 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Strategies for Modality Dropout Resilient Multi-Modal Target Speaker Extraction
Jul 09, 2025The primary goal of multi-modal TSE (MTSE) is to extract a target speaker from a speech mixture using complementary information from different modalities, such as audio enrolment and visual feeds corresponding to the target speaker. MTSE systems are expected to perform well even when one of the modalities is unavailable. In practice, the systems often suffer from modality dominance, where one of the modalities outweighs the others, thereby limiting robustness. Our study investigates training strategies and the effect of architectural choices, particularly the normalization layers, in yielding a robust MTSE system in both non-causal and causal configurations. In particular, we propose the use of modality dropout training (MDT) as a superior strategy to standard and multi-task training (MTT) strategies. Experiments conducted on two-speaker mixtures from the LRS3 dataset show the MDT strategy to be effective irrespective of the employed normalization layer. In contrast, the models trained with the standard and MTT strategies are susceptible to modality dominance, and their performance depends on the chosen normalization layer. Additionally, we demonstrate that the system trained with MDT strategy is robust to using extracted speech as the enrollment signal, highlighting its potential applicability in scenarios where the target speaker is not enrolled.
Dynamic Slimmable Networks for Efficient Speech Separation
Jul 08, 2025Recent progress in speech separation has been largely driven by advances in deep neural networks, yet their high computational and memory requirements hinder deployment on resource-constrained devices. A significant inefficiency in conventional systems arises from using static network architectures that maintain constant computational complexity across all input segments, regardless of their characteristics. This approach is sub-optimal for simpler segments that do not require intensive processing, such as silence or non-overlapping speech. To address this limitation, we propose a dynamic slimmable network (DSN) for speech separation that adaptively adjusts its computational complexity based on the input signal. The DSN combines a slimmable network, which can operate at different network widths, with a lightweight gating module that dynamically determines the required width by analyzing the local input characteristics. To balance performance and efficiency, we introduce a signal-dependent complexity loss that penalizes unnecessary computation based on segmental reconstruction error. Experiments on clean and noisy two-speaker mixtures from the WSJ0-2mix and WHAM! datasets show that the DSN achieves a better performance-efficiency trade-off than individually trained static networks of different sizes.
Beamformer-Guided Target Speaker Extraction
Mar 15, 2023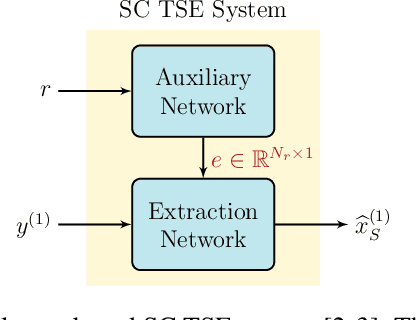
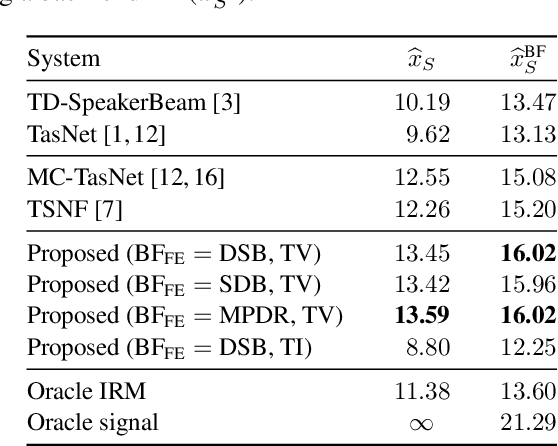
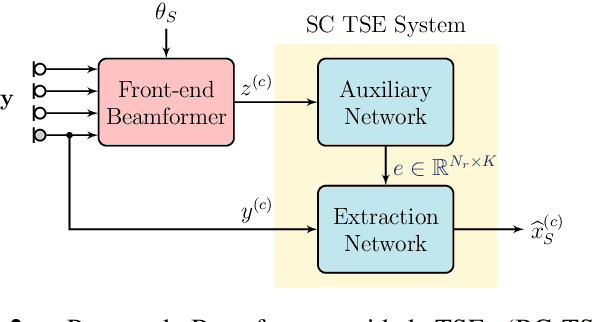
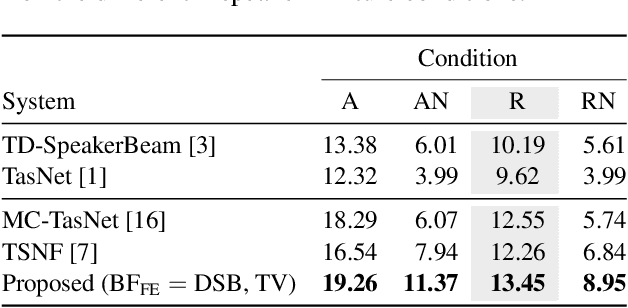
We propose a Beamformer-guided Target Speaker Extraction (BG-TSE) method to extract a target speaker's voice from a multi-channel recording informed by the direction of arrival of the target. The proposed method employs a front-end beamformer steered towards the target speaker to provide an auxiliary signal to a single-channel TSE system. By allowing for time-varying embeddings in the single-channel TSE block, the proposed method fully exploits the correspondence between the front-end beamformer output and the target speech in the microphone signal. Experimental evaluation on simulated multi-channel 2-speaker mixtures, in both anechoic and reverberant conditions, demonstrates the advantage of the proposed method compared to recent single-channel and multi-channel baselines.
