 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Speech Systems for Frontline Health Conversations: The DISPLACE-M Challenge
Mar 05, 2026The DIarization and Speech Processing for LAnguage understanding in Conversational Environments - Medical (DISPLACE-M) challenge introduces a conversational AI benchmark for understanding goal-oriented, real-world medical dialogues. The challenge addresses multi-speaker interactions between frontline health workers and care seekers, characterized by spontaneous, noisy and overlapping speech. As part of the challenge, medical conversational dataset comprising 40 hours of development and 15 hours of blind evaluation recordings was released. We provided baseline systems across 4 tasks - speaker diarization, automatic speech recognition, topic identification and dialogue summarization - to enable consistent benchmarking. System performance is evaluated using diarization error rate (DER), time-constrained minimum-permutation word error rate (tcpWER) and ROUGE-L. This paper describes the Phase-I evaluation - data, tasks and baseline systems - along with the summary of the evaluation results.
The Second DISPLACE Challenge : DIarization of SPeaker and LAnguage in Conversational Environments
Jun 13, 2024



The DIarization of SPeaker and LAnguage in Conversational Environments (DISPLACE) 2024 challenge is the second in the series of DISPLACE challenges, which involves tasks of speaker diarization (SD) and language diarization (LD) on a challenging multilingual conversational speech dataset. In the DISPLACE 2024 challenge, we also introduced the task of automatic speech recognition (ASR) on this dataset. The dataset containing 158 hours of speech, consisting of both supervised and unsupervised mono-channel far-field recordings, was released for LD and SD tracks. Further, 12 hours of close-field mono-channel recordings were provided for the ASR track conducted on 5 Indian languages. The details of the dataset, baseline systems and the leader board results are highlighted in this paper. We have also compared our baseline models and the team's performances on evaluation data of DISPLACE-2023 to emphasize the advancements made in this second version of the challenge.
Summary of the DISPLACE Challenge 2023 -- DIarization of SPeaker and LAnguage in Conversational Environments
Nov 23, 2023In multi-lingual societies, where multiple languages are spoken in a small geographic vicinity, informal conversations often involve mix of languages. Existing speech technologies may be inefficient in extracting information from such conversations, where the speech data is rich in diversity with multiple languages and speakers. The DISPLACE (DIarization of SPeaker and LAnguage in Conversational Environments) challenge constitutes an open-call for evaluating and bench-marking the speaker and language diarization technologies on this challenging condition. The challenge entailed two tracks: Track-1 focused on speaker diarization (SD) in multilingual situations while, Track-2 addressed the language diarization (LD) in a multi-speaker scenario. Both the tracks were evaluated using the same underlying audio data. To facilitate this evaluation, a real-world dataset featuring multilingual, multi-speaker conversational far-field speech was recorded and distributed. Furthermore, a baseline system was made available for both SD and LD task which mimicked the state-of-art in these tasks. The challenge garnered a total of $42$ world-wide registrations and received a total of $19$ combined submissions for Track-1 and Track-2. This paper describes the challenge, details of the datasets, tasks, and the baseline system. Additionally, the paper provides a concise overview of the submitted systems in both tracks, with an emphasis given to the top performing systems. The paper also presents insights and future perspectives for SD and LD tasks, focusing on the key challenges that the systems need to overcome before wide-spread commercial deployment on such conversations.
DISPLACE Challenge: DIarization of SPeaker and LAnguage in Conversational Environments
Mar 01, 2023The DISPLACE challenge entails a first-of-kind task to perform speaker and language diarization on the same data, as the data contains multi-speaker social conversations in multilingual code-mixed speech. The challenge attempts to benchmark and improve Speaker Diarization (SD) in multilingual settings and Language Diarization (LD) in multi-speaker settings. For this challenge, a natural multilingual, multi-speaker conversational dataset is distributed for development and evaluation purposes. Automatic systems are evaluated on single-channel far-field recordings containing natural code-mix, code-switch, overlap, reverberation, short turns, short pauses, and multiple dialects of the same language. A total of 60 teams from industry and academia have registered for this challenge.
