 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Audio Classification by Transitioning from Zero- to Few-Shot
Jul 26, 2025State-of-the-art audio classification often employs a zero-shot approach, which involves comparing audio embeddings with embeddings from text describing the respective audio class. These embeddings are usually generated by neural networks trained through contrastive learning to align audio and text representations. Identifying the optimal text description for an audio class is challenging, particularly when the class comprises a wide variety of sounds. This paper examines few-shot methods designed to improve classification accuracy beyond the zero-shot approach. Specifically, audio embeddings are grouped by class and processed to replace the inherently noisy text embeddings. Our results demonstrate that few-shot classification typically outperforms the zero-shot baseline.
Efficient Evaluation of Quantization-Effects in Neural Codecs
Feb 07, 2025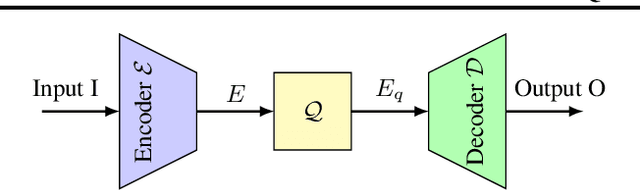
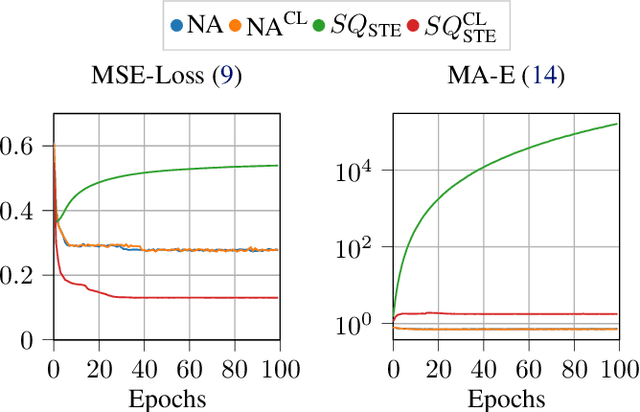
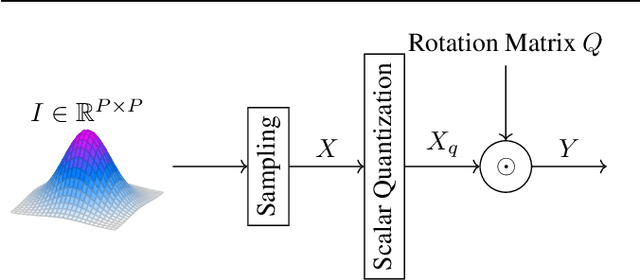
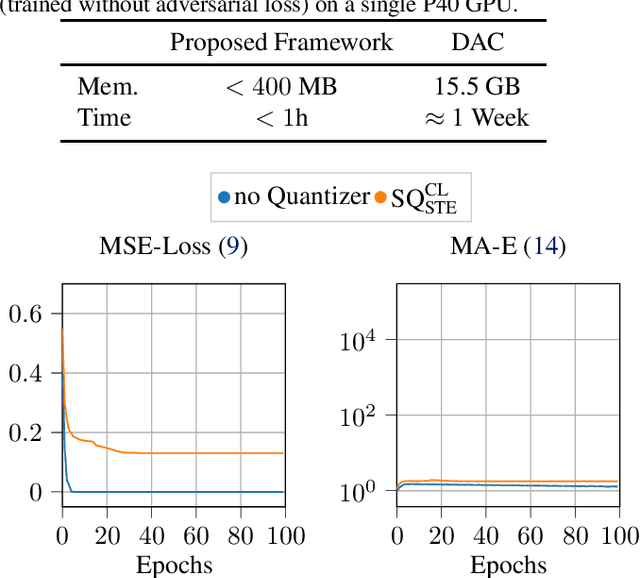
Neural codecs, comprising an encoder, quantizer, and decoder, enable signal transmission at exceptionally low bitrates. Training these systems requires techniques like the straight-through estimator, soft-to-hard annealing, or statistical quantizer emulation to allow a non-zero gradient across the quantizer. Evaluating the effect of quantization in neural codecs, like the influence of gradient passing techniques on the whole system, is often costly and time-consuming due to training demands and the lack of affordable and reliable metrics. This paper proposes an efficient evaluation framework for neural codecs using simulated data with a defined number of bits and low-complexity neural encoders/decoders to emulate the non-linear behavior in larger networks. Our system is highly efficient in terms of training time and computational and hardware requirements, allowing us to uncover distinct behaviors in neural codecs. We propose a modification to stabilize training with the straight-through estimator based on our findings. We validate our findings against an internal neural audio codec and against the state-of-the-art descript-audio-codec.
