 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimbre-Aware LLM-based Direct Speech-to-Speech Translation Extendable to Multiple Language Pairs
Jan 22, 2026Direct Speech-to-Speech Translation (S2ST) has gained increasing attention for its ability to translate speech from one language to another, while reducing error propagation and latency inherent in traditional cascaded pipelines. However, existing direct S2ST systems continue to face notable challenges, including instability in semantic-acoustic alignment when parallel speech data is scarce, difficulty in preserving speaker identity, and limited multilingual scalability. In this work, we introduce DS2ST-LM, a scalable, single-stage direct S2ST framework leveraging a multilingual Large Language Model (LLM). The architecture integrates a Whisper speech encoder, a learnable projection module, a Qwen2-0.5B LLM, and a timbre-controlled vocoder. We construct GigaS2S-1000, a 1000-hour bilingual corpus by extending the GigaST dataset with high-fidelity synthetic target speech, and show that this synthetic data alleviates data scarcity to some extent. We investigate two semantic token generation strategies: speech-derived S3 tokens and text-derived tokens generated by a pre-trained LLM, and analyze their impact on training stability and semantic consistency. We further evaluate three projection architectures (Linear, Conv1D-Linear, and Q-Former) and observe that while higher-capacity projectors converge faster, the simple Linear projector achieves higher performance. Extensive experiments demonstrate that DS2ST-LM outperforms traditional cascaded and ST (Qwen-Audio) + TTS baselines across both lexical (BLEU, METEOR) and semantic (BLEURT, COMET) metrics, while extending to multiple language pairs, including French, Spanish, German, Hindi, Bengali, and Urdu. Furthermore, we incorporate timbre-aware speech synthesis to preserve speaker information, enabling DS2ST-LM to surpass prior direct S2ST systems in both speaker similarity and perceptual naturalness.
Fairness of Automatic Speech Recognition in Cleft Lip and Palate Speech
May 06, 2025Speech produced by individuals with cleft lip and palate (CLP) is often highly nasalized and breathy due to structural anomalies, causing shifts in formant structure that affect automatic speech recognition (ASR) performance and fairness. This study hypothesizes that publicly available ASR systems exhibit reduced fairness for CLP speech and confirms this through experiments. Despite formant disruptions, mild and moderate CLP speech retains some spectro-temporal alignment with normal speech, motivating augmentation strategies to enhance fairness. The study systematically explores augmenting CLP speech with normal speech across severity levels and evaluates its impact on ASR fairness. Three ASR models-GMM-HMM, Whisper, and XLS-R-were tested on AIISH and NMCPC datasets. Results indicate that training with normal speech and testing on mixed data improves word error rate (WER). Notably, WER decreased from $22.64\%$ to $18.76\%$ (GMM-HMM, AIISH) and $28.45\%$ to $18.89\%$ (Whisper, NMCPC). The superior performance of GMM-HMM on AIISH may be due to its suitability for Kannada children's speech, a challenge for foundation models like XLS-R and Whisper. To assess fairness, a fairness score was introduced, revealing improvements of $17.89\%$ (AIISH) and $47.50\%$ (NMCPC) with augmentation.
Biometrics in Extended Reality: A Review
Nov 14, 2024In the domain of Extended Reality (XR), particularly Virtual Reality (VR), extensive research has been devoted to harnessing this transformative technology in various real-world applications. However, a critical challenge that must be addressed before unleashing the full potential of XR in practical scenarios is to ensure robust security and safeguard user privacy. This paper presents a systematic survey of the utility of biometric characteristics applied in the XR environment. To this end, we present a comprehensive overview of the different types of biometric modalities used for authentication and representation of users in a virtual environment. We discuss different biometric vulnerability gateways in general XR systems for the first time in the literature along with taxonomy. A comprehensive discussion on generating and authenticating biometric-based photorealistic avatars in XR environments is presented with a stringent taxonomy. We also discuss the availability of different datasets that are widely employed in evaluating biometric authentication in XR environments together with performance evaluation metrics. Finally, we discuss the open challenges and potential future work that need to be addressed in the field of biometrics in XR.
