 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Speech Systems for Frontline Health Conversations: The DISPLACE-M Challenge
Mar 05, 2026The DIarization and Speech Processing for LAnguage understanding in Conversational Environments - Medical (DISPLACE-M) challenge introduces a conversational AI benchmark for understanding goal-oriented, real-world medical dialogues. The challenge addresses multi-speaker interactions between frontline health workers and care seekers, characterized by spontaneous, noisy and overlapping speech. As part of the challenge, medical conversational dataset comprising 40 hours of development and 15 hours of blind evaluation recordings was released. We provided baseline systems across 4 tasks - speaker diarization, automatic speech recognition, topic identification and dialogue summarization - to enable consistent benchmarking. System performance is evaluated using diarization error rate (DER), time-constrained minimum-permutation word error rate (tcpWER) and ROUGE-L. This paper describes the Phase-I evaluation - data, tasks and baseline systems - along with the summary of the evaluation results.
Neural Directional Filtering Using a Compact Microphone Array
Nov 18, 2025Beamforming with desired directivity patterns using compact microphone arrays is essential in many audio applications. Directivity patterns achievable using traditional beamformers depend on the number of microphones and the array aperture. Generally, their effectiveness degrades for compact arrays. To overcome these limitations, we propose a neural directional filtering (NDF) approach that leverages deep neural networks to enable sound capture with a predefined directivity pattern. The NDF computes a single-channel complex mask from the microphone array signals, which is then applied to a reference microphone to produce an output that approximates a virtual directional microphone with the desired directivity pattern. We introduce training strategies and propose data-dependent metrics to evaluate the directivity pattern and directivity factor. We show that the proposed method: i) achieves a frequency-invariant directivity pattern even above the spatial aliasing frequency, ii) can approximate diverse and higher-order patterns, iii) can steer the pattern in different directions, and iv) generalizes to unseen conditions. Lastly, experimental comparisons demonstrate superior performance over conventional beamforming and parametric approaches.
Training Strategies for Modality Dropout Resilient Multi-Modal Target Speaker Extraction
Jul 09, 2025The primary goal of multi-modal TSE (MTSE) is to extract a target speaker from a speech mixture using complementary information from different modalities, such as audio enrolment and visual feeds corresponding to the target speaker. MTSE systems are expected to perform well even when one of the modalities is unavailable. In practice, the systems often suffer from modality dominance, where one of the modalities outweighs the others, thereby limiting robustness. Our study investigates training strategies and the effect of architectural choices, particularly the normalization layers, in yielding a robust MTSE system in both non-causal and causal configurations. In particular, we propose the use of modality dropout training (MDT) as a superior strategy to standard and multi-task training (MTT) strategies. Experiments conducted on two-speaker mixtures from the LRS3 dataset show the MDT strategy to be effective irrespective of the employed normalization layer. In contrast, the models trained with the standard and MTT strategies are susceptible to modality dominance, and their performance depends on the chosen normalization layer. Additionally, we demonstrate that the system trained with MDT strategy is robust to using extracted speech as the enrollment signal, highlighting its potential applicability in scenarios where the target speaker is not enrolled.
Dynamic Slimmable Networks for Efficient Speech Separation
Jul 08, 2025Recent progress in speech separation has been largely driven by advances in deep neural networks, yet their high computational and memory requirements hinder deployment on resource-constrained devices. A significant inefficiency in conventional systems arises from using static network architectures that maintain constant computational complexity across all input segments, regardless of their characteristics. This approach is sub-optimal for simpler segments that do not require intensive processing, such as silence or non-overlapping speech. To address this limitation, we propose a dynamic slimmable network (DSN) for speech separation that adaptively adjusts its computational complexity based on the input signal. The DSN combines a slimmable network, which can operate at different network widths, with a lightweight gating module that dynamically determines the required width by analyzing the local input characteristics. To balance performance and efficiency, we introduce a signal-dependent complexity loss that penalizes unnecessary computation based on segmental reconstruction error. Experiments on clean and noisy two-speaker mixtures from the WSJ0-2mix and WHAM! datasets show that the DSN achieves a better performance-efficiency trade-off than individually trained static networks of different sizes.
Low-Complexity Neural Wind Noise Reduction for Audio Recordings
Jul 02, 2025Wind noise significantly degrades the quality of outdoor audio recordings, yet remains difficult to suppress in real-time on resource-constrained devices. In this work, we propose a low-complexity single-channel deep neural network that leverages the spectral characteristics of wind noise. Experimental results show that our method achieves performance comparable to the state-of-the-art low-complexity ULCNet model. The proposed model, with only 249K parameters and roughly 73 MHz of computational power, is suitable for embedded and mobile audio applications.
