 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSP-Conversation: A Corpus for Naturalistic, Time-Continuous Emotion Recognition
Mar 23, 2026Affective computing aims to understand and model human emotions for computational systems. Within this field, speech emotion recognition (SER) focuses on predicting emotions conveyed through speech. While early SER systems relied on limited datasets and traditional machine learning models, recent deep learning approaches demand largescale, naturalistic emotional corpora. To address this need, we introduce the MSP-Conversation corpus: a dataset of more than 70 hours of conversational audio with time-continuous emotional annotations and detailed speaker diarizations. The time-continuous annotations capture the dynamic and contextdependent nature of emotional expression. The annotations in the corpus include fine-grained temporal traces of valence, arousal, and dominance. The audio data is sourced from publicly available podcasts and overlaps with a subset of the isolated speaking turns in the MSP-Podcast corpus to facilitate direct comparisons between annotation methods (i.e., in-context versus out-of-context annotations). The paper outlines the development of the corpus, annotation methodology, analyses of the annotations, and baseline SER experiments, establishing the MSP-Conversation corpus as a valuable resource for advancing research in dynamic SER in naturalistic settings.
Coswara: A respiratory sounds and symptoms dataset for remote screening of SARS-CoV-2 infection
May 22, 2023This paper presents the Coswara dataset, a dataset containing diverse set of respiratory sounds and rich meta-data, recorded between April-2020 and February-2022 from 2635 individuals (1819 SARS-CoV-2 negative, 674 positive, and 142 recovered subjects). The respiratory sounds contained nine sound categories associated with variants of breathing, cough and speech. The rich metadata contained demographic information associated with age, gender and geographic location, as well as the health information relating to the symptoms, pre-existing respiratory ailments, comorbidity and SARS-CoV-2 test status. Our study is the first of its kind to manually annotate the audio quality of the entire dataset (amounting to 65~hours) through manual listening. The paper summarizes the data collection procedure, demographic, symptoms and audio data information. A COVID-19 classifier based on bi-directional long short-term (BLSTM) architecture, is trained and evaluated on the different population sub-groups contained in the dataset to understand the bias/fairness of the model. This enabled the analysis of the impact of gender, geographic location, date of recording, and language proficiency on the COVID-19 detection performance.
Analyzing the impact of SARS-CoV-2 variants on respiratory sound signals
Jun 24, 2022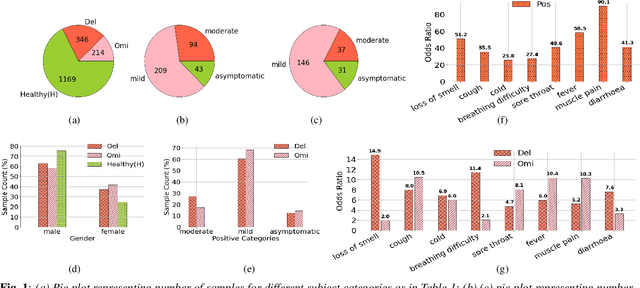
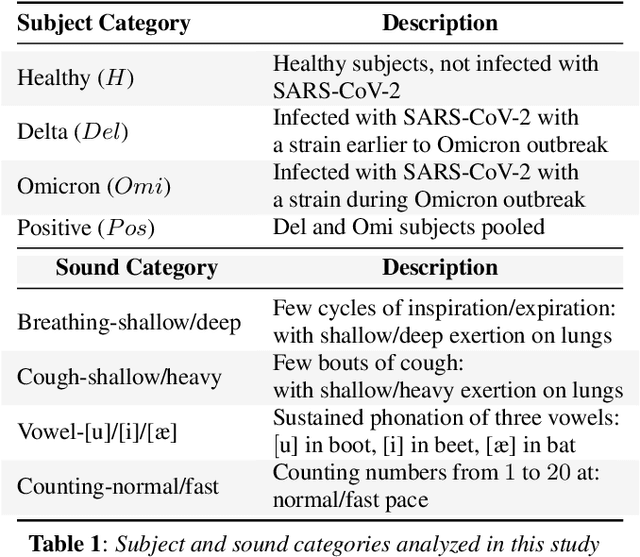
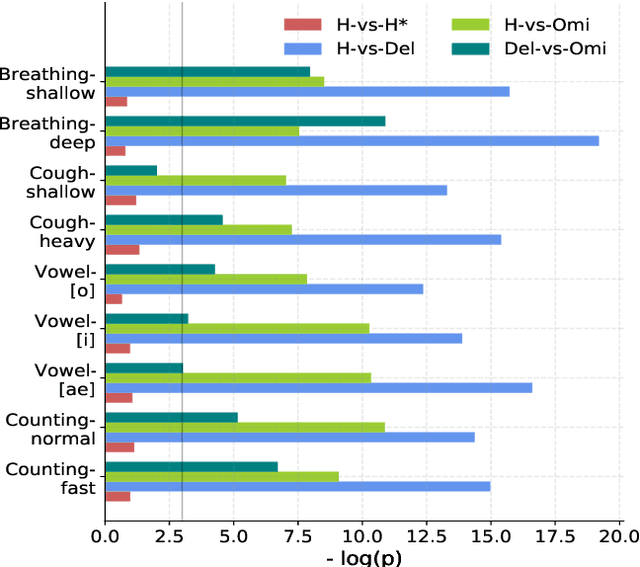
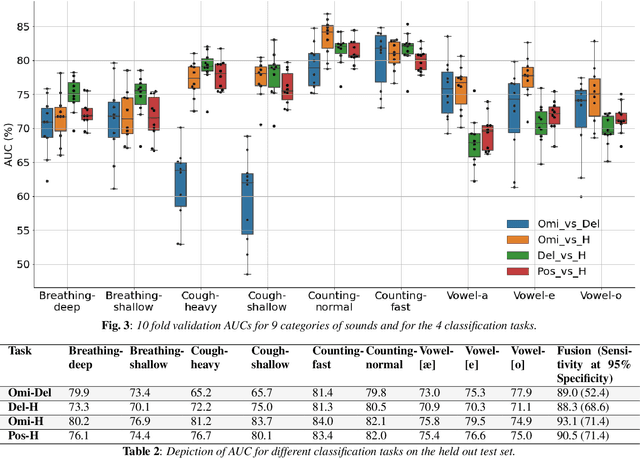
The COVID-19 outbreak resulted in multiple waves of infections that have been associated with different SARS-CoV-2 variants. Studies have reported differential impact of the variants on respiratory health of patients. We explore whether acoustic signals, collected from COVID-19 subjects, show computationally distinguishable acoustic patterns suggesting a possibility to predict the underlying virus variant. We analyze the Coswara dataset which is collected from three subject pools, namely, i) healthy, ii) COVID-19 subjects recorded during the delta variant dominant period, and iii) data from COVID-19 subjects recorded during the omicron surge. Our findings suggest that multiple sound categories, such as cough, breathing, and speech, indicate significant acoustic feature differences when comparing COVID-19 subjects with omicron and delta variants. The classification areas-under-the-curve are significantly above chance for differentiating subjects infected by omicron from those infected by delta. Using a score fusion from multiple sound categories, we obtained an area-under-the-curve of 89% and 52.4% sensitivity at 95% specificity. Additionally, a hierarchical three class approach was used to classify the acoustic data into healthy and COVID-19 positive, and further COVID-19 subjects into delta and omicron variants providing high level of 3-class classification accuracy. These results suggest new ways for designing sound based COVID-19 diagnosis approaches.
