 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Microphone Speaker Separation by Spatial Regions
Mar 13, 2023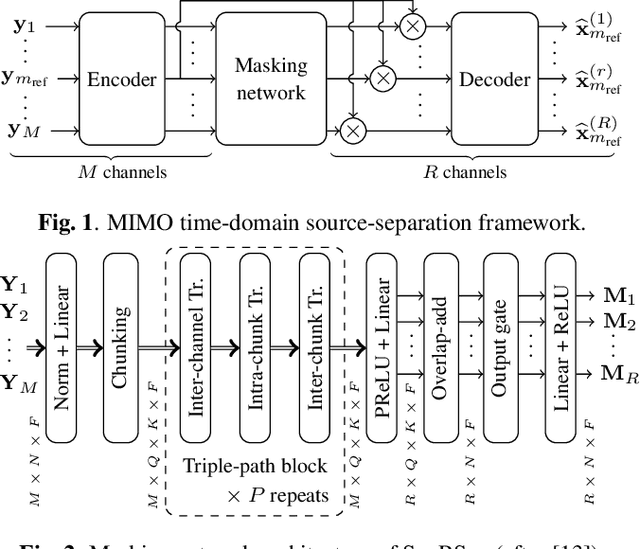
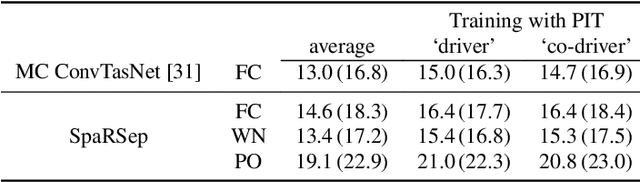
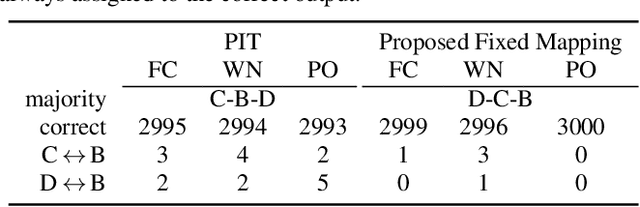

We consider the task of region-based source separation of reverberant multi-microphone recordings. We assume pre-defined spatial regions with a single active source per region. The objective is to estimate the signals from the individual spatial regions as captured by a reference microphone while retaining a correspondence between signals and spatial regions. We propose a data-driven approach using a modified version of a state-of-the-art network, where different layers model spatial and spectro-temporal information. The network is trained to enforce a fixed mapping of regions to network outputs. Using speech from LibriMix, we construct a data set specifically designed to contain the region information. Additionally, we train the network with permutation invariant training. We show that both training methods result in a fixed mapping of regions to network outputs, achieve comparable performance, and that the networks exploit spatial information. The proposed network outperforms a baseline network by 1.5 dB in scale-invariant signal-to-distortion ratio.
Signal-Aware Direction-of-Arrival Estimation Using Attention Mechanisms
Jan 03, 2022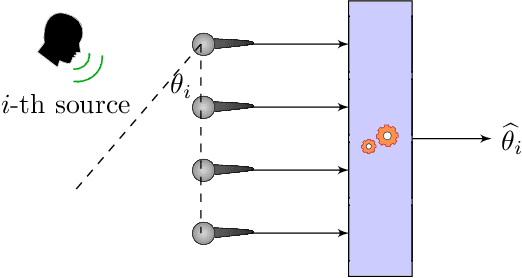
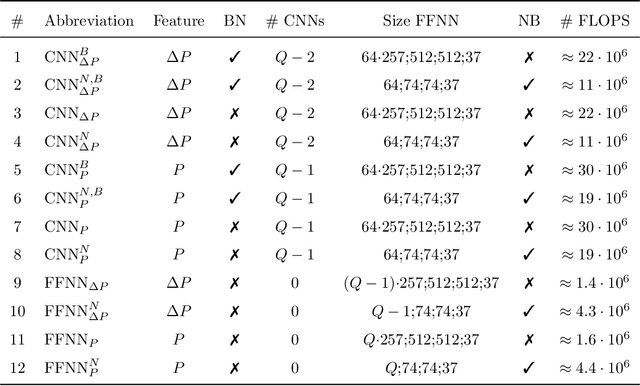
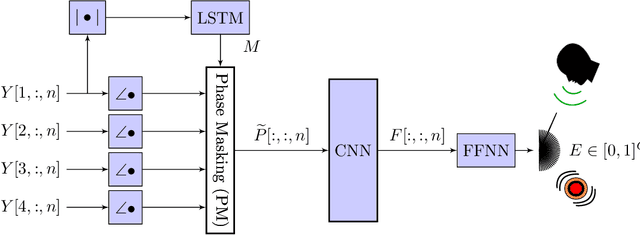

The direction-of-arrival (DOA) of sound sources is an essential acoustic parameter used, e.g., for multi-channel speech enhancement or source tracking. Complex acoustic scenarios consisting of sources-of-interest, interfering sources, reverberation, and noise make the estimation of the DOAs corresponding to the sources-of-interest a challenging task. Recently proposed attention mechanisms allow DOA estimators to focus on the sources-of-interest and disregard interference and noise, i.e., they are signal-aware. The attention is typically obtained by a deep neural network (DNN) from a short-time Fourier transform (STFT) based representation of a single microphone signal. Subsequently, attention has been applied as binary or ratio weighting to STFT-based microphone signal representations to reduce the impact of frequency bins dominated by noise, interference, or reverberation. The impact of attention on DOA estimators and different training strategies for attention and DOA DNNs are not yet studied in depth. In this paper, we evaluate systems consisting of different DNNs and signal processing-based methods for DOA estimation when attention is applied. Additionally, we propose training strategies for attention-based DOA estimation optimized via a DOA objective, i.e., end-to-end. The evaluation of the proposed and the baseline systems is performed using data generated with simulated and measured room impulse responses under various acoustic conditions, like reverberation times, noise, and source array distances. Overall, DOA estimation using attention in combination with signal-processing methods exhibits a far lower computational complexity than a fully DNN-based system; however, it yields comparable results.