 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra Low Complexity Deep Learning Based Noise Suppression
Dec 13, 2023This paper introduces an innovative method for reducing the computational complexity of deep neural networks in real-time speech enhancement on resource-constrained devices. The proposed approach utilizes a two-stage processing framework, employing channelwise feature reorientation to reduce the computational load of convolutional operations. By combining this with a modified power law compression technique for enhanced perceptual quality, this approach achieves noise suppression performance comparable to state-of-the-art methods with significantly less computational requirements. Notably, our algorithm exhibits 3 to 4 times less computational complexity and memory usage than prior state-of-the-art approaches.
New Insights on Target Speaker Extraction
Feb 01, 2022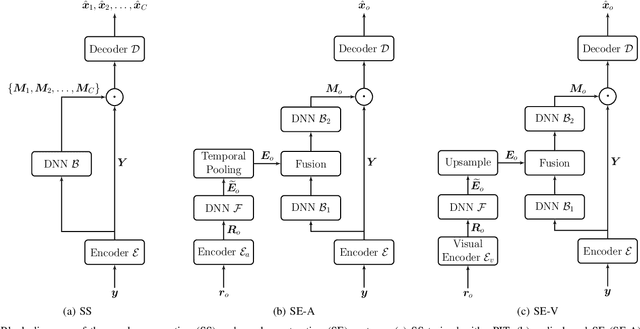
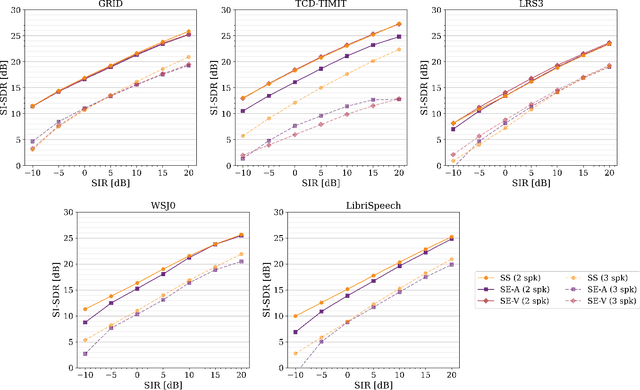
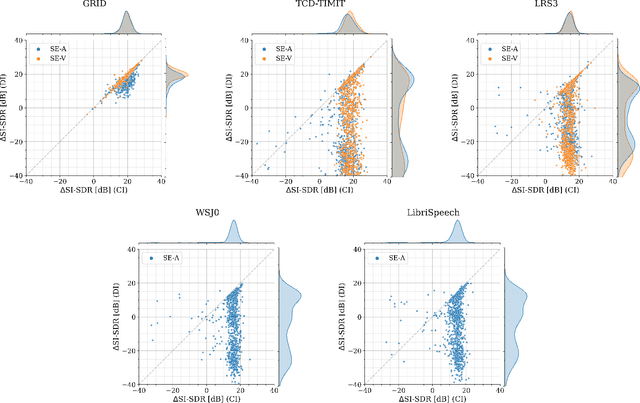
In recent years, researchers have become increasingly interested in speaker extraction (SE), which is the task of extracting the speech of a target speaker from a mixture of interfering speakers with the help of auxiliary information about the target speaker. Several forms of auxiliary information have been employed in single-channel SE, such as a speech snippet enrolled from the target speaker or visual information corresponding to the spoken utterance. Many SE studies have reported performance improvement compared to speaker separation (SS) methods with oracle selection, arguing that this is due to the use of auxiliary information. However, such works have not considered state-of-the-art SS methods that have shown impressive separation performance. In this paper, we revise and examine the role of the auxiliary information in SE. Specifically, we compare the performance of two SE systems (audio-based and video-based) with SS using a common framework that utilizes the state-of-the-art dual-path recurrent neural network as the main learning machine. In addition, we study how much the considered SE systems rely on the auxiliary information by analyzing the systems' output for random auxiliary signals. Experimental evaluation on various datasets suggests that the main purpose of the auxiliary information in the considered SE systems is only to specify the target speaker in the mixture and that it does not provide consistent extraction performance gain when compared to the uninformed SS system.