Coswara: A respiratory sounds and symptoms dataset for remote screening of SARS-CoV-2 infection
May 22, 2023This paper presents the Coswara dataset, a dataset containing diverse set of respiratory sounds and rich meta-data, recorded between April-2020 and February-2022 from 2635 individuals (1819 SARS-CoV-2 negative, 674 positive, and 142 recovered subjects). The respiratory sounds contained nine sound categories associated with variants of breathing, cough and speech. The rich metadata contained demographic information associated with age, gender and geographic location, as well as the health information relating to the symptoms, pre-existing respiratory ailments, comorbidity and SARS-CoV-2 test status. Our study is the first of its kind to manually annotate the audio quality of the entire dataset (amounting to 65~hours) through manual listening. The paper summarizes the data collection procedure, demographic, symptoms and audio data information. A COVID-19 classifier based on bi-directional long short-term (BLSTM) architecture, is trained and evaluated on the different population sub-groups contained in the dataset to understand the bias/fairness of the model. This enabled the analysis of the impact of gender, geographic location, date of recording, and language proficiency on the COVID-19 detection performance.
Beamformer-Guided Target Speaker Extraction
Mar 15, 2023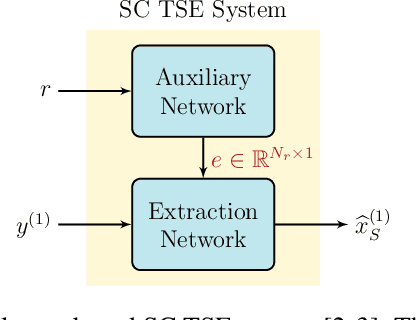
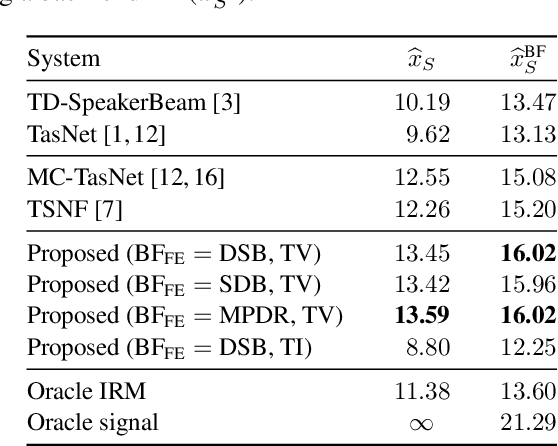
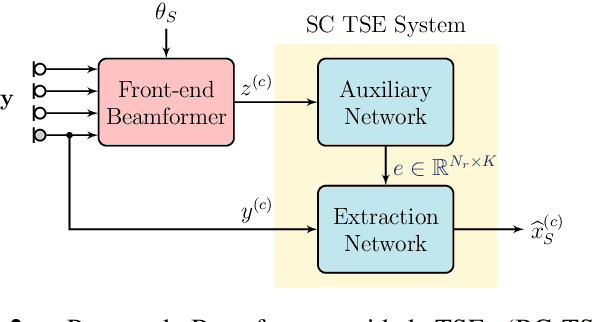
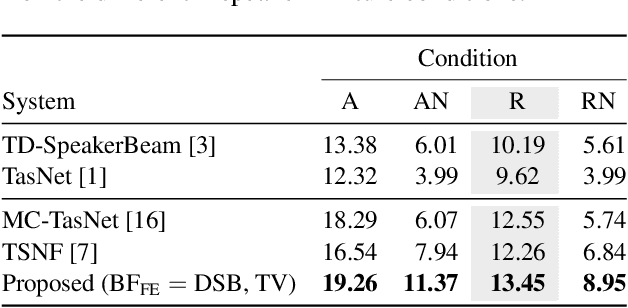
We propose a Beamformer-guided Target Speaker Extraction (BG-TSE) method to extract a target speaker's voice from a multi-channel recording informed by the direction of arrival of the target. The proposed method employs a front-end beamformer steered towards the target speaker to provide an auxiliary signal to a single-channel TSE system. By allowing for time-varying embeddings in the single-channel TSE block, the proposed method fully exploits the correspondence between the front-end beamformer output and the target speech in the microphone signal. Experimental evaluation on simulated multi-channel 2-speaker mixtures, in both anechoic and reverberant conditions, demonstrates the advantage of the proposed method compared to recent single-channel and multi-channel baselines.
