 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummary of the DISPLACE Challenge 2023 -- DIarization of SPeaker and LAnguage in Conversational Environments
Nov 23, 2023In multi-lingual societies, where multiple languages are spoken in a small geographic vicinity, informal conversations often involve mix of languages. Existing speech technologies may be inefficient in extracting information from such conversations, where the speech data is rich in diversity with multiple languages and speakers. The DISPLACE (DIarization of SPeaker and LAnguage in Conversational Environments) challenge constitutes an open-call for evaluating and bench-marking the speaker and language diarization technologies on this challenging condition. The challenge entailed two tracks: Track-1 focused on speaker diarization (SD) in multilingual situations while, Track-2 addressed the language diarization (LD) in a multi-speaker scenario. Both the tracks were evaluated using the same underlying audio data. To facilitate this evaluation, a real-world dataset featuring multilingual, multi-speaker conversational far-field speech was recorded and distributed. Furthermore, a baseline system was made available for both SD and LD task which mimicked the state-of-art in these tasks. The challenge garnered a total of $42$ world-wide registrations and received a total of $19$ combined submissions for Track-1 and Track-2. This paper describes the challenge, details of the datasets, tasks, and the baseline system. Additionally, the paper provides a concise overview of the submitted systems in both tracks, with an emphasis given to the top performing systems. The paper also presents insights and future perspectives for SD and LD tasks, focusing on the key challenges that the systems need to overcome before wide-spread commercial deployment on such conversations.
DISPLACE Challenge: DIarization of SPeaker and LAnguage in Conversational Environments
Mar 01, 2023The DISPLACE challenge entails a first-of-kind task to perform speaker and language diarization on the same data, as the data contains multi-speaker social conversations in multilingual code-mixed speech. The challenge attempts to benchmark and improve Speaker Diarization (SD) in multilingual settings and Language Diarization (LD) in multi-speaker settings. For this challenge, a natural multilingual, multi-speaker conversational dataset is distributed for development and evaluation purposes. Automatic systems are evaluated on single-channel far-field recordings containing natural code-mix, code-switch, overlap, reverberation, short turns, short pauses, and multiple dialects of the same language. A total of 60 teams from industry and academia have registered for this challenge.
DiCOVA Challenge: Dataset, task, and baseline system for COVID-19 diagnosis using acoustics
Apr 05, 2021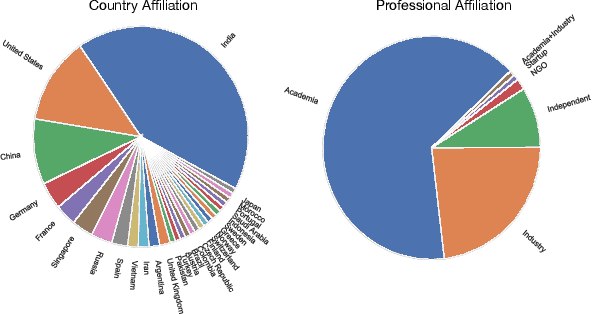
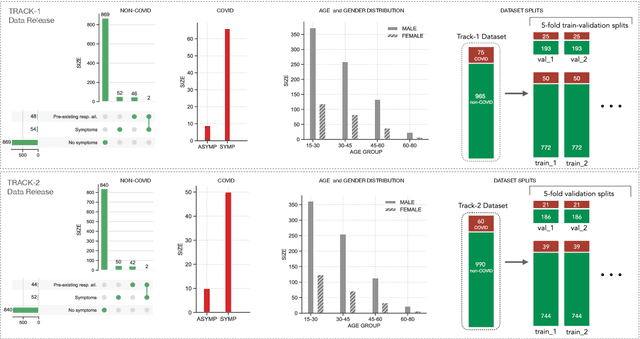
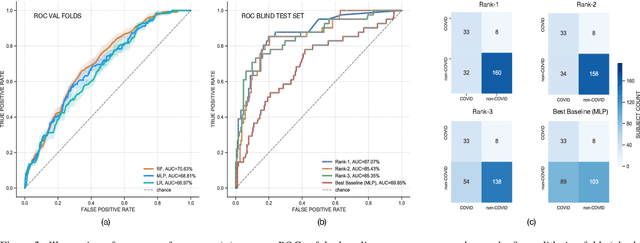
The DiCOVA challenge aims at accelerating research in diagnosing COVID-19 using acoustics (DiCOVA), a topic at the intersection of speech and audio processing, respiratory health diagnosis, and machine learning. This challenge is an open call for researchers to analyze a dataset of sound recordings collected from COVID-19 infected and non-COVID-19 individuals for a two-class classification. These recordings were collected via crowdsourcing from multiple countries, through a website application. The challenge features two tracks, one focusing on cough sounds, and the other on using a collection of breath, sustained vowel phonation, and number counting speech recordings. In this paper, we introduce the challenge and provide a detailed description of the task, and present a baseline system for the task.
