 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoli: A dataset for understanding stuttering experience and analyzing stuttered speech
Jan 27, 2025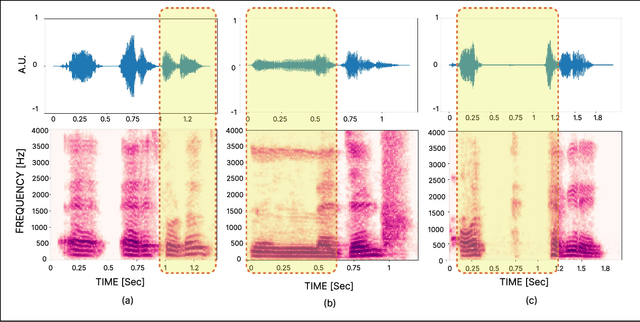

There is a growing need for diverse, high-quality stuttered speech data, particularly in the context of Indian languages. This paper introduces Project Boli, a multi-lingual stuttered speech dataset designed to advance scientific understanding and technology development for individuals who stutter, particularly in India. The dataset constitutes (a) anonymized metadata (gender, age, country, mother tongue) and responses to a questionnaire about how stuttering affects their daily lives, (b) captures both read speech (using the Rainbow Passage) and spontaneous speech (through image description tasks) for each participant and (c) includes detailed annotations of five stutter types: blocks, prolongations, interjections, sound repetitions and word repetitions. We present a comprehensive analysis of the dataset, including the data collection procedure, experience summarization of people who stutter, severity assessment of stuttering events and technical validation of the collected data. The dataset is released as an open access to further speech technology development.
Deciphering Assamese Vowel Harmony with Featural InfoWaveGAN
Jul 09, 2024
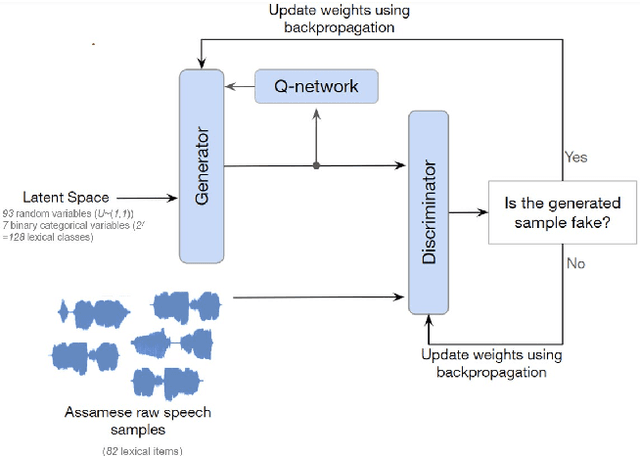

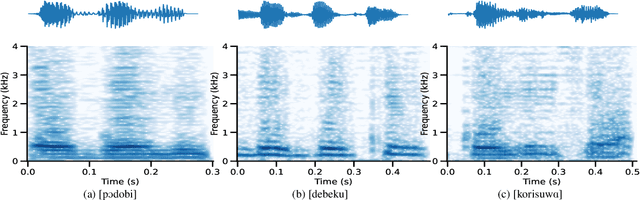
Traditional approaches for understanding phonological learning have predominantly relied on curated text data. Although insightful, such approaches limit the knowledge captured in textual representations of the spoken language. To overcome this limitation, we investigate the potential of the Featural InfoWaveGAN model to learn iterative long-distance vowel harmony using raw speech data. We focus on Assamese, a language known for its phonologically regressive and word-bound vowel harmony. We demonstrate that the model is adept at grasping the intricacies of Assamese phonotactics, particularly iterative long-distance harmony with regressive directionality. It also produced non-iterative illicit forms resembling speech errors during human language acquisition. Our statistical analysis reveals a preference for a specific [+high,+ATR] vowel as a trigger across novel items, indicative of feature learning. More data and control could improve model proficiency, contrasting the universality of learning.