Multi-Microphone Speaker Separation by Spatial Regions
Mar 13, 2023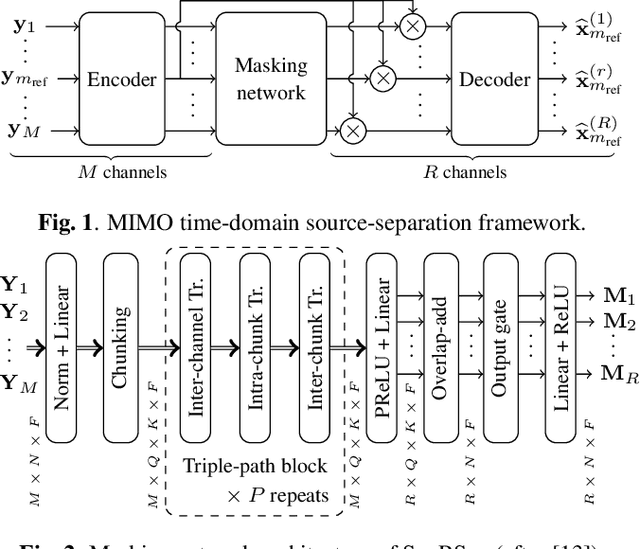
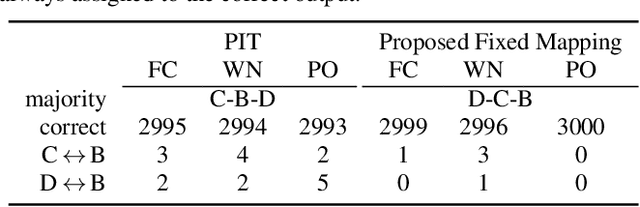

We consider the task of region-based source separation of reverberant multi-microphone recordings. We assume pre-defined spatial regions with a single active source per region. The objective is to estimate the signals from the individual spatial regions as captured by a reference microphone while retaining a correspondence between signals and spatial regions. We propose a data-driven approach using a modified version of a state-of-the-art network, where different layers model spatial and spectro-temporal information. The network is trained to enforce a fixed mapping of regions to network outputs. Using speech from LibriMix, we construct a data set specifically designed to contain the region information. Additionally, we train the network with permutation invariant training. We show that both training methods result in a fixed mapping of regions to network outputs, achieve comparable performance, and that the networks exploit spatial information. The proposed network outperforms a baseline network by 1.5 dB in scale-invariant signal-to-distortion ratio.
Analyzing the impact of SARS-CoV-2 variants on respiratory sound signals
Jun 24, 2022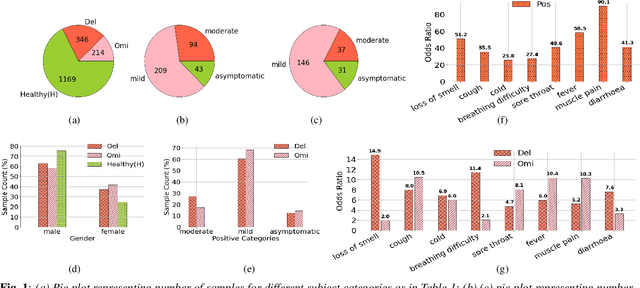
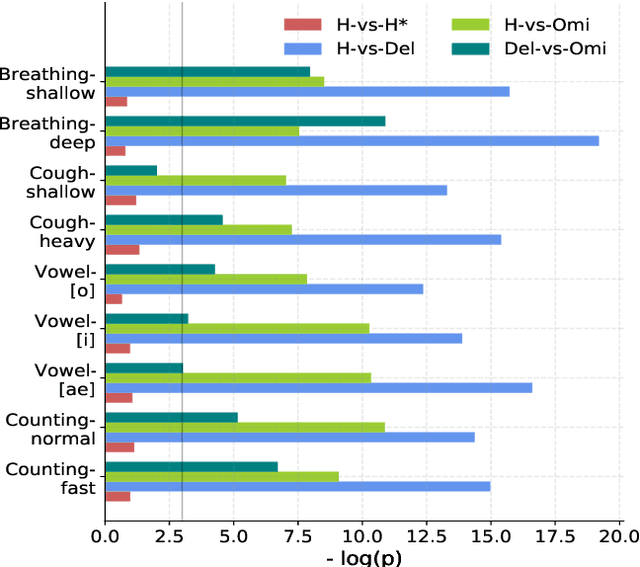
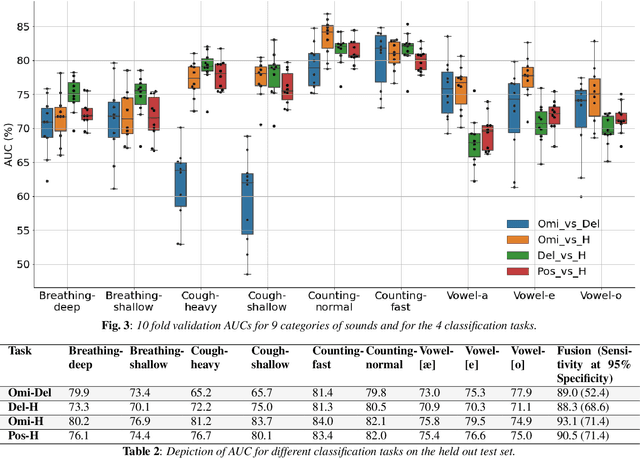
The COVID-19 outbreak resulted in multiple waves of infections that have been associated with different SARS-CoV-2 variants. Studies have reported differential impact of the variants on respiratory health of patients. We explore whether acoustic signals, collected from COVID-19 subjects, show computationally distinguishable acoustic patterns suggesting a possibility to predict the underlying virus variant. We analyze the Coswara dataset which is collected from three subject pools, namely, i) healthy, ii) COVID-19 subjects recorded during the delta variant