Avengers Assemble: Amalgamation of Non-Semantic Features for Depression Detection
Sep 22, 2024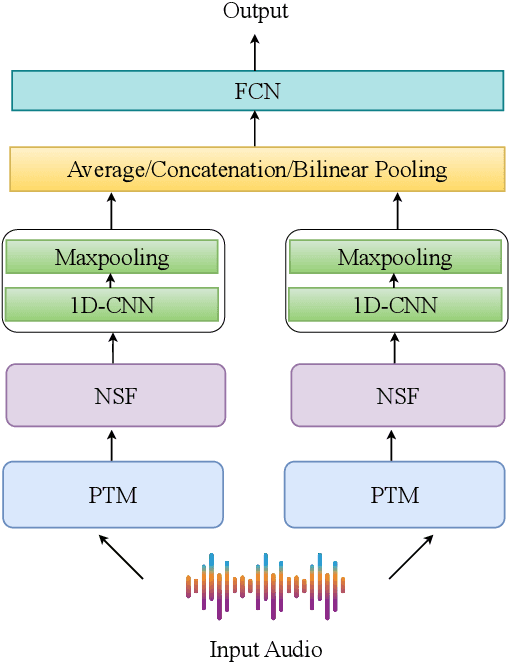
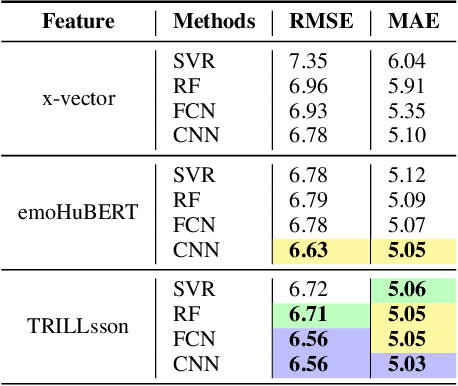
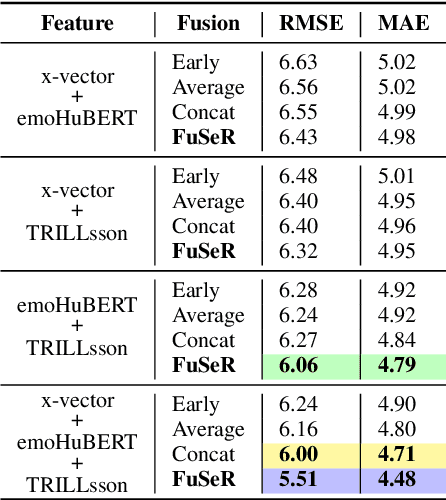
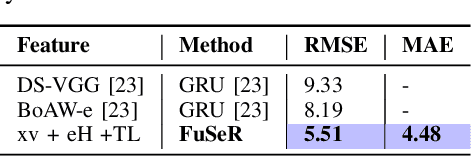
In this study, we address the challenge of depression detection from speech, focusing on the potential of non-semantic features (NSFs) to capture subtle markers of depression. While prior research has leveraged various features for this task, NSFs-extracted from pre-trained models (PTMs) designed for non-semantic tasks such as paralinguistic speech processing (TRILLsson), speaker recognition (x-vector), and emotion recognition (emoHuBERT)-have shown significant promise. However, the potential of combining these diverse features has not been fully explored. In this work, we demonstrate that the amalgamation of NSFs results in complementary behavior, leading to enhanced depression detection performance. Furthermore, to our end, we introduce a simple novel framework, FuSeR, designed to effectively combine these features. Our results show that FuSeR outperforms models utilizing individual NSFs as well as baseline fusion techniques and obtains state-of-the-art (SOTA) performance in E-DAIC benchmark with RMSE of 5.51 and MAE of 4.48, establishing it as a robust approach for depression detection.
The Second DISPLACE Challenge : DIarization of SPeaker and LAnguage in Conversational Environments
Jun 13, 2024



The DIarization of SPeaker and LAnguage in Conversational Environments (DISPLACE) 2024 challenge is the second in the series of DISPLACE challenges, which involves tasks of speaker diarization (SD) and language diarization (LD) on a challenging multilingual conversational speech dataset. In the DISPLACE 2024 challenge, we also introduced the task of automatic speech recognition (ASR) on this dataset. The dataset containing 158 hours of speech, consisting of both supervised and unsupervised mono-channel far-field recordings, was released for LD and SD tracks. Further, 12 hours of close-field mono-channel recordings were provided for the ASR track conducted on 5 Indian languages. The details of the dataset, baseline systems and the leader board results are highlighted in this paper. We have also compared our baseline models and the team's performances on evaluation data of DISPLACE-2023 to emphasize the advancements made in this second version of the challenge.