Align-ULCNet: Towards Low-Complexity and Robust Acoustic Echo and Noise Reduction
Oct 17, 2024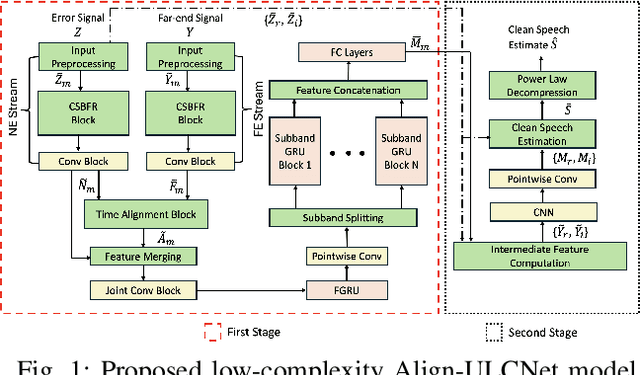
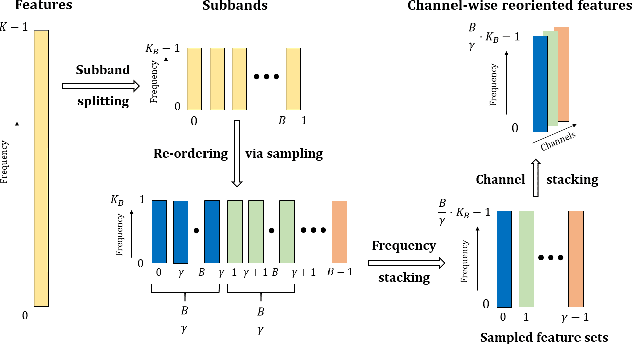
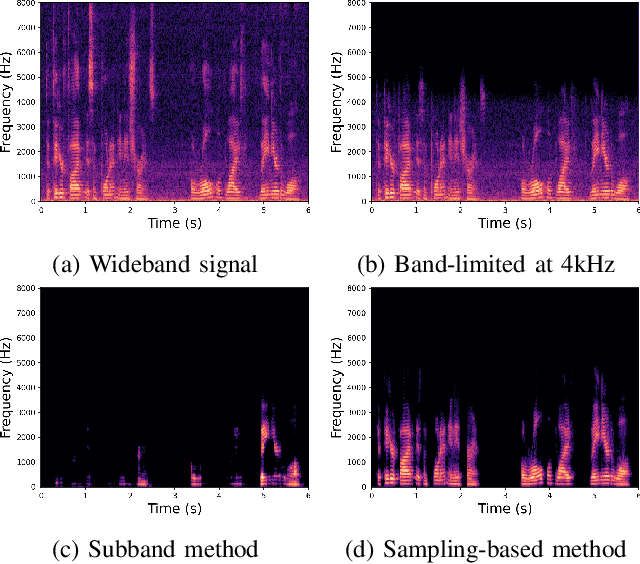
The successful deployment of deep learning-based acoustic echo and noise reduction (AENR) methods in consumer devices has spurred interest in developing low-complexity solutions, while emphasizing the need for robust performance in real-life applications. In this work, we propose a hybrid approach to enhance the state-of-the-art (SOTA) ULCNet model by integrating time alignment and parallel encoder blocks for the model inputs, resulting in better echo reduction and comparable noise reduction performance to existing SOTA methods. We also propose a channel-wise sampling-based feature reorientation method, ensuring robust performance across many challenging scenarios, while maintaining overall low computational and memory requirements.