An Empirical Study of Visual Features for DNN based Audio-Visual Speech Enhancement in Multi-talker Environments
Nov 09, 2020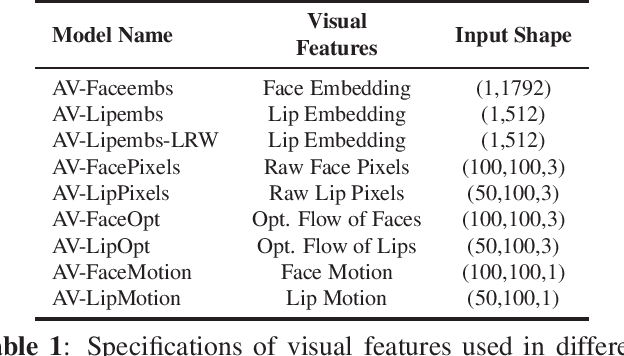
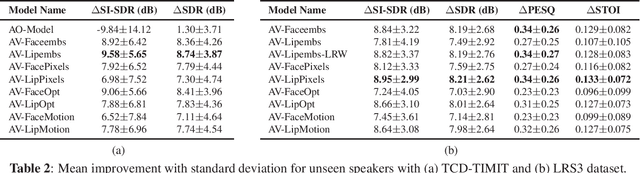
Audio-visual speech enhancement (AVSE) methods use both audio and visual features for the task of speech enhancement and the use of visual features has been shown to be particularly effective in multi-speaker scenarios. In the majority of deep neural network (DNN) based AVSE methods, the audio and visual data are first processed separately using different sub-networks, and then the learned features are fused to utilize the information from both modalities. There have been various studies on suitable audio input features and network architectures, however, to the best of our knowledge, there is no published study that has investigated which visual features are best suited for this specific task. In this work, we perform an empirical study of the most commonly used visual features for DNN based AVSE, the pre-processing requirements for each of these features, and investigate their influence on the performance. Our study shows that despite the overall better performance of embedding-based features, their computationally intensive pre-processing make their use difficult in low resource systems. For such systems, optical flow or raw pixels-based features might be better suited.
Multi-scale aggregation of phase information for reducing computational cost of CNN based DOA estimation
Nov 20, 2018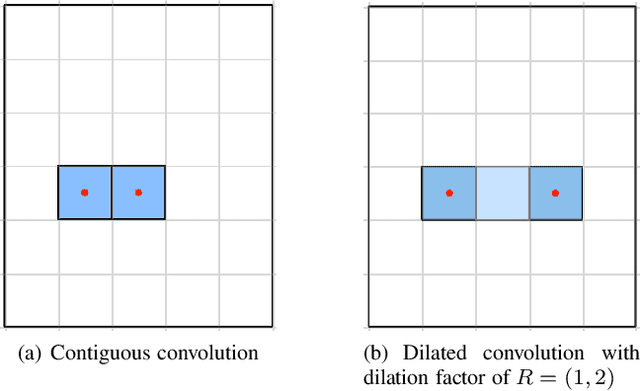


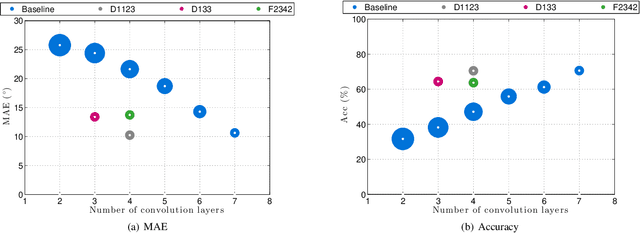
In a recent work on direction-of-arrival (DOA) estimation of multiple speakers with convolutional neural networks (CNNs), the phase component of short-time Fourier transform (STFT) coefficients of the microphone signal is given as input and small filters are used to learn the phase relations between neighboring microphones. Due to this chosen filter size, $M-1$ convolution layers are required to achieve the best performance for a microphone array with M microphones. For arrays with large number of microphones, this requirement leads to a high computational cost making the method practically infeasible. In this work, we propose to use systematic dilations of the convolution filters in each of the convolution layers of the previously proposed CNN for expansion of the receptive field of the filters to reduce the computational cost of the method. Different strategies for expansion of the receptive field of the filters for a specific microphone array are explored. With experimental analysis of the different strategies, it is shown that an aggressive expansion strategy results in a considerable reduction in computational cost while a relatively gradual expansion of the receptive field exhibits the best DOA estimation performance along with reduction in the computational cost.
Multi-Speaker DOA Estimation Using Deep Convolutional Networks Trained with Noise Signals
Jul 31, 2018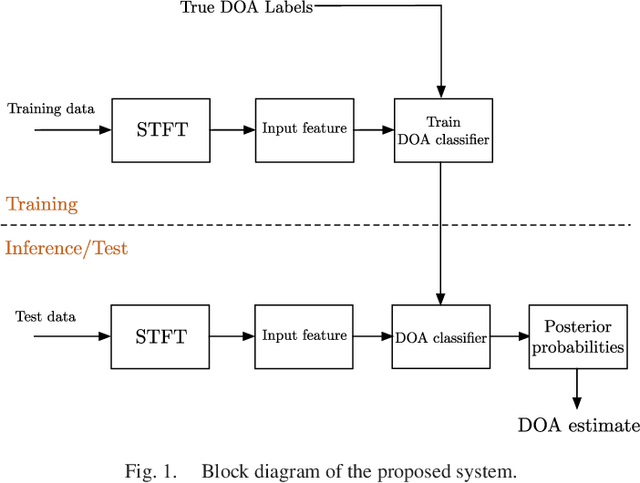
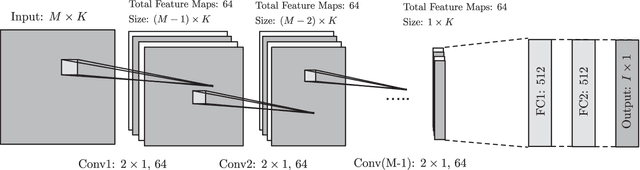
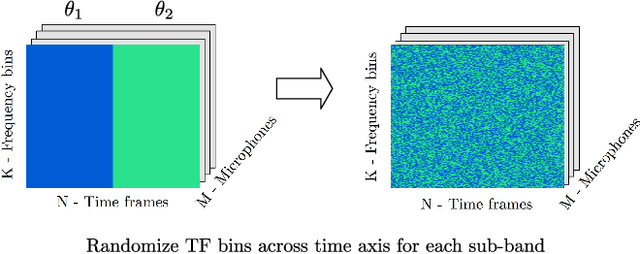
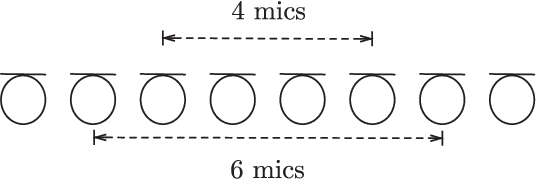
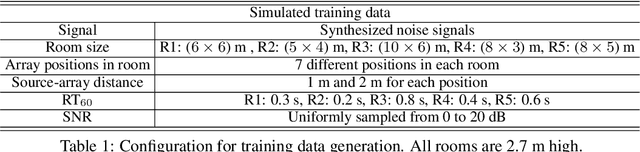