Coswara: A respiratory sounds and symptoms dataset for remote screening of SARS-CoV-2 infection
May 22, 2023This paper presents the Coswara dataset, a dataset containing diverse set of respiratory sounds and rich meta-data, recorded between April-2020 and February-2022 from 2635 individuals (1819 SARS-CoV-2 negative, 674 positive, and 142 recovered subjects). The respiratory sounds contained nine sound categories associated with variants of breathing, cough and speech. The rich metadata contained demographic information associated with age, gender and geographic location, as well as the health information relating to the symptoms, pre-existing respiratory ailments, comorbidity and SARS-CoV-2 test status. Our study is the first of its kind to manually annotate the audio quality of the entire dataset (amounting to 65~hours) through manual listening. The paper summarizes the data collection procedure, demographic, symptoms and audio data information. A COVID-19 classifier based on bi-directional long short-term (BLSTM) architecture, is trained and evaluated on the different population sub-groups contained in the dataset to understand the bias/fairness of the model. This enabled the analysis of the impact of gender, geographic location, date of recording, and language proficiency on the COVID-19 detection performance.
Analyzing the impact of SARS-CoV-2 variants on respiratory sound signals
Jun 24, 2022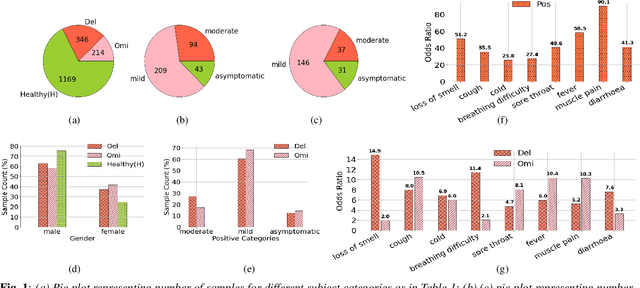
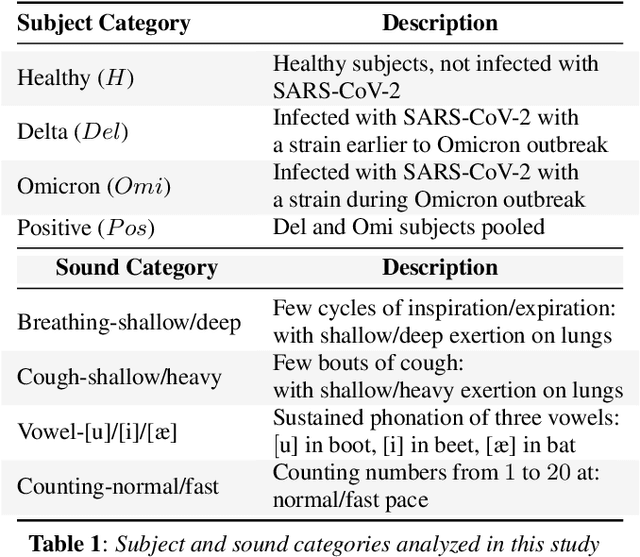
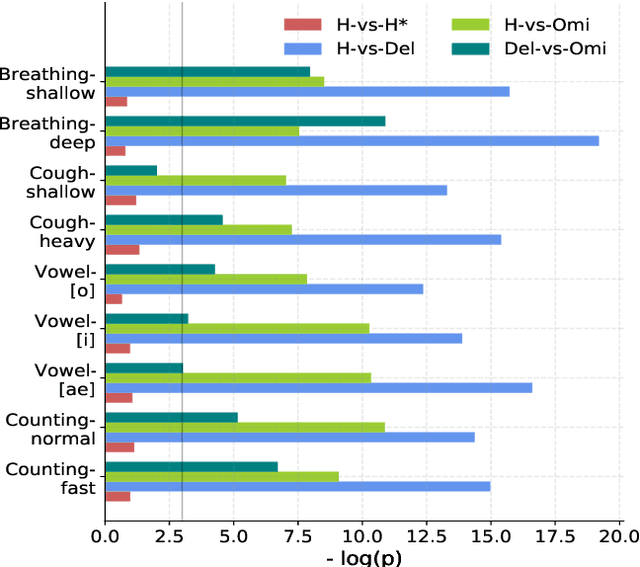
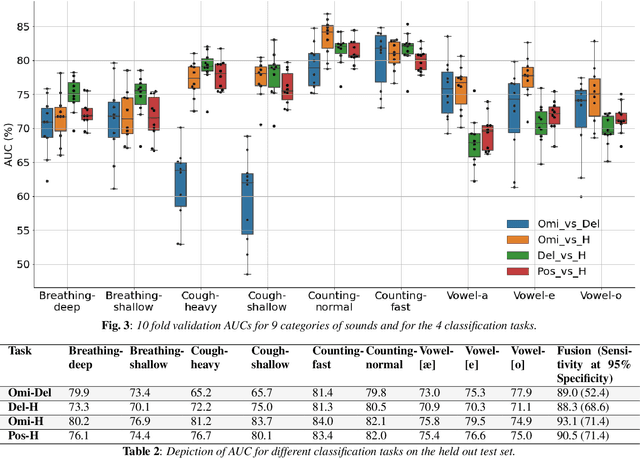
The COVID-19 outbreak resulted in multiple waves of infections that have been associated with different SARS-CoV-2 variants. Studies have reported differential impact of the variants on respiratory health of patients. We explore whether acoustic signals, collected from COVID-19 subjects, show computationally distinguishable acoustic patterns suggesting a possibility to predict the underlying virus variant. We analyze the Coswara dataset