Speaker Verification in Multi-Speaker Environments Using Temporal Feature Fusion
Jun 28, 2022
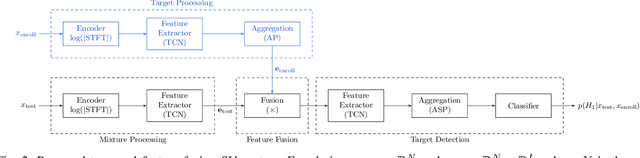
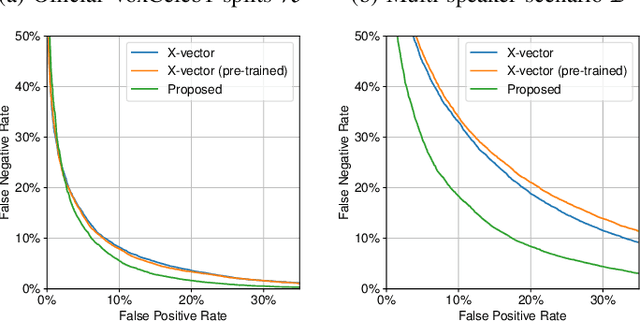
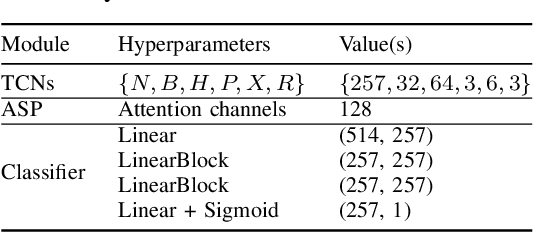
Verifying the identity of a speaker is crucial in modern human-machine interfaces, e.g., to ensure privacy protection or to enable biometric authentication. Classical speaker verification (SV) approaches estimate a fixed-dimensional embedding from a speech utterance that encodes the speaker's voice characteristics. A speaker is verified if his/her voice embedding is sufficiently similar to the embedding of the claimed speaker. However, such approaches assume that only a single speaker exists in the input. The presence of concurrent speakers is likely to have detrimental effects on the performance. To address SV in a multi-speaker environment, we propose an end-to-end deep learning-based SV system that detects whether the target speaker exists within an input or not. First, an embedding is estimated from a reference utterance to represent the target's characteristics. Second, frame-level features are estimated from the input mixture. The reference embedding is then fused frame-wise with the mixture's features to allow distinguishing the target from other speakers on a frame basis. Finally, the fused features are used to predict whether the target speaker is active in the speech segment or not. Experimental evaluation shows that the proposed method outperforms the x-vector in multi-speaker conditions.
New Insights on Target Speaker Extraction
Feb 01, 2022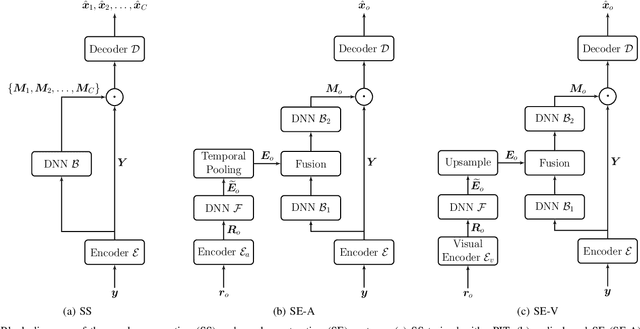
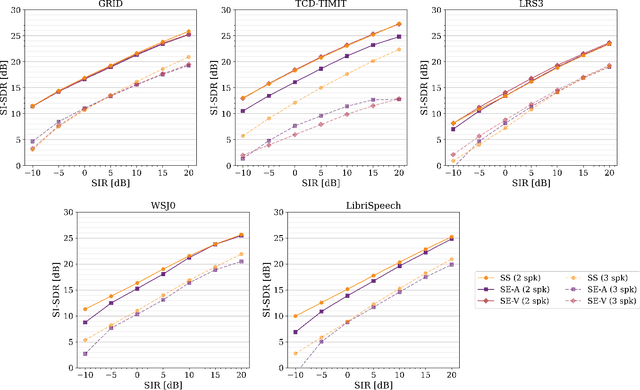
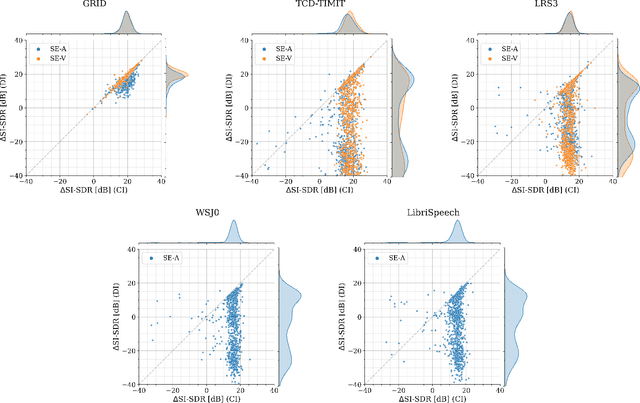
In recent years, researchers have become increasingly interested in speaker extraction (SE), which is the task of extracting the speech of a target speaker from a mixture of interfering speakers with the help of auxiliary information about the target speaker. Several forms of auxiliary information have been employed in single-channel SE, such as a speech snippet enrolled from the target speaker or visual information corresponding to the spoken utterance. Many SE studies have reported performance improvement compared to speaker separation (SS) methods with oracle selection, arguing that this is due to the use of auxiliary information. However, such works have not considered state-of-the-art SS methods that have shown impressive separation