 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Discriminative Latent Representations for Conditioning GAN-Based Speech Enhancement
Aug 28, 2025Generative speech enhancement methods based on generative adversarial networks (GANs) and diffusion models have shown promising results in various speech enhancement tasks. However, their performance in very low signal-to-noise ratio (SNR) scenarios remains under-explored and limited, as these conditions pose significant challenges to both discriminative and generative state-of-the-art methods. To address this, we propose a method that leverages latent features extracted from discriminative speech enhancement models as generic conditioning features to improve GAN-based speech enhancement. The proposed method, referred to as DisCoGAN, demonstrates performance improvements over baseline models, particularly in low-SNR scenarios, while also maintaining competitive or superior performance in high-SNR conditions and on real-world recordings. We also conduct a comprehensive evaluation of conventional GAN-based architectures, including GANs trained end-to-end, GANs as a first processing stage, and post-filtering GANs, as well as discriminative models under low-SNR conditions. We show that DisCoGAN consistently outperforms existing methods. Finally, we present an ablation study that investigates the contributions of individual components within DisCoGAN and analyzes the impact of the discriminative conditioning method on overall performance.
Low-Complexity Neural Wind Noise Reduction for Audio Recordings
Jul 02, 2025Wind noise significantly degrades the quality of outdoor audio recordings, yet remains difficult to suppress in real-time on resource-constrained devices. In this work, we propose a low-complexity single-channel deep neural network that leverages the spectral characteristics of wind noise. Experimental results show that our method achieves performance comparable to the state-of-the-art low-complexity ULCNet model. The proposed model, with only 249K parameters and roughly 73 MHz of computational power, is suitable for embedded and mobile audio applications.
GAN-Based Speech Enhancement for Low SNR Using Latent Feature Conditioning
Oct 17, 2024



Enhancing speech quality under adverse SNR conditions remains a significant challenge for discriminative deep neural network (DNN)-based approaches. In this work, we propose DisCoGAN, which is a time-frequency-domain generative adversarial network (GAN) conditioned by the latent features of a discriminative model pre-trained for speech enhancement in low SNR scenarios. Our proposed method achieves superior performance compared to state-of-the-arts discriminative methods and also surpasses end-to-end (E2E) trained GAN models. We also investigate the impact of various configurations for conditioning the proposed GAN model with the discriminative model and assess their influence on enhancing speech quality
Align-ULCNet: Towards Low-Complexity and Robust Acoustic Echo and Noise Reduction
Oct 17, 2024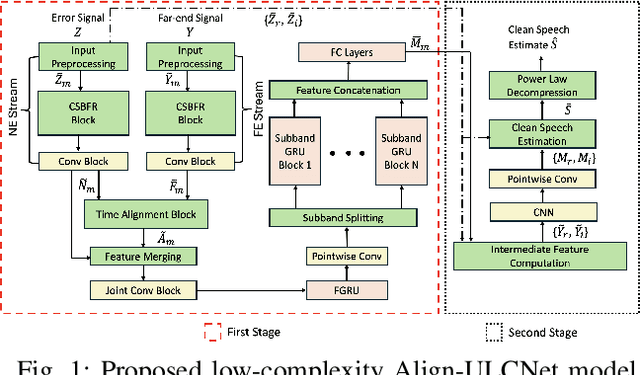
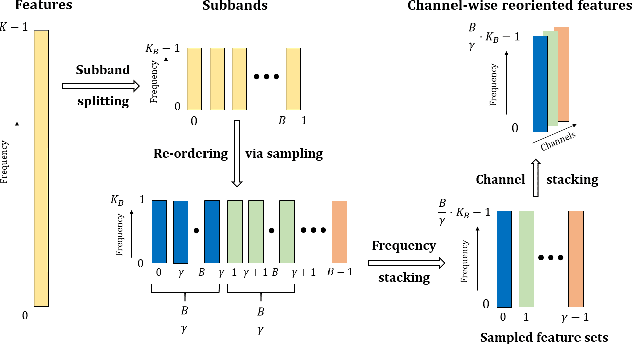
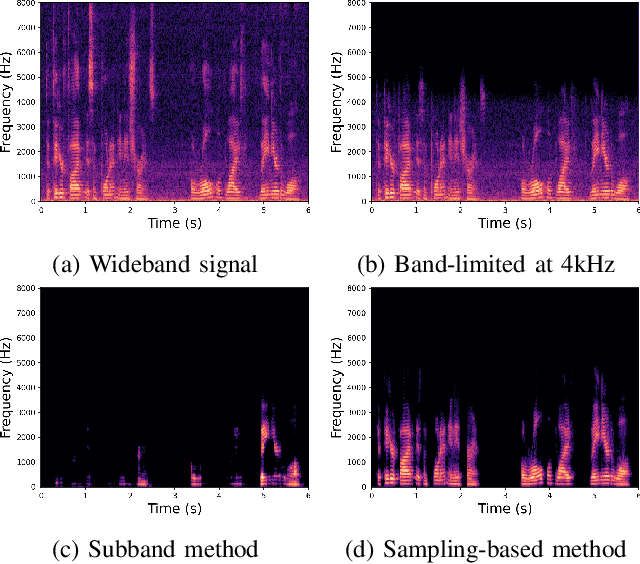
The successful deployment of deep learning-based acoustic echo and noise reduction (AENR) methods in consumer devices has spurred interest in developing low-complexity solutions, while emphasizing the need for robust performance in real-life applications. In this work, we propose a hybrid approach to enhance the state-of-the-art (SOTA) ULCNet model by integrating time alignment and parallel encoder blocks for the model inputs, resulting in better echo reduction and comparable noise reduction performance to existing SOTA methods. We also propose a channel-wise sampling-based feature reorientation method, ensuring robust performance across many challenging scenarios, while maintaining overall low computational and memory requirements.
A Hybrid Approach for Low-Complexity Joint Acoustic Echo and Noise Reduction
Aug 28, 2024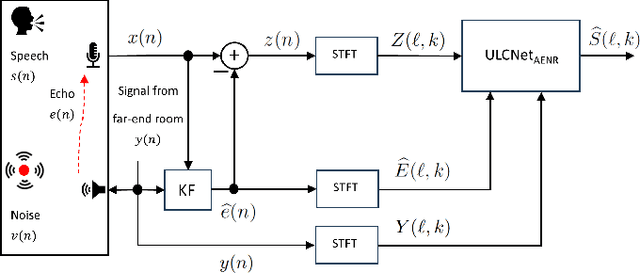