dominant period, and iii) data from COVID-19 subjects recorded during the omicron surge. Our findings suggest that multiple sound categories, such as cough, breathing, and speech, indicate significant acoustic feature differences when comparing COVID-19 subjects with omicron and delta variants. The classification areas-under-the-curve are significantly above chance for differentiating subjects infected by omicron from those infected by delta. Using a score fusion from multiple sound categories, we obtained an area-under-the-curve of 89% and 52.4% sensitivity at 95% specificity. Additionally, a hierarchical three class approach was used to classify the acoustic data into healthy and COVID-19 positive, and further COVID-19 subjects into delta and omicron variants providing high level of 3-class classification accuracy. These results suggest new ways for designing sound based COVID-19 diagnosis approaches.
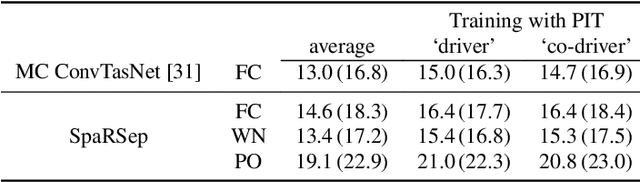
AmbiSep: Ambisonic-to-Ambisonic Reverberant Speech Separation Using Transformer Networks
Jun 13, 2022
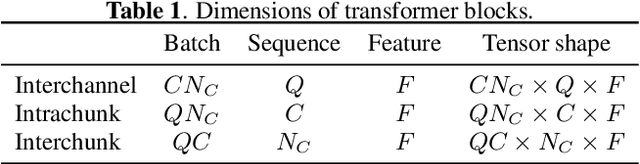
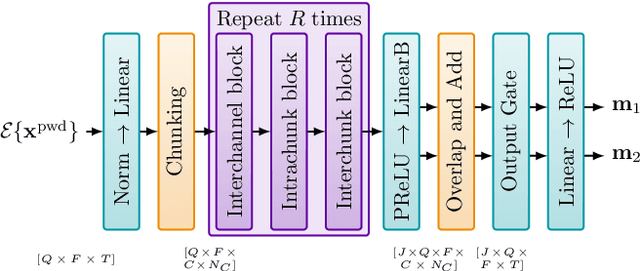

Consider a multichannel Ambisonic recording containing a mixture of several reverberant speech signals. Retreiving the reverberant Ambisonic signals corresponding to the individual speech sources blindly from the mixture is a challenging task as it requires to estimate multiple signal channels for each source. In this work, we propose AmbiSep, a deep neural network-based plane-wave domain masking approach to solve this task. The masking network uses learned feature representations and transformers in a triple-path processing configuration. We train and evaluate the proposed network architecture on a spatialized WSJ0-2mix dataset, and show that the method achieves a multichannel scale-invariant signal-to-distortion ratio improvement of 17.7 dB on the blind test set, while preserving the spatial characteristics of the separated sounds.