Inference-Adaptive Neural Steering for Real-Time Area-Based Sound Source Separation
Aug 23, 2024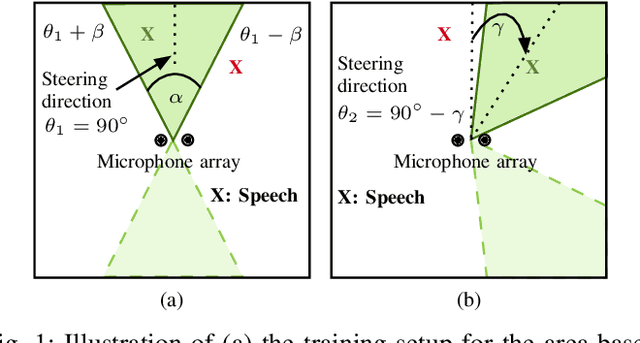
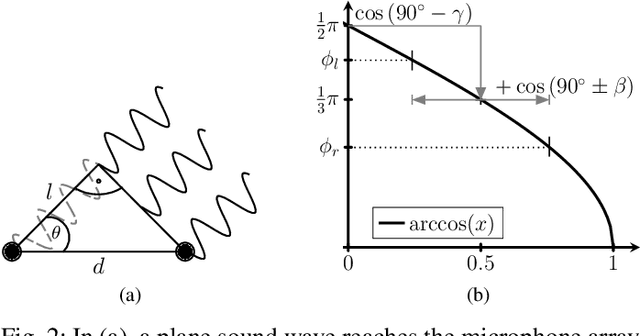
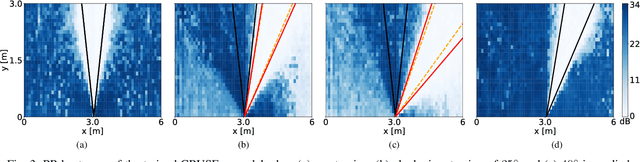
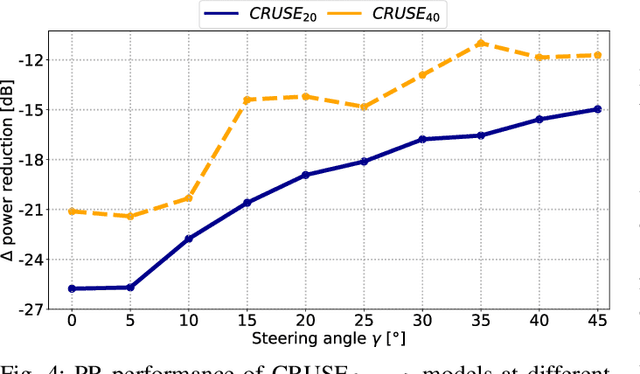
We propose a novel Neural Steering technique that adapts the target area of a spatial-aware multi-microphone sound source separation algorithm during inference without the necessity of retraining the deep neural network (DNN). To achieve this, we first train a DNN aiming to retain speech within a target region, defined by an angular span, while suppressing sound sources stemming from other directions. Afterward, a phase shift is applied to the microphone signals, allowing us to shift the center of the target area during inference at negligible additional cost in computational complexity. Further, we show that the proposed approach performs well in a wide variety of acoustic scenarios, including several speakers inside and outside the target area and additional noise. More precisely, the proposed approach performs on par with DNNs trained explicitly for the steered target area in terms of DNSMOS and SI-SDR.