Coswara: A website application enabling COVID-19 screening by analysing respiratory sound samples and health symptoms
Jun 09, 2022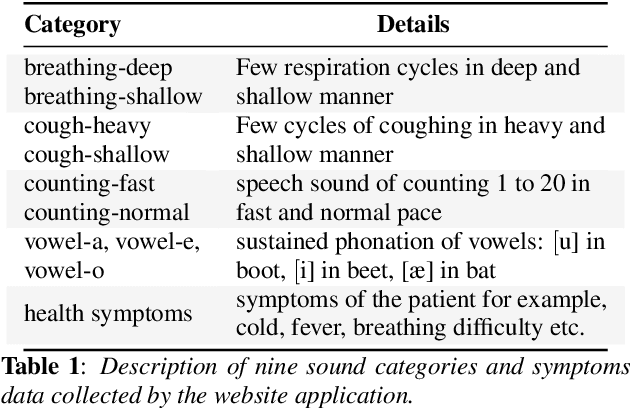


The COVID-19 pandemic has accelerated research on design of alternative, quick and effective COVID-19 diagnosis approaches. In this paper, we describe the Coswara tool, a website application designed to enable COVID-19 detection by analysing respiratory sound samples and health symptoms. A user using this service can log into a website using any device connected to the internet, provide there current health symptom information and record few sound sampled corresponding to breathing, cough, and speech. Within a minute of analysis of this information on a cloud server the website tool will output a COVID-19 probability score to the user. As the COVID-19 pandemic continues to demand massive and scalable population level testing, we hypothesize that the proposed tool provides a potential solution towards this.
The Second DiCOVA Challenge: Dataset and performance analysis for COVID-19 diagnosis using acoustics
Oct 11, 2021
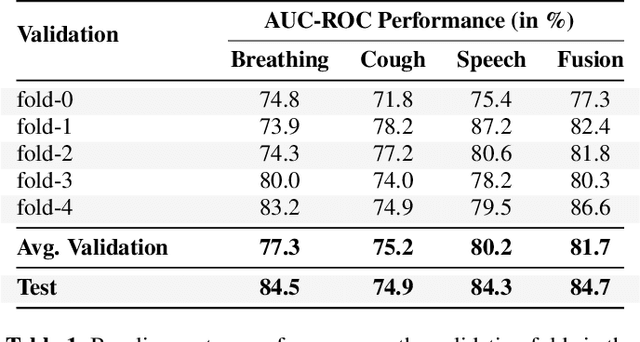
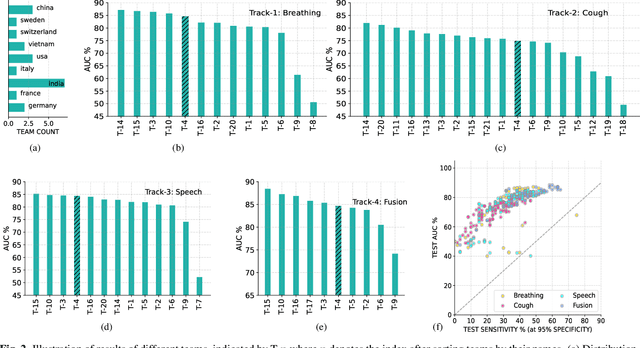
The Second Diagnosis of COVID-19 using Acoustics (DiCOVA) Challenge aimed at accelerating the research in acoustics based detection of COVID-19, a topic at the intersection of acoustics, signal processing, machine learning, and healthcare. This paper presents the details of the challenge, which was an open call for researchers to analyze a dataset of audio recordings consisting of breathing, cough and speech signals. This data was collected from individuals with and without COVID-19 infection, and the task in the challenge was a two-class classification. The development set audio recordings were collected from 965 (172 COVID-19 positive) individuals, while the evaluation set contained data from 471 individuals (71 COVID-19 positive). The challenge featured four tracks, one associated with each sound category of cough, speech and breathing, and a fourth fusion track. A baseline system was also released to benchmark the participants. In this paper, we present an overview of the challenge, the rationale for the data collection and the baseline system. Further, a performance analysis for the systems submitted by the $16$ participating teams in the leaderboard is also presented.