 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Few-shot Entity Recognition in Document Images: A Graph Neural Network Approach Robust to Image Manipulation
May 24, 2023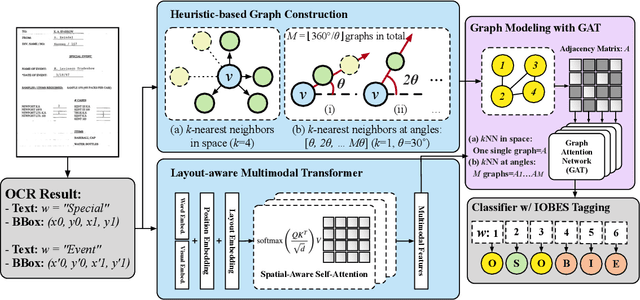

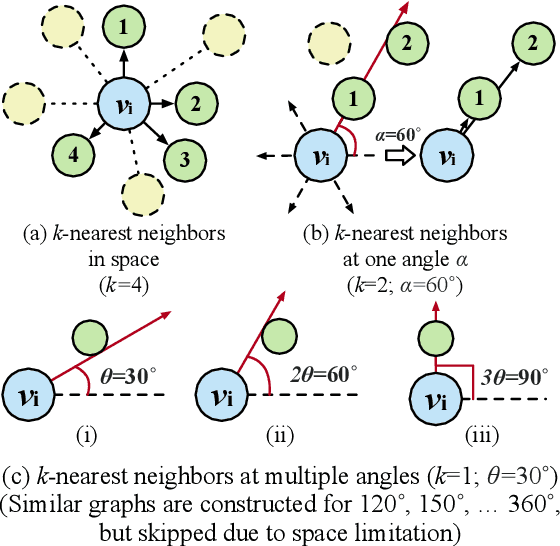
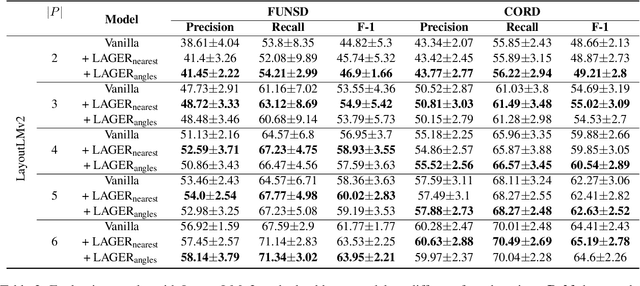
Recent advances of incorporating layout information, typically bounding box coordinates, into pre-trained language models have achieved significant performance in entity recognition from document images. Using coordinates can easily model the absolute position of each token, but they might be sensitive to manipulations in document images (e.g., shifting, rotation or scaling), especially when the training data is limited in few-shot settings. In this paper, we propose to further introduce the topological adjacency relationship among the tokens, emphasizing their relative position information. Specifically, we consider the tokens in the documents as nodes and formulate the edges based on the topological heuristics from the k-nearest bounding boxes. Such adjacency graphs are invariant to affine transformations including shifting, rotations and scaling. We incorporate these graphs into the pre-trained language model by adding graph neural network layers on top of the language model embeddings, leading to a novel model LAGER. Extensive experiments on two benchmark datasets show that LAGER significantly outperforms strong baselines under different few-shot settings and also demonstrate better robustness to manipulations.