Multi-Microphone Speaker Separation by Spatial Regions
Mar 13, 2023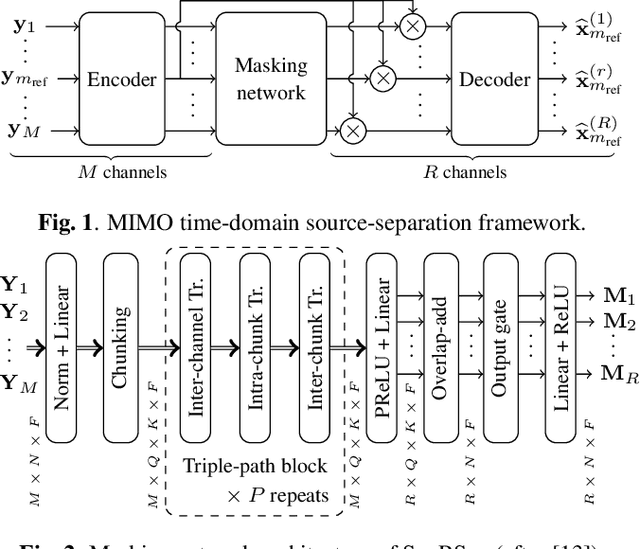
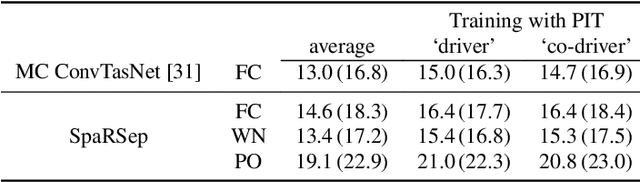
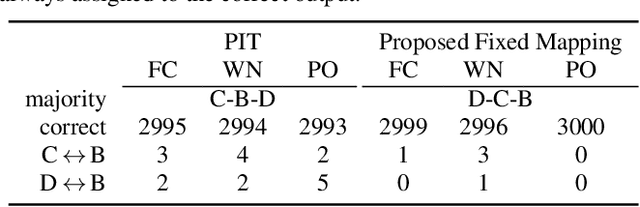

We consider the task of region-based source separation of reverberant multi-microphone recordings. We assume pre-defined spatial regions with a single active source per region. The objective is to estimate the signals from the individual spatial regions as captured by a reference microphone while retaining a correspondence between signals and spatial regions. We propose a data-driven approach using a modified version of a state-of-the-art network, where different layers model spatial and spectro-temporal information. The network is trained to enforce a fixed mapping of regions to network outputs. Using speech from LibriMix, we construct a data set specifically designed to contain the region information. Additionally, we train the network with permutation invariant training. We show that both training methods result in a fixed mapping of regions to network outputs, achieve comparable performance, and that the networks exploit spatial information. The proposed network outperforms a baseline network by 1.5 dB in scale-invariant signal-to-distortion ratio.
