 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional Bilateral Filters
Oct 27, 2014

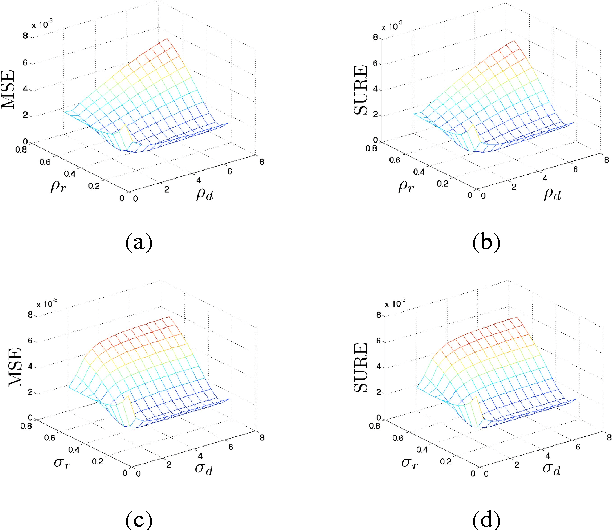
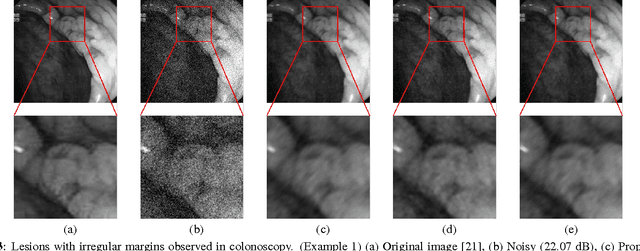
We propose a bilateral filter with a locally controlled domain kernel for directional edge-preserving smoothing. Traditional bilateral filters use a range kernel, which is responsible for edge preservation, and a fixed domain kernel that performs smoothing. Our intuition is that orientation and anisotropy of image structures should be incorporated into the domain kernel while smoothing. For this purpose, we employ an oriented Gaussian domain kernel locally controlled by a structure tensor. The oriented domain kernel combined with a range kernel forms the directional bilateral filter. The two kernels assist each other in effectively suppressing the influence of the outliers while smoothing. To find the optimal parameters of the directional bilateral filter, we propose the use of Stein's unbiased risk estimate (SURE). We test the capabilities of the kernels separately as well as together, first on synthetic images, and then on real endoscopic images. The directional bilateral filter has better denoising performance than the Gaussian bilateral filter at various noise levels in terms of peak signal-to-noise ratio (PSNR).
Implicit segmentation of Kannada characters in offline handwriting recognition using hidden Markov models
Oct 16, 2014
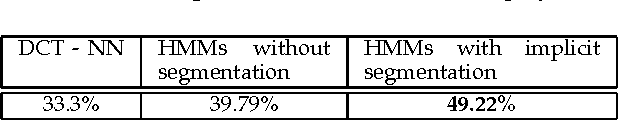
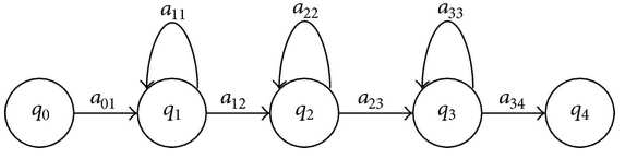
We describe a method for classification of handwritten Kannada characters using Hidden Markov Models (HMMs). Kannada script is agglutinative, where simple shapes are concatenated horizontally to form a character. This results in a large number of characters making the task of classification difficult. Character segmentation plays a significant role in reducing the number of classes. Explicit segmentation techniques suffer when overlapping shapes are present, which is common in the case of handwritten text. We use HMMs to take advantage of the agglutinative nature of Kannada script, which allows us to perform implicit segmentation of characters along with recognition. All the experiments are performed on the Chars74k dataset that consists of 657 handwritten characters collected across multiple users. Gradient-based features are extracted from individual characters and are used to train character HMMs. The use of implicit segmentation technique at the character level resulted in an improvement of around 10%. This system also outperformed an existing system tested on the same dataset by around 16%. Analysis based on learning curves showed that increasing the training data could result in better accuracy. Accordingly, we collected additional data and obtained an improvement of 4% with 6 additional samples.