 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Movie Hits Before They Happen with LLMs
May 05, 2025Addressing the cold-start issue in content recommendation remains a critical ongoing challenge. In this work, we focus on tackling the cold-start problem for movies on a large entertainment platform. Our primary goal is to forecast the popularity of cold-start movies using Large Language Models (LLMs) leveraging movie metadata. This method could be integrated into retrieval systems within the personalization pipeline or could be adopted as a tool for editorial teams to ensure fair promotion of potentially overlooked movies that may be missed by traditional or algorithmic solutions. Our study validates the effectiveness of this approach compared to established baselines and those we developed.
Multi-modal Point-of-Care Diagnostics for COVID-19 Based On Acoustics and Symptoms
Jun 05, 2021
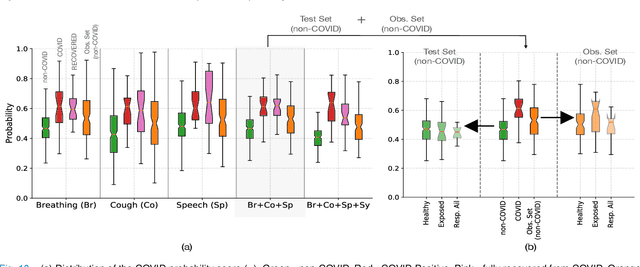
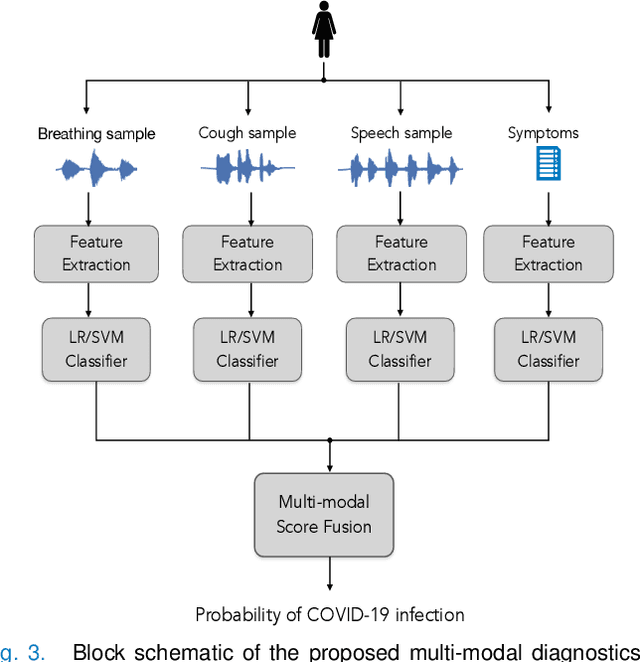
The research direction of identifying acoustic bio-markers of respiratory diseases has received renewed interest following the onset of COVID-19 pandemic. In this paper, we design an approach to COVID-19 diagnostic using crowd-sourced multi-modal data. The data resource, consisting of acoustic signals like cough, breathing, and speech signals, along with the data of symptoms, are recorded using a web-application over a period of ten months. We investigate the use of statistical descriptors of simple time-frequency features for acoustic signals and binary features for the presence of symptoms. Unlike previous works, we primarily focus on the application of simple linear classifiers like logistic regression and support vector machines for acoustic data while decision tree models are employed on the symptoms data. We show that a multi-modal integration of acoustics and symptoms classifiers achieves an area-under-curve (AUC) of 92.40, a significant improvement over any individual modality. Several ablation experiments are also provided which highlight the acoustic and symptom dimensions that are important for the task of COVID-19 diagnostics.
