 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA graphical heuristic for reduction and partitioning of large datasets for scalable supervised training
Paper and Code
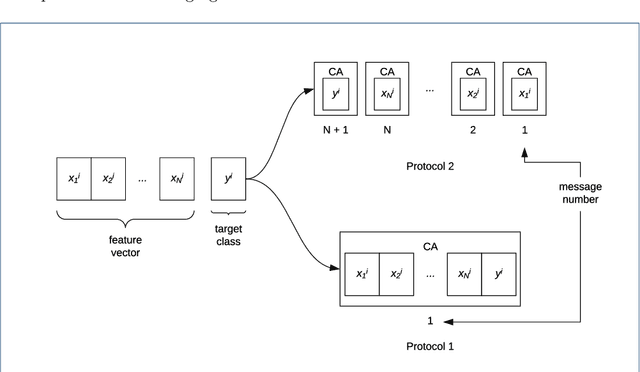
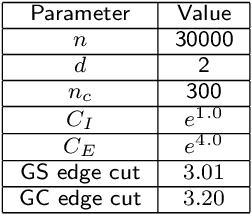
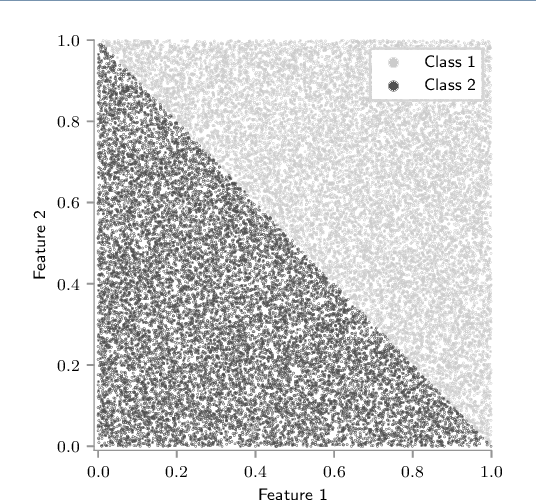

A scalable graphical method is presented for selecting, and partitioning datasets for the training phase of a classification task. For the heuristic, a clustering algorithm is required to get its computation cost in a reasonable proportion to the task itself. This step is proceeded by construction of an information graph of the underlying classification patterns using approximate nearest neighbor methods. The presented method constitutes of two approaches, one for reducing a given training set, and another for partitioning the selected/reduced set. The heuristic targets large datasets, since the primary goal is significant reduction in training computation run-time without compromising prediction accuracy. Test results show that both approaches significantly speed-up the training task when compared against that of state-of-the-art shrinking heuristic available in LIBSVM. Furthermore, the approaches closely follow or even outperform in prediction accuracy. A network design is also presented for the partitioning based distributed training formulation. Added speed-up in training run-time is observed when compared to that of serial implementation of the approaches.