Towards sound based testing of COVID-19 -- Summary of the first Diagnostics of COVID-19 using Acoustics Challenge
Jun 21, 2021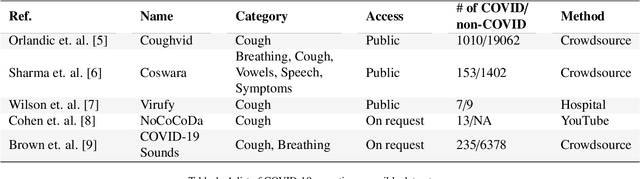
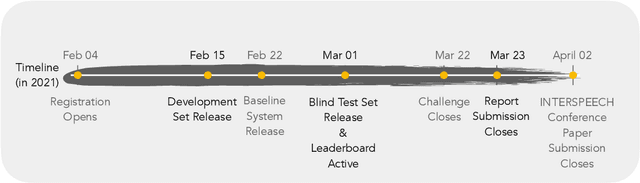
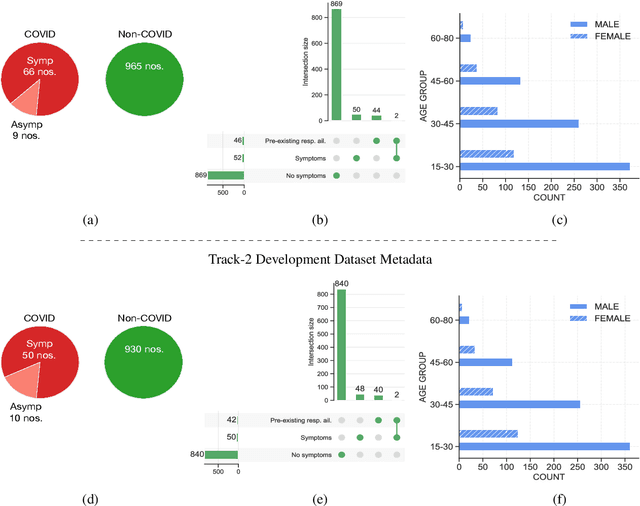
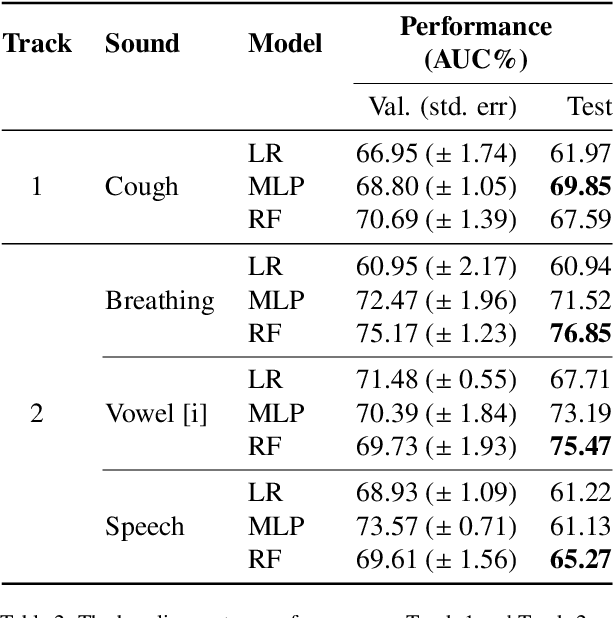
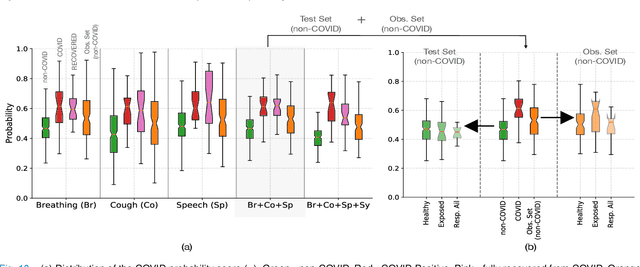
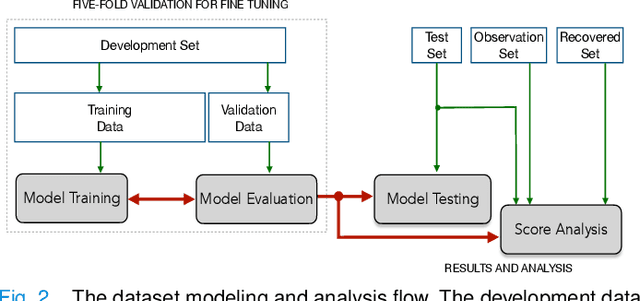
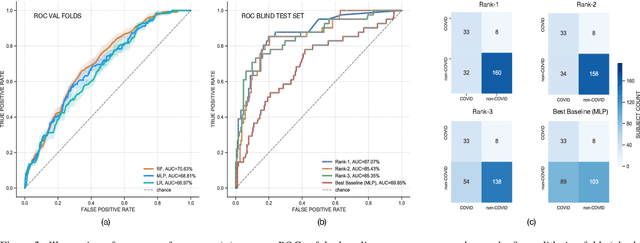
The technology development for point-of-care tests (POCTs) targeting respiratory diseases has witnessed a growing demand in the recent past. Investigating the presence of acoustic biomarkers in modalities such as cough, breathing and speech sounds, and using them for building POCTs can offer fast, contactless and inexpensive testing. In view of this, over the past year, we launched the ``Coswara'' project to collect cough, breathing and speech sound recordings via worldwide crowdsourcing. With this data, a call for development of diagnostic tools was announced in the Interspeech 2021 as a special session titled ``Diagnostics of COVID-19 using Acoustics (DiCOVA) Challenge''. The goal was to bring together researchers and practitioners interested in developing acoustics-based COVID-19 POCTs by enabling them to work on the same set of development and test datasets. As part of the challenge, datasets with breathing, cough, and speech sound samples from COVID-19 and non-COVID-19 individuals were released to the participants. The challenge consisted of two tracks. The Track-1 focused only on cough sounds, and participants competed in a leaderboard setting. In Track-2, breathing and speech samples were provided for the participants, without a competitive leaderboard. The challenge attracted 85 plus registrations with 29 final submissions for Track-1. This paper describes the challenge (datasets, tasks, baseline system), and presents a focused summary of the various systems submitted by the participating teams. An analysis of the results from the top four teams showed that a fusion of the scores from these teams yields an area-under-the-curve of 95.1% on the blind test data. By summarizing the lessons learned, we foresee the challenge overview in this paper to help accelerate technology for acoustic-based POCTs.