which is collected from three subject pools, namely, i) healthy, ii) COVID-19 subjects recorded during the delta variant dominant period, and iii) data from COVID-19 subjects recorded during the omicron surge. Our findings suggest that multiple sound categories, such as cough, breathing, and speech, indicate significant acoustic feature differences when comparing COVID-19 subjects with omicron and delta variants. The classification areas-under-the-curve are significantly above chance for differentiating subjects infected by omicron from those infected by delta. Using a score fusion from multiple sound categories, we obtained an area-under-the-curve of 89% and 52.4% sensitivity at 95% specificity. Additionally, a hierarchical three class approach was used to classify the acoustic data into healthy and COVID-19 positive, and further COVID-19 subjects into delta and omicron variants providing high level of 3-class classification accuracy. These results suggest new ways for designing sound based COVID-19 diagnosis approaches.
Coswara: A website application enabling COVID-19 screening by analysing respiratory sound samples and health symptoms
Jun 09, 2022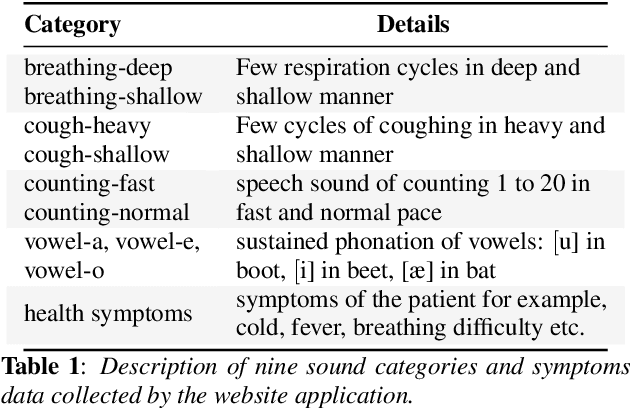


The COVID-19 pandemic has accelerated research on design of alternative, quick and effective COVID-19 diagnosis approaches. In this paper, we describe the Coswara tool, a website application designed to enable COVID-19 detection by analysing respiratory sound samples and health symptoms. A user using this service can log into a website using any device connected to the internet, provide there current health symptom information and record few sound sampled corresponding to breathing, cough, and speech. Within a minute of analysis of this information on a cloud server the website tool will output a COVID-19 probability score to the user. As the COVID-19 pandemic continues to demand massive and scalable population level testing, we hypothesize that the proposed tool provides a potential solution towards this.