Speaker Verification in Multi-Speaker Environments Using Temporal Feature Fusion
Jun 28, 2022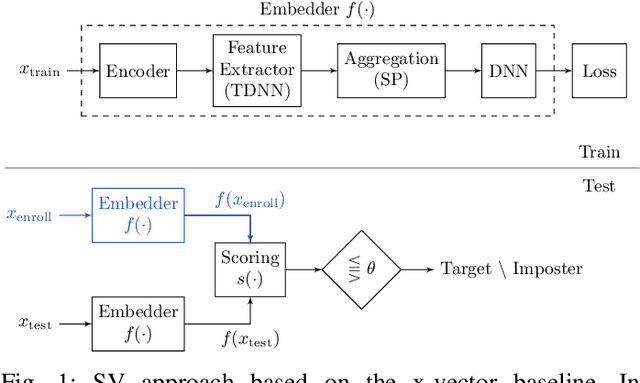
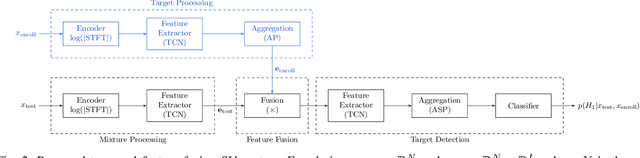
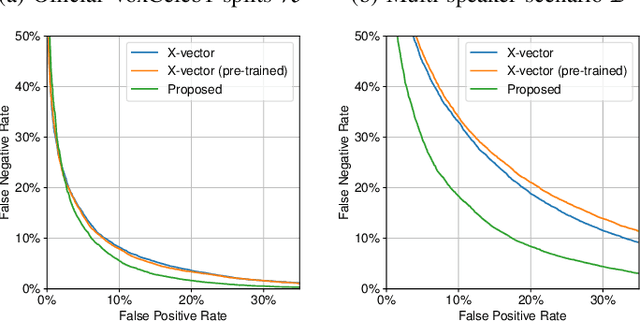
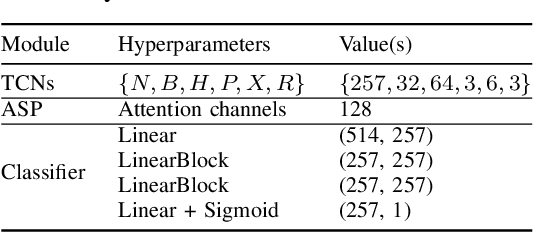
Verifying the identity of a speaker is crucial in modern human-machine interfaces, e.g., to ensure privacy protection or to enable biometric authentication. Classical speaker verification (SV) approaches estimate a fixed-dimensional embedding from a speech utterance that encodes the speaker's voice characteristics. A speaker is verified if his/her voice embedding is sufficiently similar to the embedding of the claimed speaker. However, such approaches assume that only a single speaker exists in the input. The presence of concurrent speakers is likely to have detrimental effects on the performance. To address SV in a multi-speaker environment, we propose an end-to-end deep learning-based SV system that detects whether the target speaker exists within an input or not. First, an embedding is estimated from a reference utterance to represent the target's characteristics. Second, frame-level features are estimated from the input mixture. The reference embedding is then fused frame-wise with the mixture's features to allow distinguishing the target from other speakers on a frame basis. Finally, the fused features are used to predict whether the target speaker is active in the speech segment or not. Experimental evaluation shows that the proposed method outperforms the x-vector in multi-speaker conditions.
New Insights on Target Speaker Extraction
Feb 01, 2022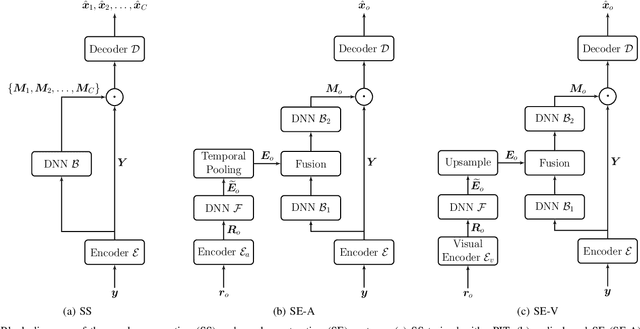