Deep learning-based methods that jointly perform the task of acoustic echo and noise reduction (AENR) often require high memory and computational resources, making them unsuitable for real-time deployment on low-resource platforms such as embedded devices. We propose a low-complexity hybrid approach for joint AENR by employing a single model to suppress both residual echo and noise components. Specifically, we integrate the state-of-the-art (SOTA) ULCNet model, which was originally proposed to achieve ultra-low complexity noise suppression, in a hybrid system and train it for joint AENR. We show that the proposed approach achieves better echo reduction and comparable noise reduction performance with much lower computational complexity and memory requirements than all considered SOTA methods, at the cost of slight degradation in speech quality.
Comparative Analysis Of Discriminative Deep Learning-Based Noise Reduction Methods In Low SNR Scenarios
Aug 26, 2024



In this study, we conduct a comparative analysis of deep learning-based noise reduction methods in low signal-to-noise ratio (SNR) scenarios. Our investigation primarily focuses on five key aspects: The impact of training data, the influence of various loss functions, the effectiveness of direct and indirect speech estimation techniques, the efficacy of masking, mapping, and deep filtering methodologies, and the exploration of different model capacities on noise reduction performance and speech quality. Through comprehensive experimentation, we provide insights into the strengths, weaknesses, and applicability of these methods in low SNR environments. The findings derived from our analysis are intended to assist both researchers and practitioners in selecting better techniques tailored to their specific applications within the domain of low SNR noise reduction.
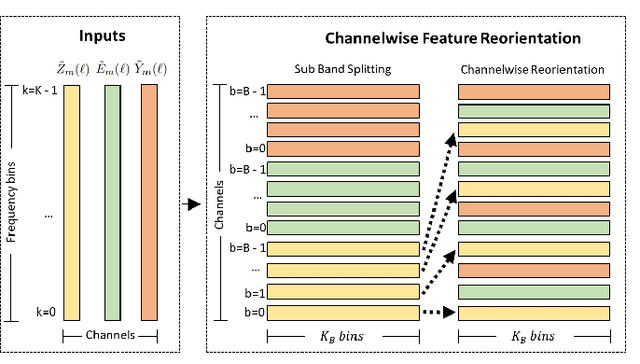
Ultra Low Complexity Deep Learning Based Noise Suppression
Dec 13, 2023This paper introduces an innovative method for reducing the computational complexity of deep neural networks in real-time speech enhancement on resource-constrained devices. The proposed approach utilizes a two-stage processing framework, employing channelwise feature reorientation to reduce the computational load of convolutional operations. By combining this with a modified power law compression technique for enhanced perceptual quality, this approach achieves noise suppression performance comparable to state-of-the-art methods with significantly less computational requirements. Notably, our algorithm exhibits 3 to 4 times less computational complexity and memory usage than prior state-of-the-art approaches.
An Empirical Study of Visual Features for DNN based Audio-Visual Speech Enhancement in Multi-talker Environments
Nov 09, 2020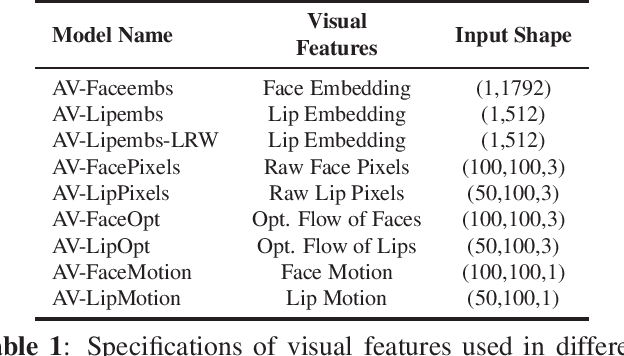
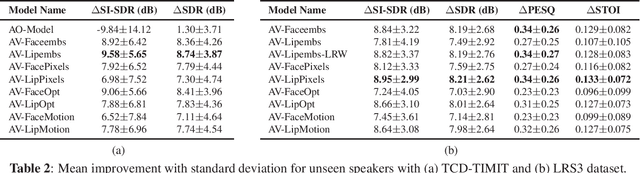
Audio-visual speech enhancement (AVSE) methods use both audio and visual features for the task of speech enhancement and the use of visual features has been shown to be particularly effective in multi-speaker scenarios. In the majority of deep neural network (DNN) based AVSE methods, the audio and visual data are first processed separately using different sub-networks, and then the learned features are fused to utilize the information from both modalities. There have been various studies on suitable audio input features and network architectures, however, to the best of our knowledge, there is no published study that has investigated which visual features are best suited for this specific task. In this work, we perform an empirical study of the most commonly used visual features for DNN based AVSE, the pre-processing requirements for each of these features, and investigate their influence on the performance. Our study shows that despite the overall better performance of embedding-based features, their computationally intensive pre-processing make their use difficult in low resource systems. For such systems, optical flow or raw pixels-based features might be better suited.