 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural PLDA Modeling for End-to-End Speaker Verification
Paper and Code
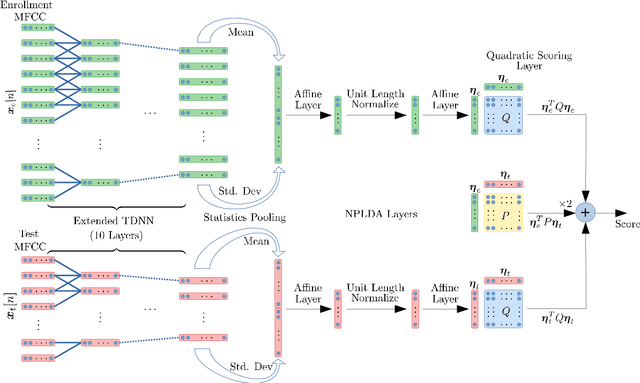
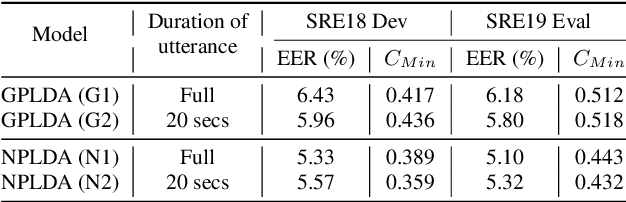

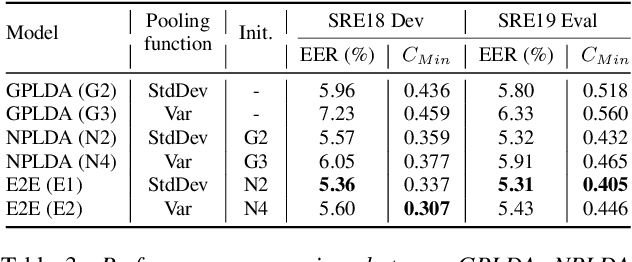
While deep learning models have made significant advances in supervised classification problems, the application of these models for out-of-set verification tasks like speaker recognition has been limited to deriving feature embeddings. The state-of-the-art x-vector PLDA based speaker verification systems use a generative model based on probabilistic linear discriminant analysis (PLDA) for computing the verification score. Recently, we had proposed a neural network approach for backend modeling in speaker verification called the neural PLDA (NPLDA) where the likelihood ratio score of the generative PLDA model is posed as a discriminative similarity function and the learnable parameters of the score function are optimized using a verification cost. In this paper, we extend this work to achieve joint optimization of the embedding neural network (x-vector network) with the NPLDA network in an end-to-end (E2E) fashion. This proposed end-to-end model is optimized directly from the acoustic features with a verification cost function and during testing, the model directly outputs the likelihood ratio score. With various experiments using the NIST speaker recognition evaluation (SRE) 2018 and 2019 datasets, we show that the proposed E2E model improves significantly over the x-vector PLDA baseline speaker verification system.