Neural PLDA Modeling for End-to-End Speaker Verification
Aug 11, 2020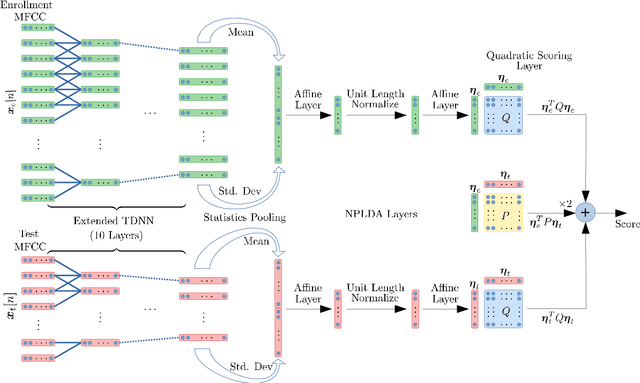
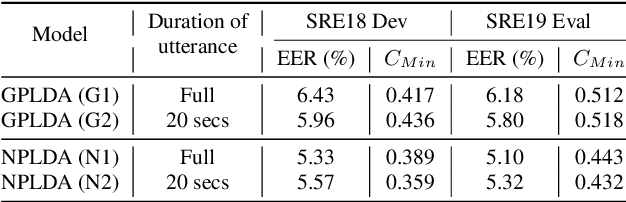

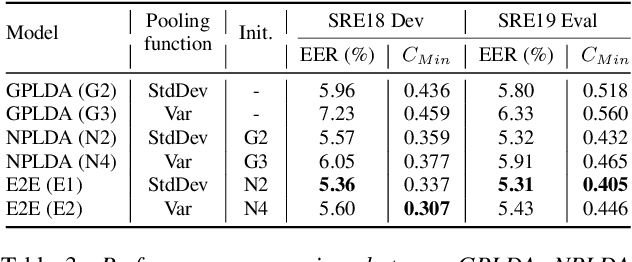
While deep learning models have made significant advances in supervised classification problems, the application of these models for out-of-set verification tasks like speaker recognition has been limited to deriving feature embeddings. The state-of-the-art x-vector PLDA based speaker verification systems use a generative model based on probabilistic linear discriminant analysis (PLDA) for computing the verification score. Recently, we had proposed a neural network approach for backend modeling in speaker verification called the neural PLDA (NPLDA) where the likelihood ratio score of the generative PLDA model is posed as a discriminative similarity function and the learnable parameters of the score function are optimized using a verification cost. In this paper, we extend this work to achieve joint optimization of the embedding neural network (x-vector network) with the NPLDA network in an end-to-end (E2E) fashion. This proposed end-to-end model is optimized directly from the acoustic features with a verification cost function and during testing, the model directly outputs the likelihood ratio score. With various experiments using the NIST speaker recognition evaluation (SRE) 2018 and 2019 datasets, we show that the proposed E2E model improves significantly over the x-vector PLDA baseline speaker verification system.
NPLDA: A Deep Neural PLDA Model for Speaker Verification
Feb 10, 2020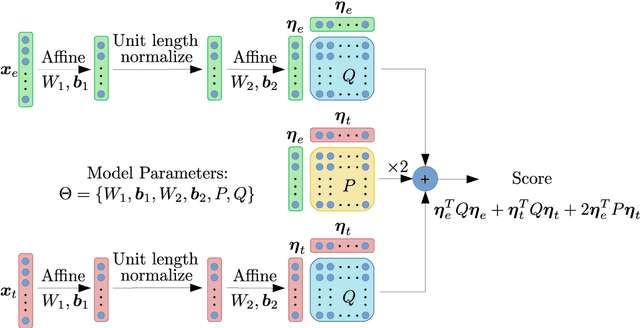

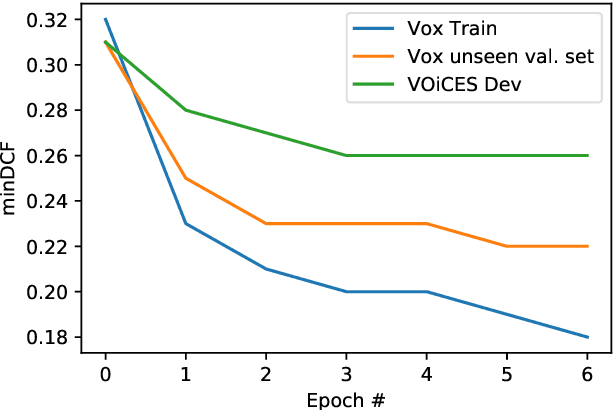
The state-of-art approach for speaker verification consists of a neural network based embedding extractor along with a backend generative model such as the Probabilistic Linear Discriminant Analysis (PLDA). In this work, we propose a neural network approach for backend modeling in speaker recognition. The likelihood ratio score of the generative PLDA model is posed as a discriminative similarity function and the learnable parameters of the score function are optimized using a verification cost. The proposed model, termed as neural PLDA (NPLDA), is initialized using the generative PLDA model parameters. The loss function for the NPLDA model is an approximation of the minimum detection cost function (DCF). The speaker recognition experiments using the NPLDA model are performed on the speaker verificiation task in the VOiCES datasets as well as the SITW challenge dataset. In these experiments, the NPLDA model optimized using the proposed loss function improves significantly over the state-of-art PLDA based speaker verification system.