The Second DiCOVA Challenge: Dataset and performance analysis for COVID-19 diagnosis using acoustics
Oct 11, 2021
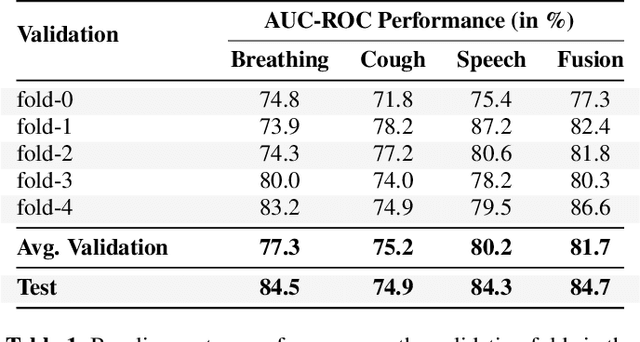
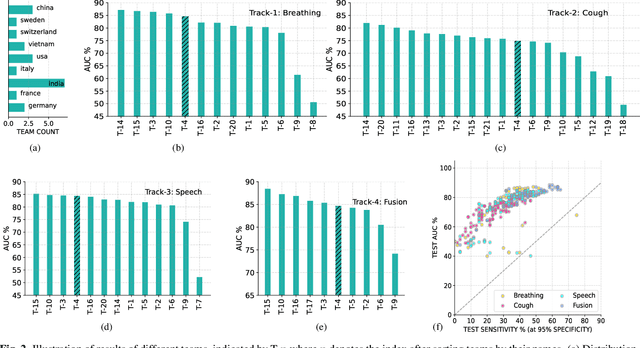
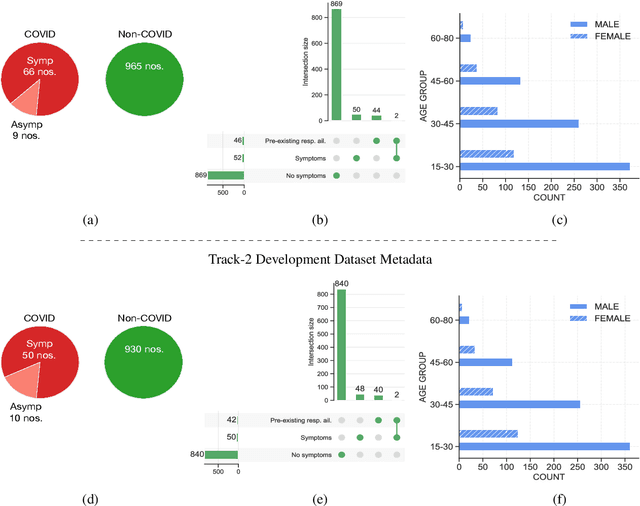
The Second Diagnosis of COVID-19 using Acoustics (DiCOVA) Challenge aimed at accelerating the research in acoustics based detection of COVID-19, a topic at the intersection of acoustics, signal processing, machine learning, and healthcare. This paper presents the details of the challenge, which was an open call for researchers to analyze a dataset of audio recordings consisting of breathing, cough and speech signals. This data was collected from individuals with and without COVID-19 infection, and the task in the challenge was a two-class classification. The development set audio recordings were collected from 965 (172 COVID-19 positive) individuals, while the evaluation set contained data from 471 individuals (71 COVID-19 positive). The challenge featured four tracks, one associated with each sound category of cough, speech and breathing, and a fourth fusion track. A baseline system was also released to benchmark the participants. In this paper, we present an overview of the challenge, the rationale for the data collection and the baseline system. Further, a performance analysis for the systems submitted by the $16$ participating teams in the leaderboard is also presented.
Towards sound based testing of COVID-19 -- Summary of the first Diagnostics of COVID-19 using Acoustics Challenge
Jun 21, 2021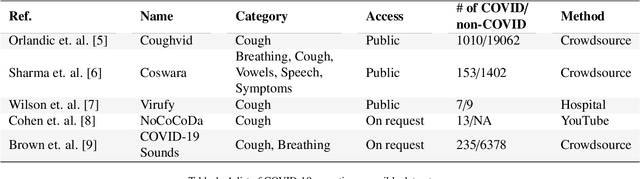
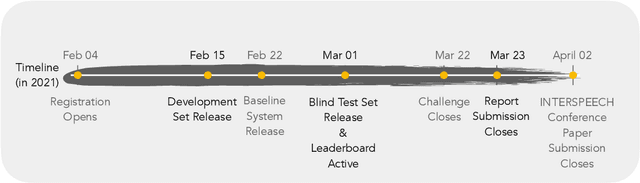
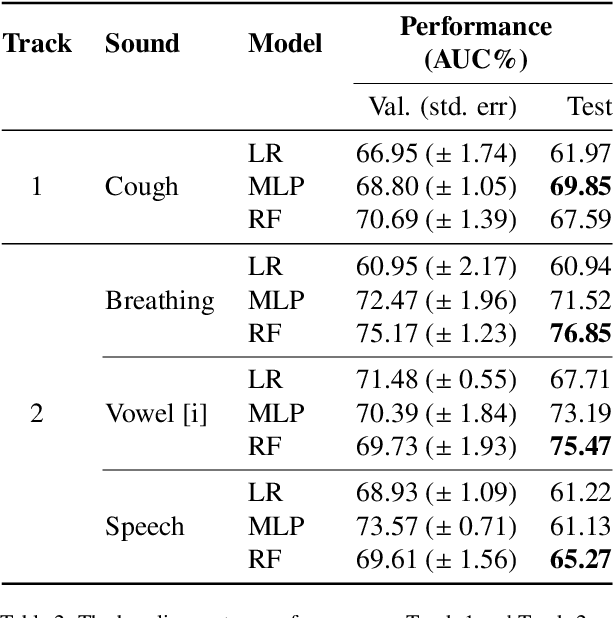
The technology development for point-of-care tests (POCTs) targeting respiratory diseases has witnessed a growing demand in the recent past. Investigating the presence of acoustic biomarkers in modalities such as cough, breathing and speech sounds, and using them for building POCTs can offer fast, contactless and inexpensive testing. In view of this, over the past year, we launched the ``Coswara'' project to collect cough, breathing and speech sound recordings via worldwide crowdsourcing. With this data, a call for development of diagnostic tools was announced in the Interspeech 2021 as a special session titled ``Diagnostics of COVID-19 using Acoustics (DiCOVA) Challenge''. The goal was to bring together researchers and