Supervised learning based methods for source localization, being data driven, can be adapted to different acoustic conditions via training and have been shown to be robust to adverse acoustic environments. In this paper, a convolutional neural network (CNN) based supervised learning method for estimating the direction-of-arrival (DOA) of multiple speakers is proposed. Multi-speaker DOA estimation is formulated as a multi-class multi-label classification problem, where the assignment of each DOA label to the input feature is treated as a separate binary classification problem. The phase component of the short-time Fourier transform (STFT) coefficients of the received microphone signals are directly fed into the CNN, and the features for DOA estimation are learnt during training. Utilizing the assumption of disjoint speaker activity in the STFT domain, a novel method is proposed to train the CNN with synthesized noise signals. Through experimental evaluation with both simulated and measured acoustic impulse responses, the ability of the proposed DOA estimation approach to adapt to unseen acoustic conditions and its robustness to unseen noise type is demonstrated. Through additional empirical investigation, it is also shown that with an array of M microphones our proposed framework yields the best localization performance with M-1 convolution layers. The ability of the proposed method to accurately localize speakers in a dynamic acoustic scenario with varying number of sources is also shown.
Multi-Speaker Localization Using Convolutional Neural Network Trained with Noise
Dec 12, 2017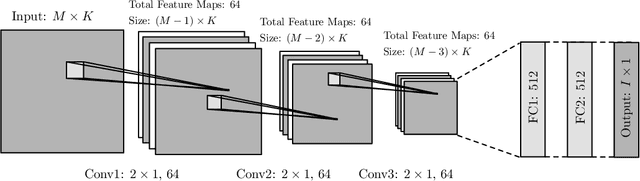
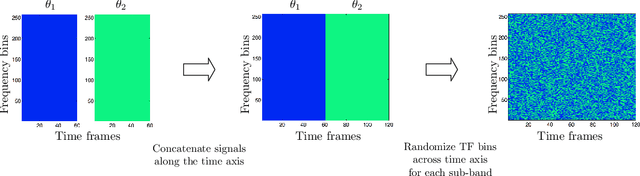

The problem of multi-speaker localization is formulated as a multi-class multi-label classification problem, which is solved using a convolutional neural network (CNN) based source localization method. Utilizing the common assumption of disjoint speaker activities, we propose a novel method to train the CNN using synthesized noise signals. The proposed localization method is evaluated for two speakers and compared to a well-known steered response power method.
Broadband DOA estimation using Convolutional neural networks trained with noise signals
Dec 12, 2017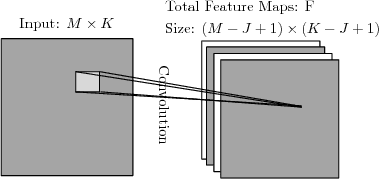


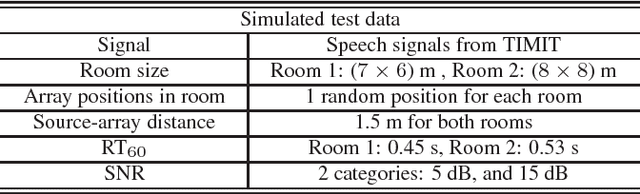
A convolution neural network (CNN) based classification method for broadband DOA estimation is proposed, where the phase component of the short-time Fourier transform coefficients of the received microphone signals are directly fed into the CNN and the features required for DOA estimation are learnt during training. Since only the phase component of the input is used, the CNN can be trained with synthesized noise signals, thereby making the preparation of the training data set easier compared to using speech signals. Through experimental evaluation, the ability of the proposed noise trained CNN framework to generalize to speech sources is demonstrated. In addition, the robustness of the system to noise, small perturbations in microphone positions, as well as its ability to adapt to different acoustic conditions is investigated using experiments with simulated and real data.