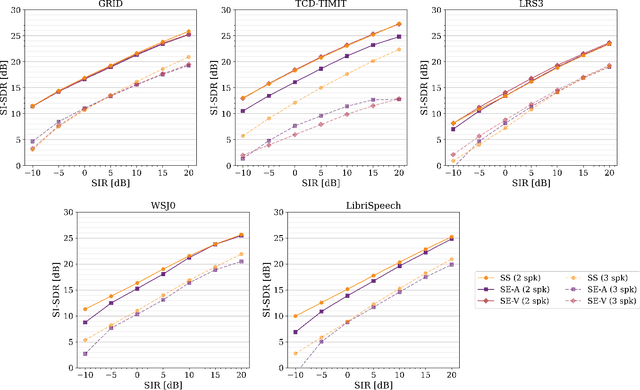
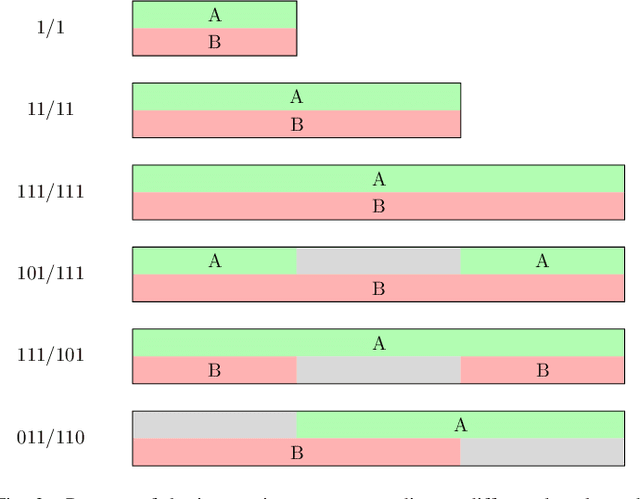
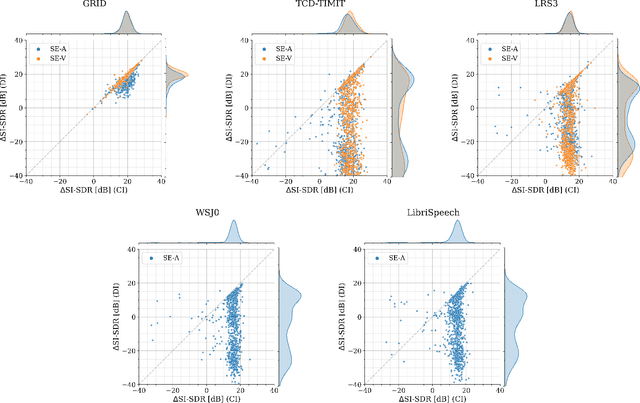
In recent years, researchers have become increasingly interested in speaker extraction (SE), which is the task of extracting the speech of a target speaker from a mixture of interfering speakers with the help of auxiliary information about the target speaker. Several forms of auxiliary information have been employed in single-channel SE, such as a speech snippet enrolled from the target speaker or visual information corresponding to the spoken utterance. Many SE studies have reported performance improvement compared to speaker separation (SS) methods with oracle selection, arguing that this is due to the use of auxiliary information. However, such works have not considered state-of-the-art SS methods that have shown impressive separation performance. In this paper, we revise and examine the role of the auxiliary information in SE. Specifically, we compare the performance of two SE systems (audio-based and video-based) with SS using a common framework that utilizes the state-of-the-art dual-path recurrent neural network as the main learning machine. In addition, we study how much the considered SE systems rely on the auxiliary information by analyzing the systems' output for random auxiliary signals. Experimental evaluation on various datasets suggests that the main purpose of the auxiliary information in the considered SE systems is only to specify the target speaker in the mixture and that it does not provide consistent extraction performance gain when compared to the uninformed SS system.
