 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeciphering Assamese Vowel Harmony with Featural InfoWaveGAN
Jul 09, 2024
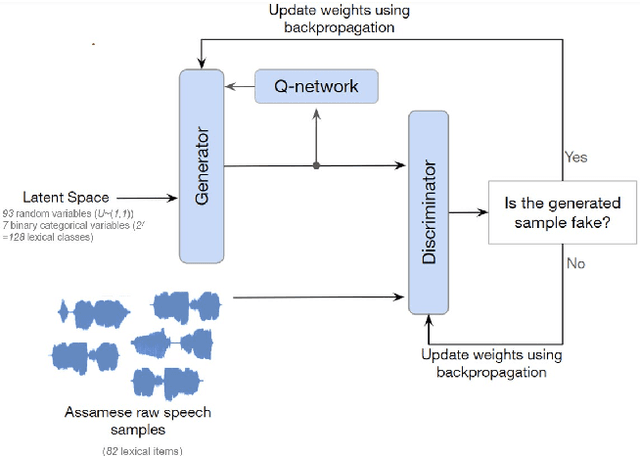

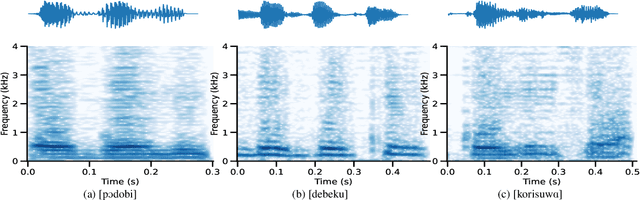
Traditional approaches for understanding phonological learning have predominantly relied on curated text data. Although insightful, such approaches limit the knowledge captured in textual representations of the spoken language. To overcome this limitation, we investigate the potential of the Featural InfoWaveGAN model to learn iterative long-distance vowel harmony using raw speech data. We focus on Assamese, a language known for its phonologically regressive and word-bound vowel harmony. We demonstrate that the model is adept at grasping the intricacies of Assamese phonotactics, particularly iterative long-distance harmony with regressive directionality. It also produced non-iterative illicit forms resembling speech errors during human language acquisition. Our statistical analysis reveals a preference for a specific [+high,+ATR] vowel as a trigger across novel items, indicative of feature learning. More data and control could improve model proficiency, contrasting the universality of learning.