practitioners interested in developing acoustics-based COVID-19 POCTs by enabling them to work on the same set of development and test datasets. As part of the challenge, datasets with breathing, cough, and speech sound samples from COVID-19 and non-COVID-19 individuals were released to the participants. The challenge consisted of two tracks. The Track-1 focused only on cough sounds, and participants competed in a leaderboard setting. In Track-2, breathing and speech samples were provided for the participants, without a competitive leaderboard. The challenge attracted 85 plus registrations with 29 final submissions for Track-1. This paper describes the challenge (datasets, tasks, baseline system), and presents a focused summary of the various systems submitted by the participating teams. An analysis of the results from the top four teams showed that a fusion of the scores from these teams yields an area-under-the-curve of 95.1% on the blind test data. By summarizing the lessons learned, we foresee the challenge overview in this paper to help accelerate technology for acoustic-based POCTs.
A Dynamic Framework of Reputation Systems for an Agent Mediated e-market
Oct 18, 2011
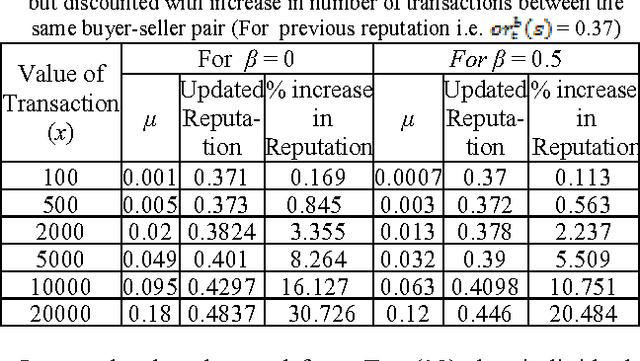
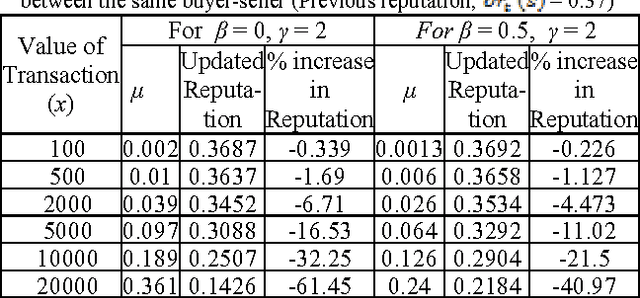
The success of an agent mediated e-market system lies in the underlying reputation management system to improve the quality of services in an information asymmetric e-market. Reputation provides an operatable metric for establishing trustworthiness between mutually unknown online entities. Reputation systems encourage honest behaviour and discourage malicious behaviour of participating agents in the e-market. A dynamic reputation model would provide virtually instantaneous knowledge about the changing e-market environment and would utilise Internets' capacity for continuous interactivity for reputation computation. This paper proposes a dynamic reputation framework using reinforcement learning and fuzzy set theory that ensures judicious use of information sharing for inter-agent cooperation. This framework is sensitive to the changing parameters of e-market like the value of transaction and the varying experience of agents with the purpose of improving inbuilt defense mechanism of the reputation system against various attacks so that e-market reaches an equilibrium state and dishonest agents are weeded out of the market.