Multi-modal Point-of-Care Diagnostics for COVID-19 Based On Acoustics and Symptoms
Jun 05, 2021
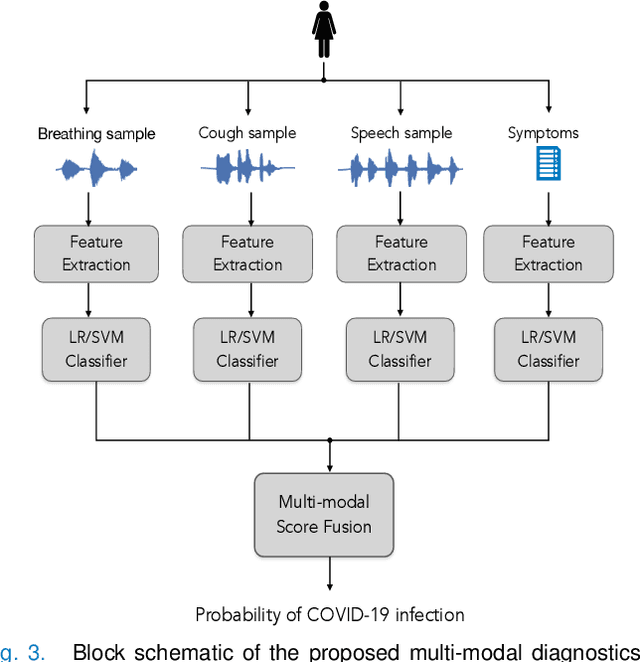
The research direction of identifying acoustic bio-markers of respiratory diseases has received renewed interest following the onset of COVID-19 pandemic. In this paper, we design an approach to COVID-19 diagnostic using crowd-sourced multi-modal data. The data resource, consisting of acoustic signals like cough, breathing, and speech signals, along with the data of symptoms, are recorded using a web-application over a period of ten months. We investigate the use of statistical descriptors of simple time-frequency features for acoustic signals and binary features for the presence of symptoms. Unlike previous works, we primarily focus on the application of simple linear classifiers like logistic regression and support vector machines for acoustic data while decision tree models are employed on the symptoms data. We show that a multi-modal integration of acoustics and symptoms classifiers achieves an area-under-curve (AUC) of 92.40, a significant improvement over any individual modality. Several ablation experiments are also provided which highlight the acoustic and symptom dimensions that are important for the task of COVID-19 diagnostics.
DiCOVA Challenge: Dataset, task, and baseline system for COVID-19 diagnosis using acoustics
Apr 05, 2021
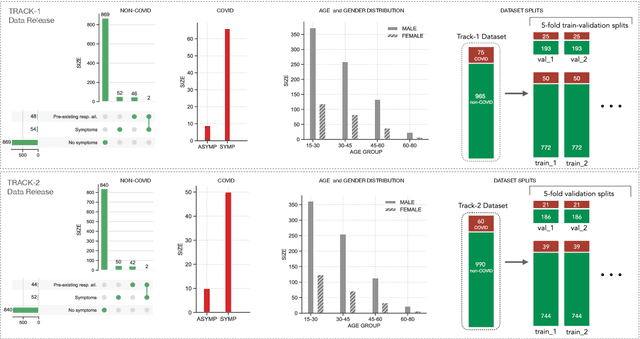
The DiCOVA challenge aims at accelerating research in diagnosing COVID-19 using acoustics (DiCOVA), a topic at the intersection of speech and audio processing, respiratory health diagnosis, and machine learning. This challenge is an open call for researchers to analyze a dataset of sound recordings collected from COVID-19 infected and non-COVID-19 individuals for a two-class classification. These recordings were collected via crowdsourcing from multiple countries, through a website application. The challenge features two tracks, one focusing on cough sounds, and the other on using a collection of breath, sustained vowel phonation, and number counting speech recordings. In this paper, we introduce the challenge and provide a detailed description of the task, and present a baseline system for the task.