Semi-Automatic Labeling and Semantic Segmentation of Gram-Stained Microscopic Images from DIBaS Dataset
Aug 23, 2022
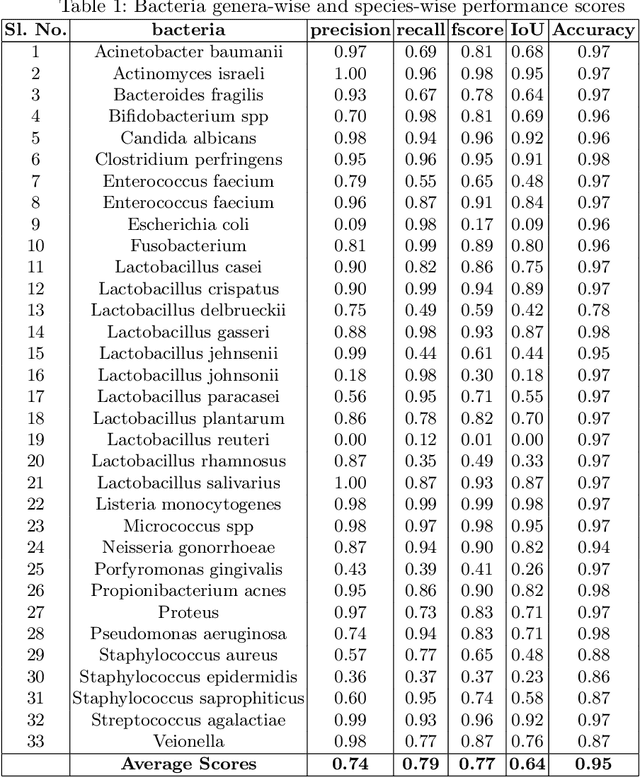

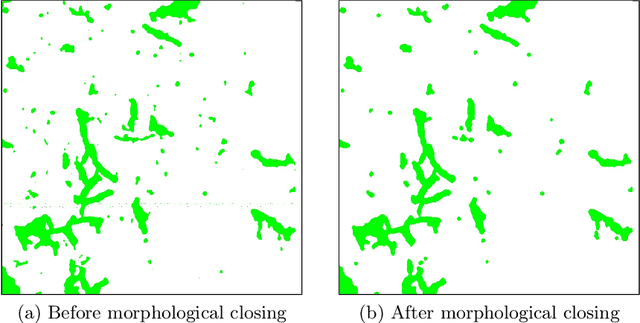
In this paper, a semi-automatic annotation of bacteria genera and species from DIBaS dataset is implemented using clustering and thresholding algorithms. A Deep learning model is trained to achieve the semantic segmentation and classification of the bacteria species. Classification accuracy of 95% is achieved. Deep learning models find tremendous applications in biomedical image processing. Automatic segmentation of bacteria from gram-stained microscopic images is essential to diagnose respiratory and urinary tract infections, detect cancers, etc. Deep learning will aid the biologists to get reliable results in less time. Additionally, a lot of human intervention can be reduced. This work can be helpful to detect bacteria from urinary smear images, sputum smear images, etc to diagnose urinary tract infections, tuberculosis, pneumonia, etc.
