 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Visual Features for DNN based Audio-Visual Speech Enhancement in Multi-talker Environments
Paper and Code
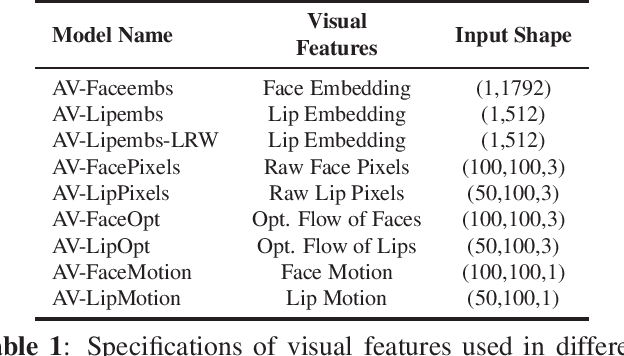
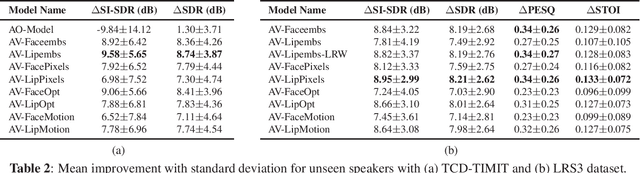
Audio-visual speech enhancement (AVSE) methods use both audio and visual features for the task of speech enhancement and the use of visual features has been shown to be particularly effective in multi-speaker scenarios. In the majority of deep neural network (DNN) based AVSE methods, the audio and visual data are first processed separately using different sub-networks, and then the learned features are fused to utilize the information from both modalities. There have been various studies on suitable audio input features and network architectures, however, to the best of our knowledge, there is no published study that has investigated which visual features are best suited for this specific task. In this work, we perform an empirical study of the most commonly used visual features for DNN based AVSE, the pre-processing requirements for each of these features, and investigate their influence on the performance. Our study shows that despite the overall better performance of embedding-based features, their computationally intensive pre-processing make their use difficult in low resource systems. For such systems, optical flow or raw pixels-based features might be better suited.