Neural PLDA Modeling for End-to-End Speaker Verification
Aug 11, 2020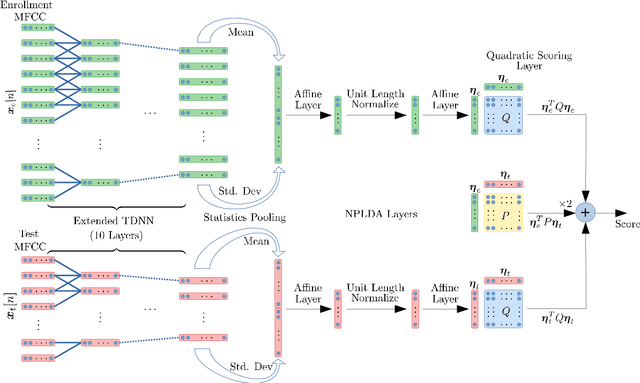
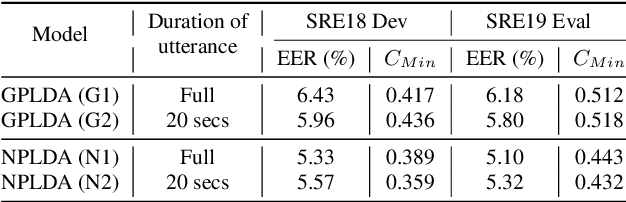

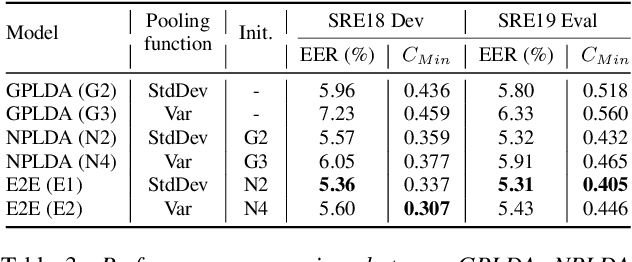
While deep learning models have made significant advances in supervised classification problems, the application of these models for out-of-set verification tasks like speaker recognition has been limited to deriving feature embeddings. The state-of-the-art x-vector PLDA based speaker verification systems use a generative model based on probabilistic linear discriminant analysis (PLDA) for computing the verification score. Recently, we had proposed a neural network approach for backend modeling in speaker verification called the neural PLDA (NPLDA) where the likelihood ratio score of the generative PLDA model is posed as a discriminative similarity function and the learnable parameters of the score function are optimized using a verification cost. In this paper, we extend this work to achieve joint optimization of the embedding neural network (x-vector network) with the NPLDA network in an end-to-end (E2E) fashion. This proposed end-to-end model is optimized directly from the acoustic features with a verification cost function and during testing, the model directly outputs the likelihood ratio score. With various experiments using the NIST speaker recognition evaluation (SRE) 2018 and 2019 datasets, we show that the proposed E2E model improves significantly over the x-vector PLDA baseline speaker verification system.