performance. In this paper, we revise and examine the role of the auxiliary information in SE. Specifically, we compare the performance of two SE systems (audio-based and video-based) with SS using a common framework that utilizes the state-of-the-art dual-path recurrent neural network as the main learning machine. In addition, we study how much the considered SE systems rely on the auxiliary information by analyzing the systems' output for random auxiliary signals. Experimental evaluation on various datasets suggests that the main purpose of the auxiliary information in the considered SE systems is only to specify the target speaker in the mixture and that it does not provide consistent extraction performance gain when compared to the uninformed SS system.
Guided Source Separation
Nov 09, 2020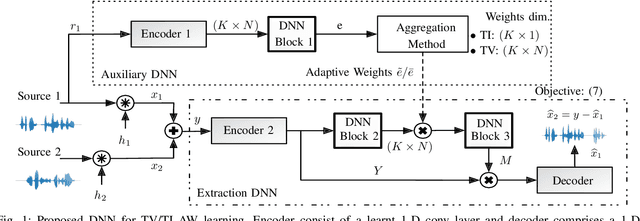
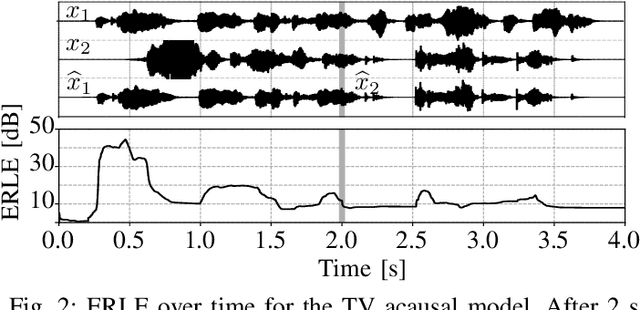

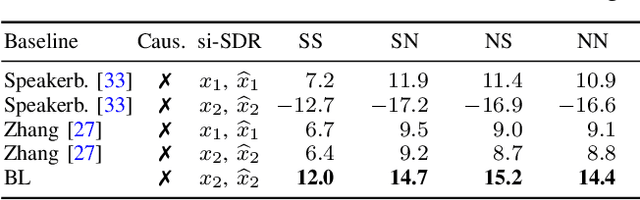
State-of-the-art separation of desired signal components from a mixture is achieved using time-frequency masks or filters estimated by a deep neural network (DNN). The desired components, thereby, are typically defined at the time of training. Recent approaches allow determining the desired components during inference via auxiliary information. Auxiliary information is, thereby, extracted from a reference snippet of the desired components by a second DNN, which estimates a set of adaptive weights (AW) of the first DNN. However, the AW methods require the reference snippet and the desired signal to exhibit time-invariant signal characteristics (SCs) and have only been applied for speaker separation. We show that these AW methods can be used for universal source separation and propose an AW method to extract time-variant auxiliary information from the reference signal. That way, the SCs are allowed to vary across time in the reference and mixture. Applications where the reference and desired signal cannot be assigned to a specific class and vary over time require a time-dependency. An example is acoustic echo cancellation, where the reference is the loudspeaker signal. To avoid strong scaling between the estimate and the mixture, we propose the dual scale-invariant signal-to-distortion ratio in a TASNET inspired DNN as the training objective. We evaluate the proposed AW systems using a wide range of different acoustic conditions and show the scenario dependent advantages of time-variant over time-invariant AW.