Signal-Aware Direction-of-Arrival Estimation Using Attention Mechanisms
Jan 03, 2022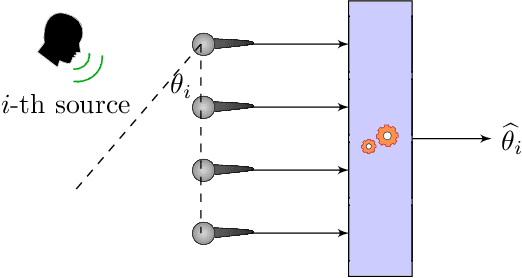
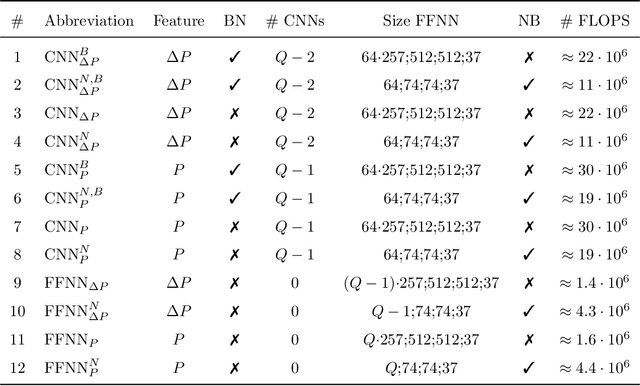
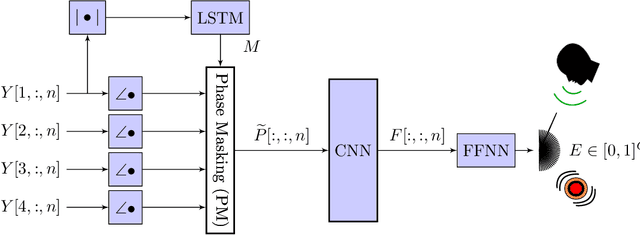

The direction-of-arrival (DOA) of sound sources is an essential acoustic parameter used, e.g., for multi-channel speech enhancement or source tracking. Complex acoustic scenarios consisting of sources-of-interest, interfering sources, reverberation, and noise make the estimation of the DOAs corresponding to the sources-of-interest a challenging task. Recently proposed attention mechanisms allow DOA estimators to focus on the sources-of-interest and disregard interference and noise, i.e., they are signal-aware. The attention is typically obtained by a deep neural network (DNN) from a short-time Fourier transform (STFT) based representation of a single microphone signal. Subsequently, attention has been applied as binary or ratio weighting to STFT-based microphone signal representations to reduce the impact of frequency bins dominated by noise, interference, or reverberation. The impact of attention on DOA estimators and different training strategies for attention and DOA DNNs are not yet studied in depth. In this paper, we evaluate systems consisting of different DNNs and signal processing-based methods for DOA estimation when attention is applied. Additionally, we propose training strategies for attention-based DOA estimation optimized via a DOA objective, i.e., end-to-end. The evaluation of the proposed and the baseline systems is performed using data generated with simulated and measured room impulse responses under various acoustic conditions, like reverberation times, noise, and source array distances. Overall, DOA estimation using attention in combination with signal-processing methods exhibits a far lower computational complexity than a fully DNN-based system; however, it yields comparable results.
Guided Source Separation
Nov 09, 2020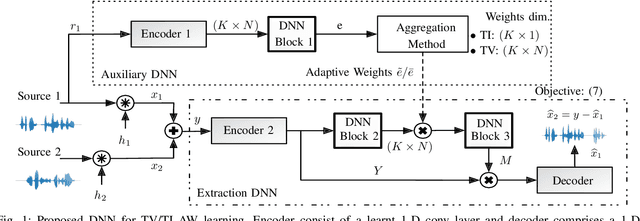
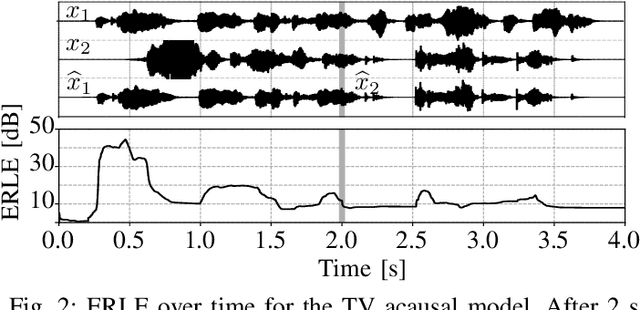

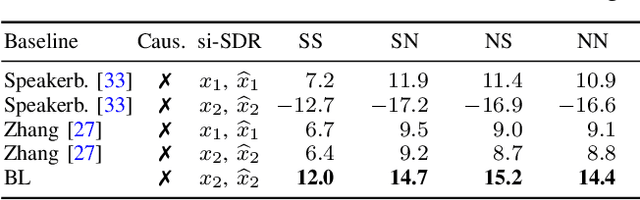