LEAP System for SRE19 Challenge -- Improvements and Error Analysis
Feb 07, 2020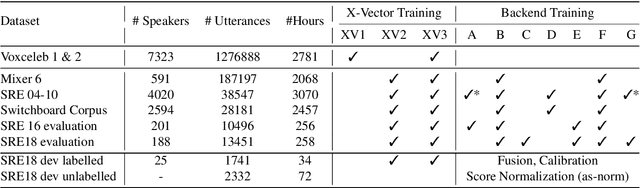

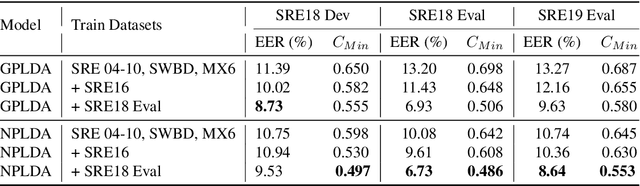
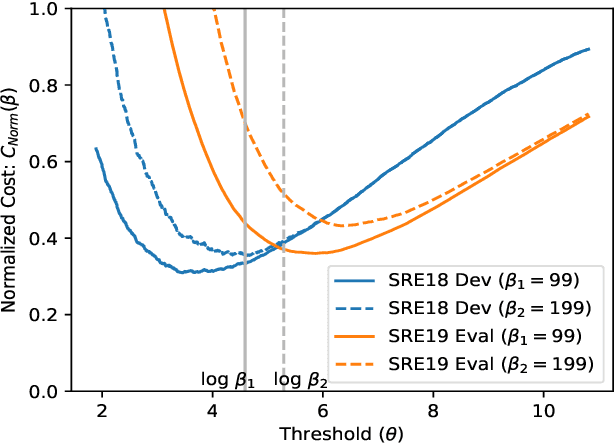
The NIST Speaker Recognition Evaluation - Conversational Telephone Speech (CTS) challenge 2019 was an open evaluation for the task of speaker verification in challenging conditions. In this paper, we provide a detailed account of the LEAP SRE system submitted to the CTS challenge focusing on the novel components in the back-end system modeling. All the systems used the time-delay neural network (TDNN) based x-vector embeddings. The x-vector system in our SRE19 submission used a large pool of training speakers (about 14k speakers). Following the x-vector extraction, we explored a neural network approach to backend score computation that was optimized for a speaker verification cost. The system combination of generative and neural PLDA models resulted in significant improvements for the SRE evaluation dataset. We also found additional gains for the SRE systems based on score normalization and calibration. Subsequent to the evaluations, we have performed a detailed analysis of the submitted systems. The analysis revealed the incremental gains obtained for different training dataset combinations as well as the modeling methods.
Pairwise Discriminative Neural PLDA for Speaker Verification
Feb 07, 2020

The state-of-art approach to speaker verification involves the extraction of discriminative embeddings like x-vectors followed by a generative model back-end using a probabilistic linear discriminant analysis (PLDA). In this paper, we propose a Pairwise neural discriminative model for the task of speaker verification which operates on a pair of speaker embeddings such as x-vectors/i-vectors and outputs a score that can be considered as a scaled log-likelihood ratio. We construct a differentiable cost function which approximates speaker verification loss, namely the minimum detection cost. The pre-processing steps of linear discriminant analysis (LDA), unit length normalization and within class covariance normalization are all modeled as layers of a neural model and the speaker verification cost functions can be back-propagated through these layers during training. We also explore regularization techniques to prevent overfitting, which is a major concern in using discriminative back-end models for verification tasks. The experiments are performed on the NIST SRE 2018 development and evaluation datasets. We observe average relative improvements of 8% in CMN2 condition and 30% in VAST condition over the PLDA baseline system.