COVID-19 Patient Detection from Telephone Quality Speech Data
Nov 09, 2020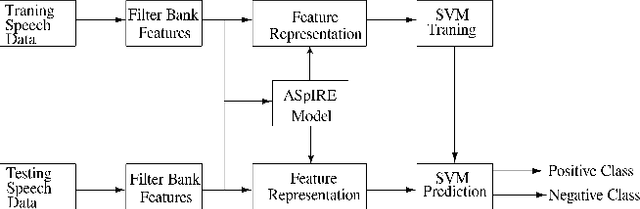
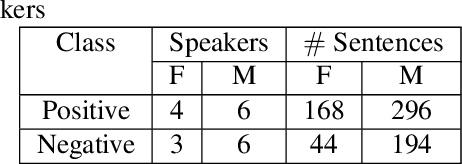
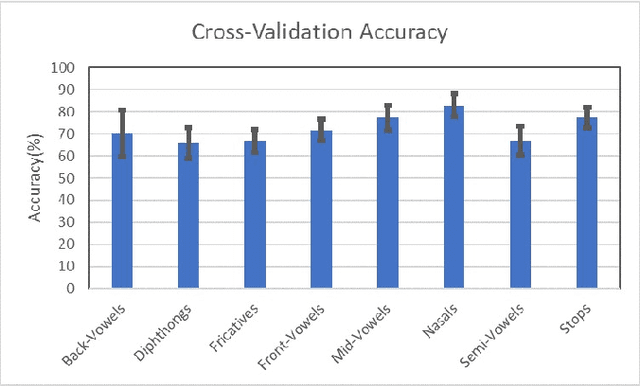
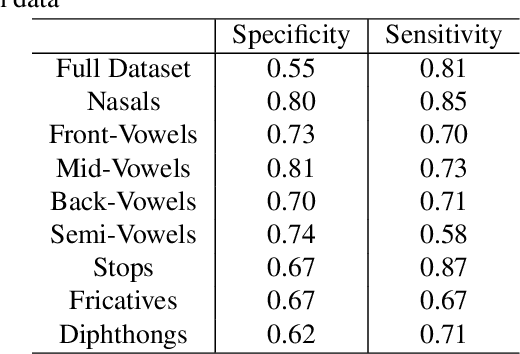
In this paper, we try to investigate the presence of cues about the COVID-19 disease in the speech data. We use an approach that is similar to speaker recognition. Each sentence is represented as super vectors of short term Mel filter bank features for each phoneme. These features are used to learn a two-class classifier to separate the COVID-19 speech from normal. Experiments on a small dataset collected from YouTube videos show that an SVM classifier on this dataset is able to achieve an accuracy of 88.6% and an F1-Score of 92.7%. Further investigation reveals that some phone classes, such as nasals, stops, and mid vowels can distinguish the two classes better than the others.
NISP: A Multi-lingual Multi-accent Dataset for Speaker Profiling
Jul 12, 2020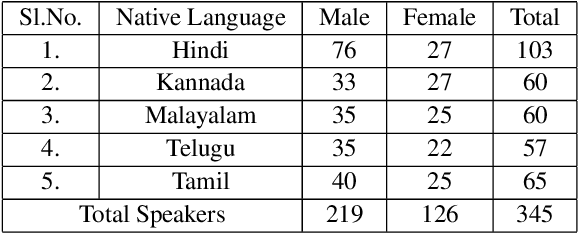
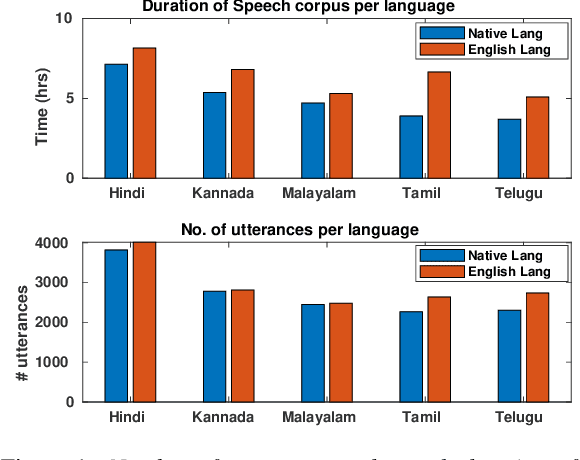
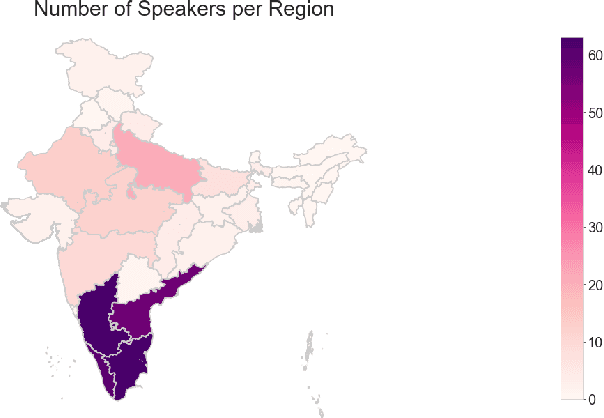
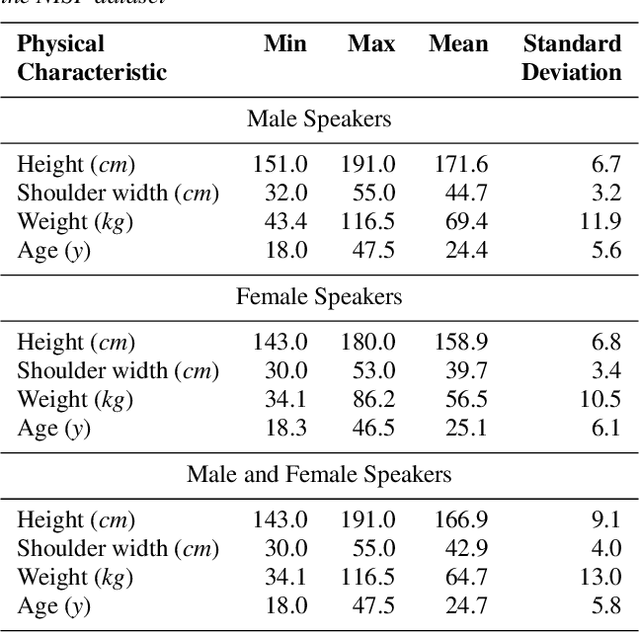
Many commercial and forensic applications of speech demand the extraction of information about the speaker characteristics, which falls into the broad category of speaker profiling. The speaker characteristics needed for profiling include physical traits of the speaker like height, age, and gender of the speaker along with the native language of the speaker. Many of the datasets available have only partial information for speaker profiling. In this paper, we attempt to overcome this limitation by developing a new dataset which has speech data from five different Indian languages along with English. The metadata information for speaker profiling applications like linguistic information, regional