Implicit Self-supervised Language Representation for Spoken Language Diarization
Aug 21, 2023



In a code-switched (CS) scenario, the use of spoken language diarization (LD) as a pre-possessing system is essential. Further, the use of implicit frameworks is preferable over the explicit framework, as it can be easily adapted to deal with low/zero resource languages. Inspired by speaker diarization (SD) literature, three frameworks based on (1) fixed segmentation, (2) change point-based segmentation and (3) E2E are proposed to perform LD. The initial exploration with synthetic TTSF-LD dataset shows, using x-vector as implicit language representation with appropriate analysis window length ($N$) can able to achieve at per performance with explicit LD. The best implicit LD performance of $6.38$ in terms of Jaccard error rate (JER) is achieved by using the E2E framework. However, considering the E2E framework the performance of implicit LD degrades to $60.4$ while using with practical Microsoft CS (MSCS) dataset. The difference in performance is mostly due to the distributional difference between the monolingual segment duration of secondary language in the MSCS and TTSF-LD datasets. Moreover, to avoid segment smoothing, the smaller duration of the monolingual segment suggests the use of a small value of $N$. At the same time with small $N$, the x-vector representation is unable to capture the required language discrimination due to the acoustic similarity, as the same speaker is speaking both languages. Therefore, to resolve the issue a self-supervised implicit language representation is proposed in this study. In comparison with the x-vector representation, the proposed representation provides a relative improvement of $63.9\%$ and achieved a JER of $21.8$ using the E2E framework.
Implicit spoken language diarization
Jun 22, 2023



Spoken language diarization (LD) and related tasks are mostly explored using the phonotactic approach. Phonotactic approaches mostly use explicit way of language modeling, hence requiring intermediate phoneme modeling and transcribed data. Alternatively, the ability of deep learning approaches to model temporal dynamics may help for the implicit modeling of language information through deep embedding vectors. Hence this work initially explores the available speaker diarization frameworks that capture speaker information implicitly to perform LD tasks. The performance of the LD system on synthetic code-switch data using the end-to-end x-vector approach is 6.78% and 7.06%, and for practical data is 22.50% and 60.38%, in terms of diarization error rate and Jaccard error rate (JER), respectively. The performance degradation is due to the data imbalance and resolved to some extent by using pre-trained wave2vec embeddings that provide a relative improvement of 30.74% in terms of JER.
I-MSV 2022: Indic-Multilingual and Multi-sensor Speaker Verification Challenge
Feb 26, 2023Speaker Verification (SV) is a task to verify the claimed identity of the claimant using his/her voice sample. Though there exists an ample amount of research in SV technologies, the development concerning a multilingual conversation is limited. In a country like India, almost all the speakers are polyglot in nature. Consequently, the development of a Multilingual SV (MSV) system on the data collected in the Indian scenario is more challenging. With this motivation, the Indic- Multilingual Speaker Verification (I-MSV) Challenge 2022 has been designed for understanding and comparing the state-of-the-art SV techniques. For the challenge, approximately $100$ hours of data spoken by $100$ speakers has been collected using $5$ different sensors in $13$ Indian languages. The data is divided into development, training, and testing sets and has been made publicly available for further research. The goal of this challenge is to make the SV system robust to language and sensor variations between enrollment and testing. In the challenge, participants were asked to develop the SV system in two scenarios, viz. constrained and unconstrained. The best system in the constrained and unconstrained scenario achieved a performance of $2.12\%$ and $0.26\%$ in terms of Equal Error Rate (EER), respectively.
Spoken language change detection inspired by speaker change detection
Feb 10, 2023Spoken language change detection (LCD) refers to identifying the language transitions in a code-switched utterance. Similarly, identifying the speaker transitions in a multispeaker utterance is known as speaker change detection (SCD). Since tasks-wise both are similar, the architecture/framework developed for the SCD task may be suitable for the LCD task. Hence, the aim of the present work is to develop LCD systems inspired by SCD. Initially, both LCD and SCD are performed by humans. The study suggests humans require (a) a larger duration around the change point and (b) language-specific prior exposure, for performing LCD as compared to SCD. The larger duration requirement is incorporated by increasing the analysis window length of the unsupervised distance-based approach. This leads to a relative performance improvement of 29.1% and 2.4%, and a priori language knowledge provides a relative improvement of 31.63% and 14.27% on the synthetic and practical codeswitched datasets, respectively. The performance difference between the practical and synthetic datasets is mostly due to differences in the distribution of the monolingual segment duration.
