly, complement each other. Here, we present an innovative method that combines both approaches to accelerate drug discovery. The scale of the resulting workflow is such that it is dependent on high performance computing. We have demonstrated the applicability of this workflow on four COVID-19 target proteins and our ability to perform the required large-scale calculations to identify lead compounds on a variety of supercomputers.
Using Physics-Informed Super-Resolution Generative Adversarial Networks for Subgrid Modeling in Turbulent Reactive Flows
Nov 26, 2019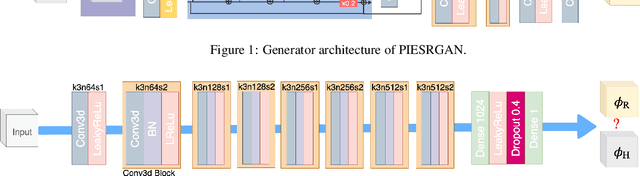
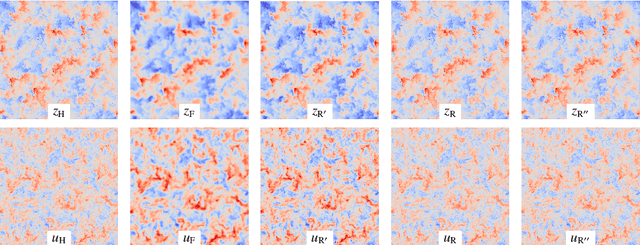
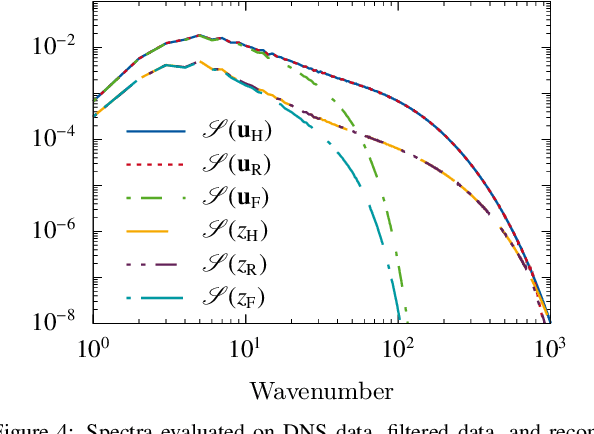
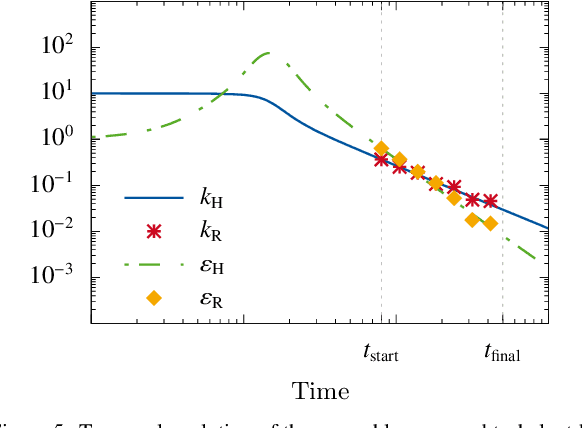
Turbulence is still one of the main challenges for accurately predicting reactive flows. Therefore, the development of new turbulence closures which can be applied to combustion problems is essential. Data-driven modeling has become very popular in many fields over the last years as large, often extensively labeled, datasets became available and training of large neural networks became possible on GPUs speeding up the learning process tremendously. However, the successful application of deep neural networks in fluid dynamics, for example for subgrid modeling in the context of large-eddy simulations (LESs), is still challenging. Reasons for this are the large amount of degrees of freedom in realistic flows, the high requirements with respect to accuracy and error robustness, as well as open questions, such as the generalization capability of trained neural networks in such high-dimensional, physics-constrained scenarios. This work presents a novel subgrid modeling approach based on a generative adversarial network (GAN), which is trained with unsupervised deep learning (DL) using adversarial and physics-informed losses. A two-step training method is used to improve the generalization capability, especially extrapolation, of the network. The novel approach gives good results in a priori as well as a posteriori tests with decaying turbulence including turbulent mixing. The applicability of the network in complex combustion scenarios is furthermore discussed by employing it to a reactive LES of the Spray A case defined by the Engine Combustion Network (ECN).
Deep learning at scale for subgrid modeling in turbulent flows
Oct 01, 2019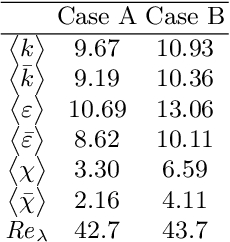
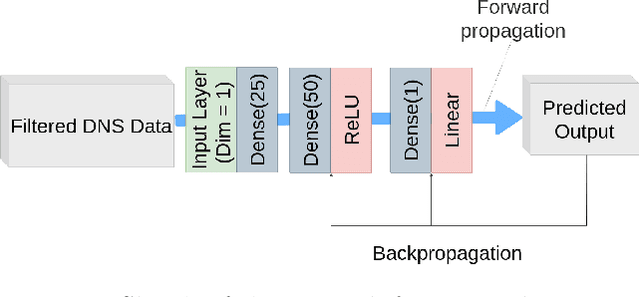
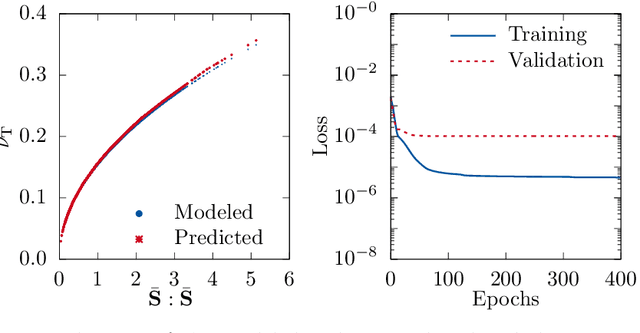
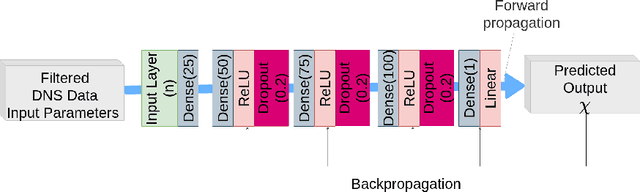
Modeling of turbulent flows is still challenging. One way to deal with the large scale separation due to turbulence is to simulate only the large scales and model the unresolved contributions as done in large-eddy simulation (LES). This paper focuses on two deep learning (DL) strategies, regression and reconstruction, which are data-driven and promising alternatives to classical modeling concepts. Using three-dimensional (3-D) forced turbulence direct numerical simulation (DNS) data, subgrid models are evaluated, which predict the unresolved part of quantities based on the resolved solution. For regression, it is shown that feedforward artificial neural networks (ANNs) are able to predict the fully-resolved scalar dissipation rate using filtered input data. It was found that a combination of a large-scale quantity, such as the filtered passive scalar itself, and a small-scale quantity, such as the filtered energy dissipation rate, gives the best agreement with the actual DNS data. Furthermore, a DL network motivated by enhanced super-resolution generative adversarial networks (ESRGANs) was used to reconstruct fully-resolved 3-D velocity fields from filtered velocity fields. The energy spectrum shows very good agreement. As size of scientific data is often in the order of terabytes or more, DL needs to be combined with high performance computing (HPC). Necessary code improvements for HPC-DL are discussed with respect to the supercomputer JURECA. After optimizing the training code, 396.2 TFLOPS were achieved.