 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvengers Assemble: Amalgamation of Non-Semantic Features for Depression Detection
Paper and Code
Sep 22, 2024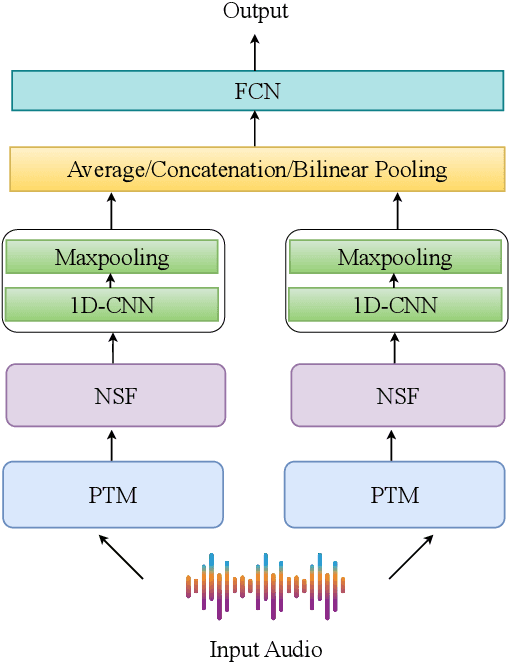
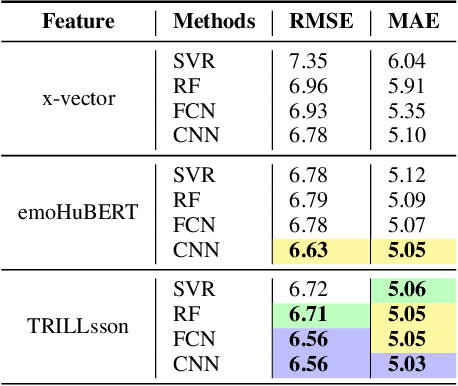
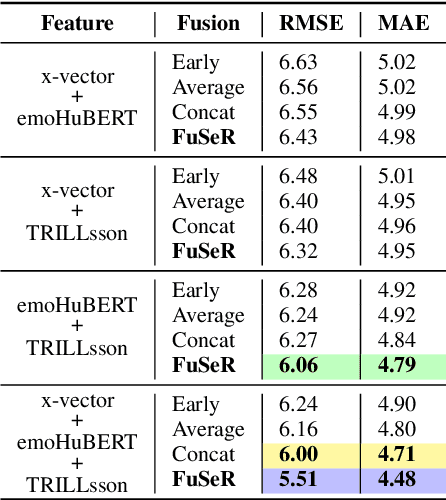
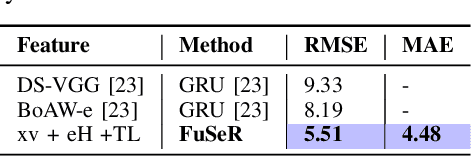
In this study, we address the challenge of depression detection from speech, focusing on the potential of non-semantic features (NSFs) to capture subtle markers of depression. While prior research has leveraged various features for this task, NSFs-extracted from pre-trained models (PTMs) designed for non-semantic tasks such as paralinguistic speech processing (TRILLsson), speaker recognition (x-vector), and emotion recognition (emoHuBERT)-have shown significant promise. However, the potential of combining these diverse features has not been fully explored. In this work, we demonstrate that the amalgamation of NSFs results in complementary behavior, leading to enhanced depression detection performance. Furthermore, to our end, we introduce a simple novel framework, FuSeR, designed to effectively combine these features. Our results show that FuSeR outperforms models utilizing individual NSFs as well as baseline fusion techniques and obtains state-of-the-art (SOTA) performance in E-DAIC benchmark with RMSE of 5.51 and MAE of 4.48, establishing it as a robust approach for depression detection.