information, and physical characteristics of a speaker are also collected. We call this dataset as NITK-IISc Multilingual Multi-accent Speaker Profiling (NISP) dataset. The description of the dataset, potential applications, and baseline results for speaker profiling on this dataset are provided in this paper.
Implicit segmentation of Kannada characters in offline handwriting recognition using hidden Markov models
Oct 16, 2014
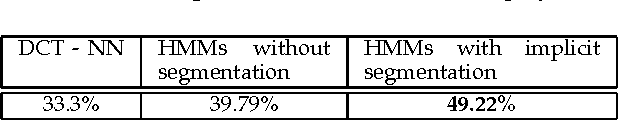
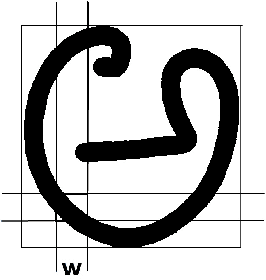
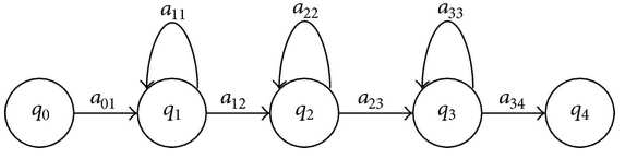
We describe a method for classification of handwritten Kannada characters using Hidden Markov Models (HMMs). Kannada script is agglutinative, where simple shapes are concatenated horizontally to form a character. This results in a large number of characters making the task of classification difficult. Character segmentation plays a significant role in reducing the number of classes. Explicit segmentation techniques suffer when overlapping shapes are present, which is common in the case of handwritten text. We use HMMs to take advantage of the agglutinative nature of Kannada script, which allows us to perform implicit segmentation of characters along with recognition. All the experiments are performed on the Chars74k dataset that consists of 657 handwritten characters collected across multiple users. Gradient-based features are extracted from individual characters and are used to train character HMMs. The use of implicit segmentation technique at the character level resulted in an improvement of around 10%. This system also outperformed an existing system tested on the same dataset by around 16%. Analysis based on learning curves showed that increasing the training data could result in better accuracy. Accordingly, we collected additional data and obtained an improvement of 4% with 6 additional samples.