State-of-the-art separation of desired signal components from a mixture is achieved using time-frequency masks or filters estimated by a deep neural network (DNN). The desired components, thereby, are typically defined at the time of training. Recent approaches allow determining the desired components during inference via auxiliary information. Auxiliary information is, thereby, extracted from a reference snippet of the desired components by a second DNN, which estimates a set of adaptive weights (AW) of the first DNN. However, the AW methods require the reference snippet and the desired signal to exhibit time-invariant signal characteristics (SCs) and have only been applied for speaker separation. We show that these AW methods can be used for universal source separation and propose an AW method to extract time-variant auxiliary information from the reference signal. That way, the SCs are allowed to vary across time in the reference and mixture. Applications where the reference and desired signal cannot be assigned to a specific class and vary over time require a time-dependency. An example is acoustic echo cancellation, where the reference is the loudspeaker signal. To avoid strong scaling between the estimate and the mixture, we propose the dual scale-invariant signal-to-distortion ratio in a TASNET inspired DNN as the training objective. We evaluate the proposed AW systems using a wide range of different acoustic conditions and show the scenario dependent advantages of time-variant over time-invariant AW.
Efficient Training Data Generation for Phase-Based DOA Estimation
Nov 09, 2020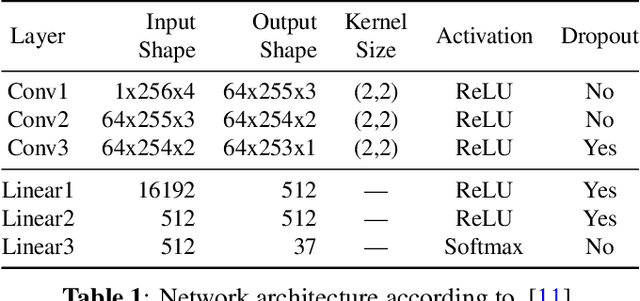
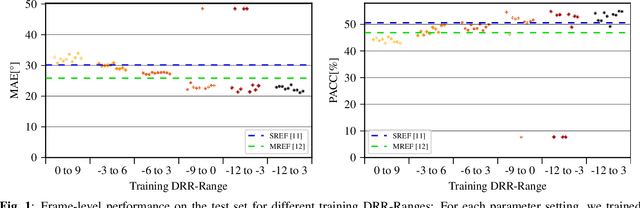
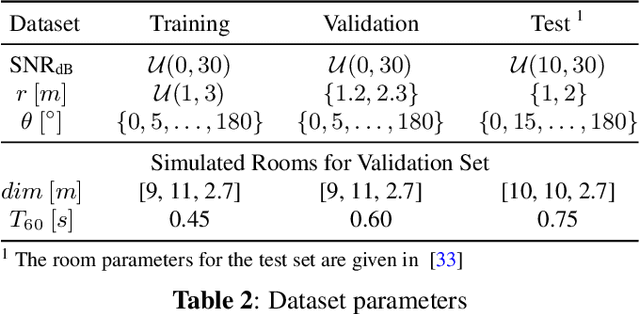
Deep learning (DL) based direction of arrival (DOA) estimation is an active research topic and currently represents the state-of-the-art. Usually, DL-based DOA estimators are trained with recorded data or computationally expensive generated data. Both data types require significant storage and excessive time to, respectively, record or generate. We propose a low complexity online data generation method to train DL models with a phase-based feature input. The data generation method models the phases of the microphone signals in the frequency domain by employing a deterministic model for the direct path and a statistical model for the late reverberation of the room transfer function. By an evaluation using data from measured room impulse responses, we demonstrate that a model trained with the proposed training data generation method performs comparably to models trained with data generated based on the source-image method.