DiCOVA Challenge: Dataset, task, and baseline system for COVID-19 diagnosis using acoustics
Apr 05, 2021
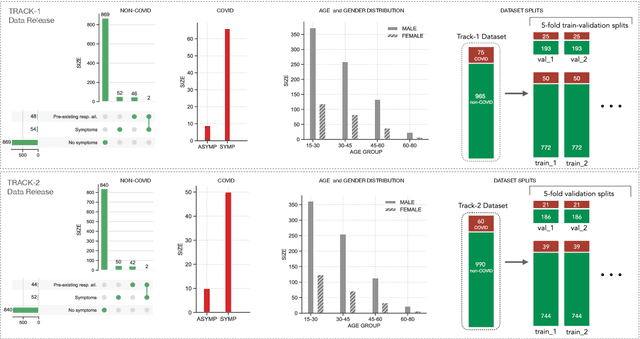
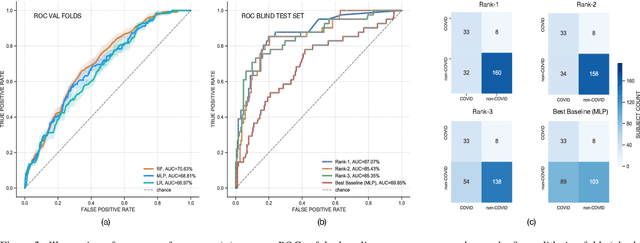
The DiCOVA challenge aims at accelerating research in diagnosing COVID-19 using acoustics (DiCOVA), a topic at the intersection of speech and audio processing, respiratory health diagnosis, and machine learning. This challenge is an open call for researchers to analyze a dataset of sound recordings collected from COVID-19 infected and non-COVID-19 individuals for a two-class classification. These recordings were collected via crowdsourcing from multiple countries, through a website application. The challenge features two tracks, one focusing on cough sounds, and the other on using a collection of breath, sustained vowel phonation, and number counting speech recordings. In this paper, we introduce the challenge and provide a detailed description of the task, and present a baseline system for the task.
Role of Attentive History Selection in Conversational Information Seeking
Feb 07, 2021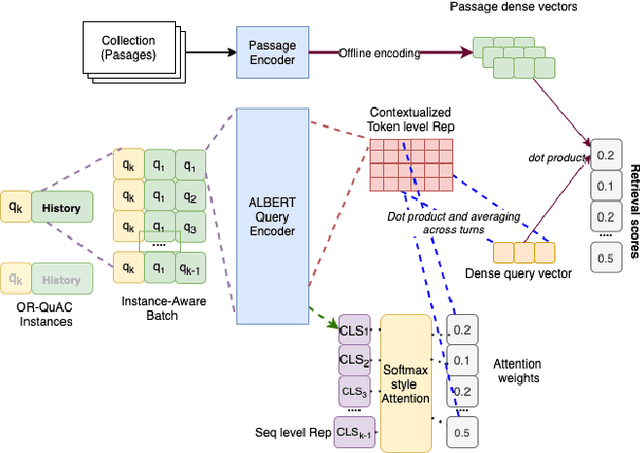

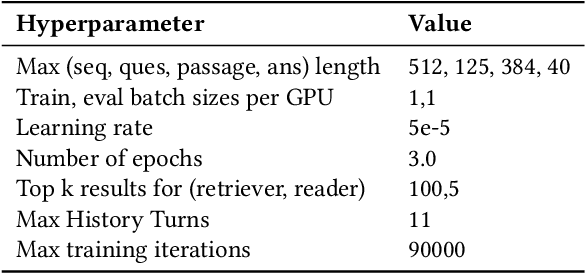
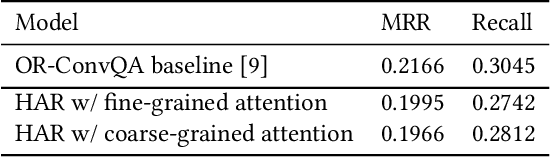
The rise of intelligent assistant systems like Siri and Alexa have led to the emergence of Conversational Search, a research track of Information Retrieval (IR) that involves interactive and iterative information-seeking user-system dialog. Recently released OR-QuAC and TCAsT19 datasets narrow their research focus on the retrieval aspect of conversational search i.e. fetching the relevant documents (passages) from a large collection using the conversational search history. Currently proposed models for these datasets incorporate history in retrieval by appending the last N turns to the current question before encoding. We propose to use another history selection approach that dynamically selects and weighs history turns using the attention mechanism for question embedding. The novelty of our approach lies in experimenting with soft attention-based history selection approach in an open-retrieval setting.