 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiCOVA Challenge: Dataset, task, and baseline system for COVID-19 diagnosis using acoustics
Paper and Code
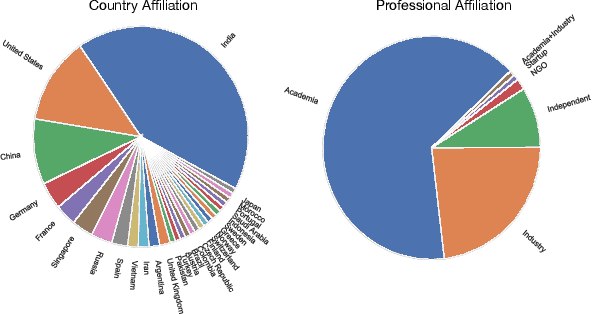
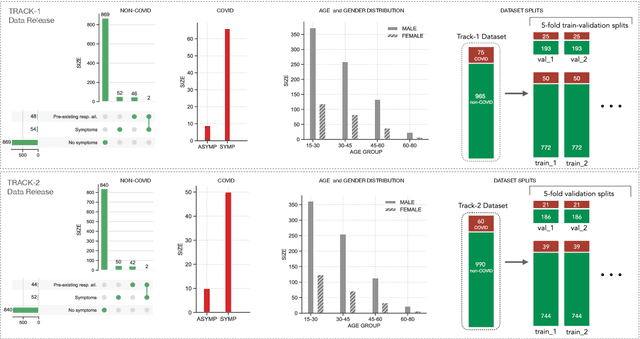
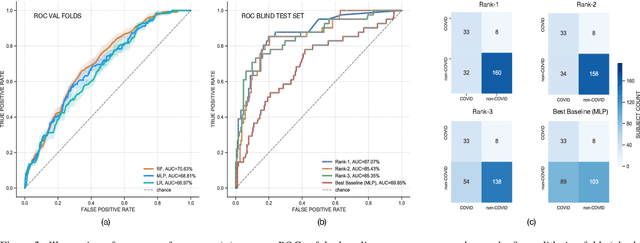
The DiCOVA challenge aims at accelerating research in diagnosing COVID-19 using acoustics (DiCOVA), a topic at the intersection of speech and audio processing, respiratory health diagnosis, and machine learning. This challenge is an open call for researchers to analyze a dataset of sound recordings collected from COVID-19 infected and non-COVID-19 individuals for a two-class classification. These recordings were collected via crowdsourcing from multiple countries, through a website application. The challenge features two tracks, one focusing on cough sounds, and the other on using a collection of breath, sustained vowel phonation, and number counting speech recordings. In this paper, we introduce the challenge and provide a detailed description of the task, and present a baseline system for the task.