NISP: A Multi-lingual Multi-accent Dataset for Speaker Profiling
Jul 12, 2020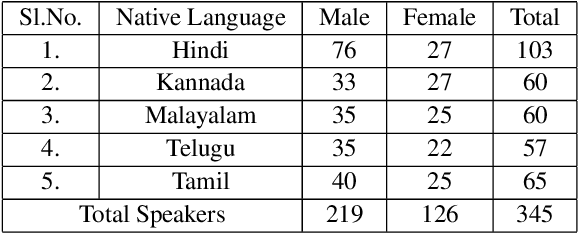
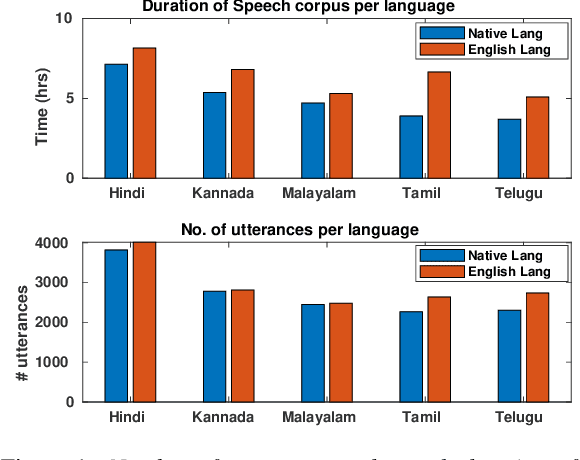
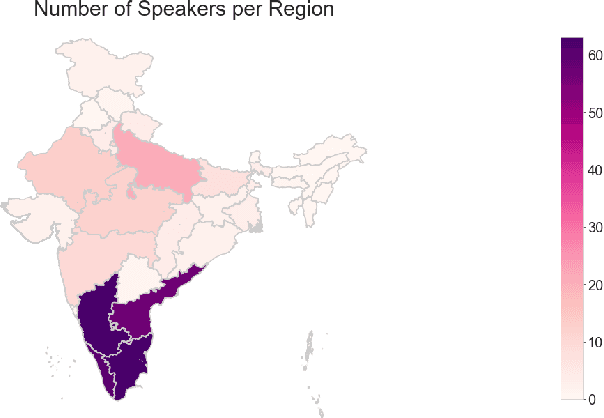
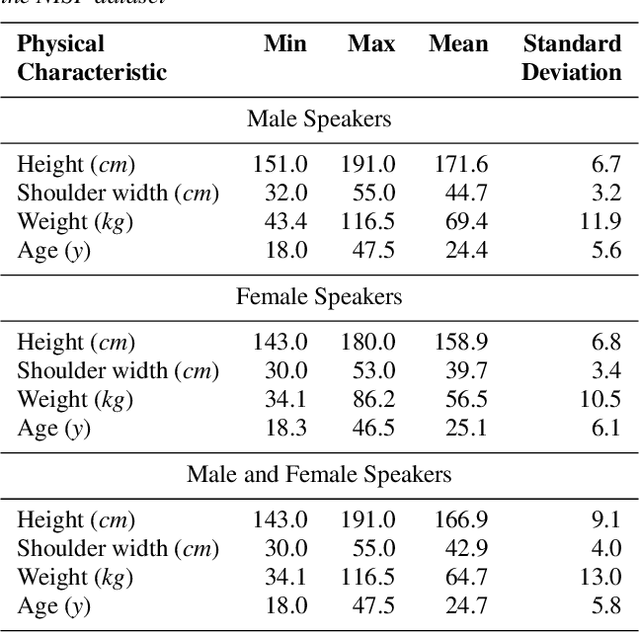
Many commercial and forensic applications of speech demand the extraction of information about the speaker characteristics, which falls into the broad category of speaker profiling. The speaker characteristics needed for profiling include physical traits of the speaker like height, age, and gender of the speaker along with the native language of the speaker. Many of the datasets available have only partial information for speaker profiling. In this paper, we attempt to overcome this limitation by developing a new dataset which has speech data from five different Indian languages along with English. The metadata information for speaker profiling applications like linguistic information, regional information, and physical characteristics of a speaker are also collected. We call this dataset as NITK-IISc Multilingual Multi-accent Speaker Profiling (NISP) dataset. The description of the dataset, potential applications, and baseline results for speaker profiling on this dataset are provided in this paper.