Language vs Speaker Change: A Comparative Study
Mar 05, 2022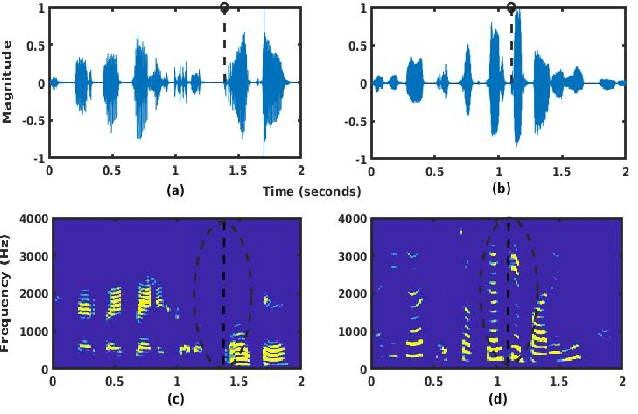
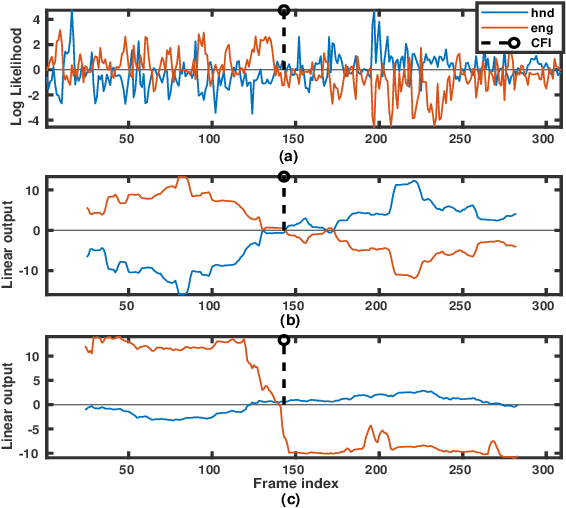
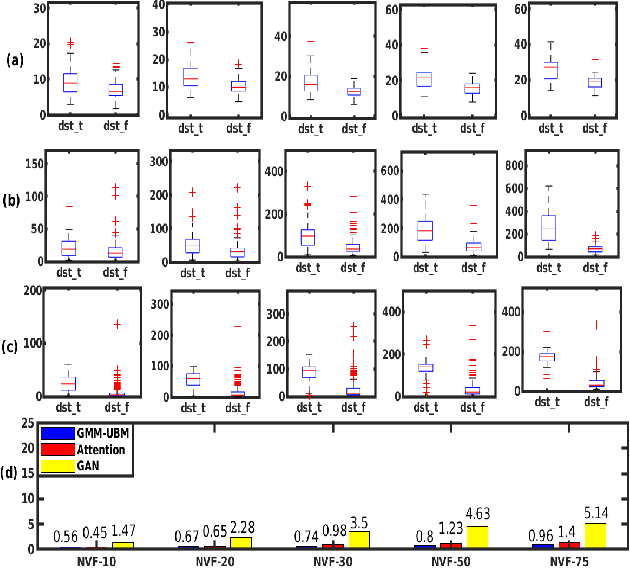
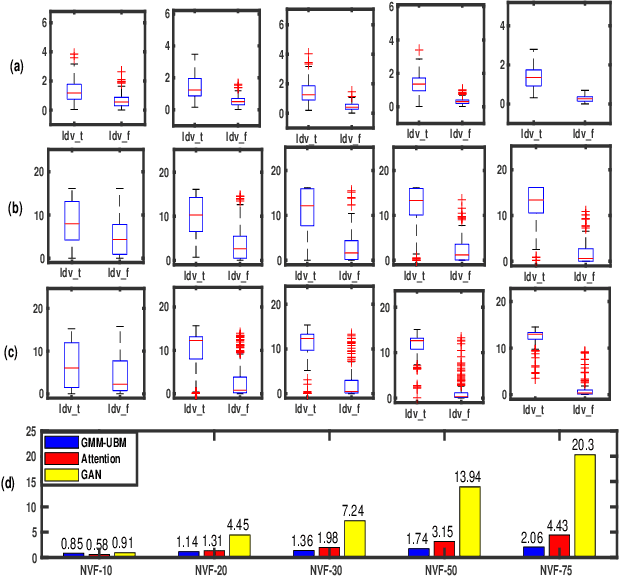
Spoken language change detection (LCD) refers to detecting language switching points in a multilingual speech signal. Speaker change detection (SCD) refers to locating the speaker change points in a multispeaker speech signal. The objective of this work is to understand the challenges in LCD task by comparing it with SCD task. Human subjective study for change detection is performed for LCD and SCD. This study demonstrates that LCD requires larger duration spectro-temporal information around the change point compared to SCD. Based on this, the work explores automatic distance based and model based LCD approaches. The model based ones include Gaussian mixture model and universal background model (GMM-UBM), attention, and Generative adversarial network (GAN) based approaches. Both the human and automatic LCD tasks infer that the performance of the LCD task improves by incorporating more and more spectro-temporal duration.