 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Insights on Target Speaker Extraction
Paper and Code
Feb 01, 2022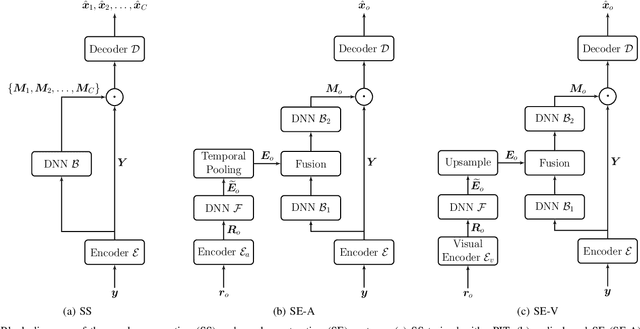
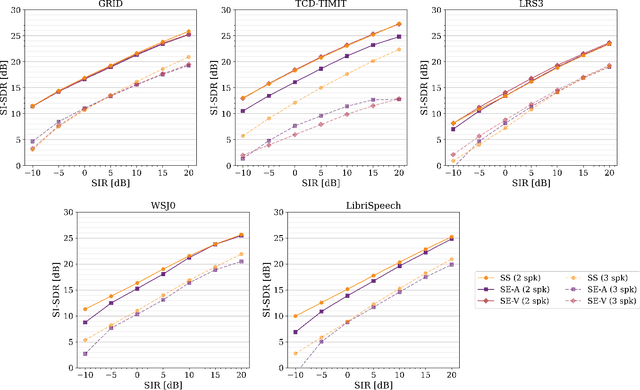
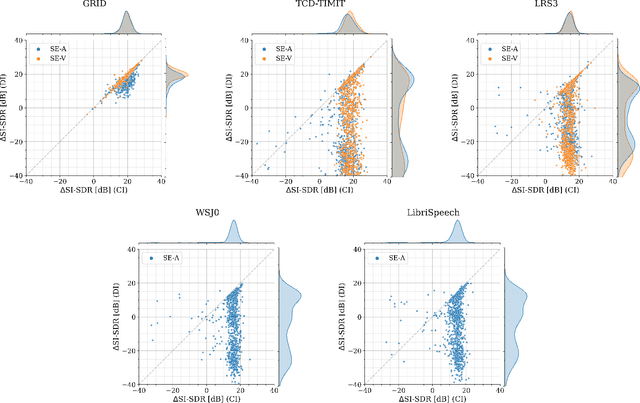
In recent years, researchers have become increasingly interested in speaker extraction (SE), which is the task of extracting the speech of a target speaker from a mixture of interfering speakers with the help of auxiliary information about the target speaker. Several forms of auxiliary information have been employed in single-channel SE, such as a speech snippet enrolled from the target speaker or visual information corresponding to the spoken utterance. Many SE studies have reported performance improvement compared to speaker separation (SS) methods with oracle selection, arguing that this is due to the use of auxiliary information. However, such works have not considered state-of-the-art SS methods that have shown impressive separation performance. In this paper, we revise and examine the role of the auxiliary information in SE. Specifically, we compare the performance of two SE systems (audio-based and video-based) with SS using a common framework that utilizes the state-of-the-art dual-path recurrent neural network as the main learning machine. In addition, we study how much the considered SE systems rely on the auxiliary information by analyzing the systems' output for random auxiliary signals. Experimental evaluation on various datasets suggests that the main purpose of the auxiliary information in the considered SE systems is only to specify the target speaker in the mixture and that it does not provide consistent extraction performance gain when compared to the uninformed SS system.