NPLDA: A Deep Neural PLDA Model for Speaker Verification
Feb 10, 2020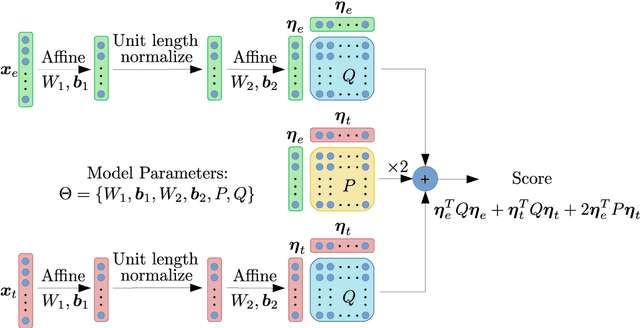

The state-of-art approach for speaker verification consists of a neural network based embedding extractor along with a backend generative model such as the Probabilistic Linear Discriminant Analysis (PLDA). In this work, we propose a neural network approach for backend modeling in speaker recognition. The likelihood ratio score of the generative PLDA model is posed as a discriminative similarity function and the learnable parameters of the score function are optimized using a verification cost. The proposed model, termed as neural PLDA (NPLDA), is initialized using the generative PLDA model parameters. The loss function for the NPLDA model is an approximation of the minimum detection cost function (DCF). The speaker recognition experiments using the NPLDA model are performed on the speaker verificiation task in the VOiCES datasets as well as the SITW challenge dataset. In these experiments, the NPLDA model optimized using the proposed loss function improves significantly over the state-of-art PLDA based speaker verification system.
LEAP System for SRE19 Challenge -- Improvements and Error Analysis
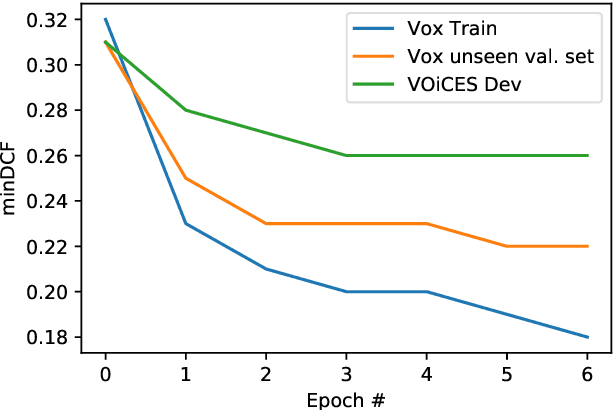
Feb 07, 2020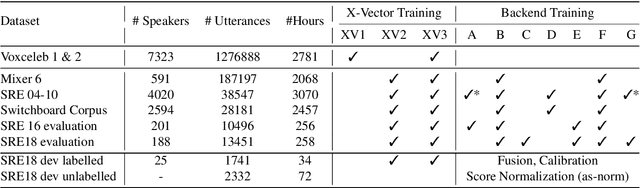

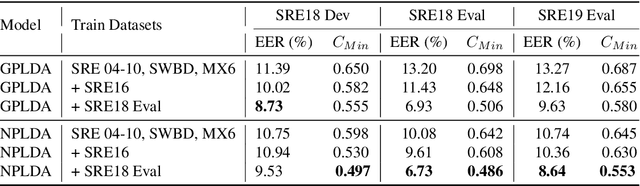
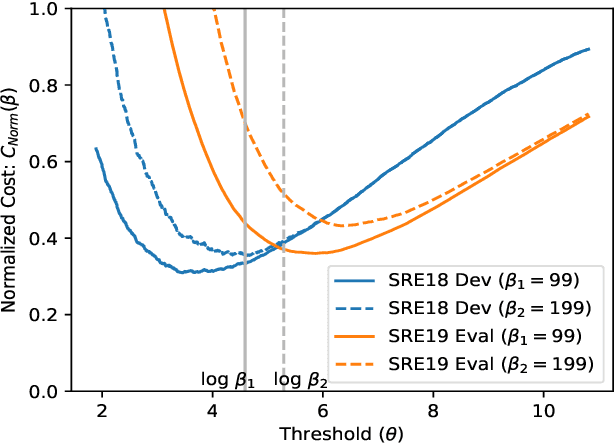
The NIST Speaker Recognition Evaluation - Conversational Telephone Speech (CTS) challenge 2019 was an open evaluation for the task of speaker verification in challenging conditions. In this paper, we provide a detailed account of the LEAP SRE system submitted to the CTS challenge focusing on the novel components in the back-end system modeling. All the systems used the time-delay neural network (TDNN) based x-vector embeddings. The x-vector system in our SRE19 submission used a large pool of training speakers (about 14k speakers). Following the x-vector extraction, we explored a neural network approach to backend score computation that was optimized for a speaker verification cost. The system combination of generative and neural PLDA models resulted in significant improvements for the SRE evaluation dataset. We also found additional gains for the SRE systems based on score normalization and calibration. Subsequent to the evaluations, we have performed a detailed analysis of the submitted systems. The analysis revealed the incremental gains obtained for different training dataset combinations as well as the modeling methods.