 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Point-of-Care Diagnostics for COVID-19 Based On Acoustics and Symptoms
Jun 05, 2021
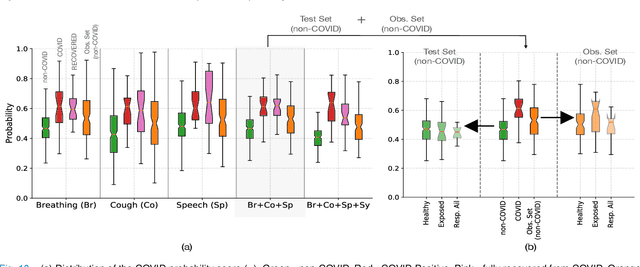
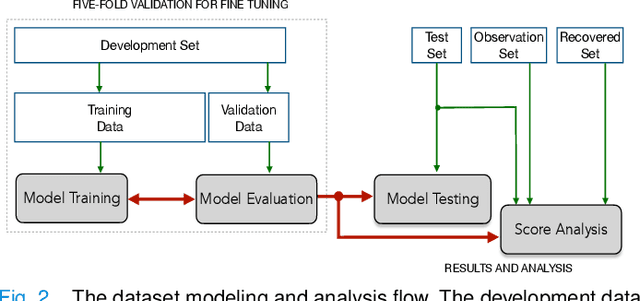
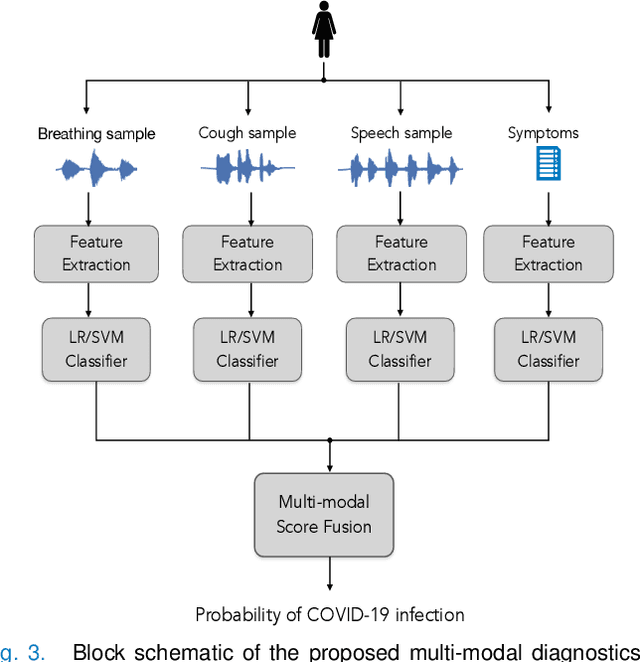
The research direction of identifying acoustic bio-markers of respiratory diseases has received renewed interest following the onset of COVID-19 pandemic. In this paper, we design an approach to COVID-19 diagnostic using crowd-sourced multi-modal data. The data resource, consisting of acoustic signals like cough, breathing, and speech signals, along with the data of symptoms, are recorded using a web-application over a period of ten months. We investigate the use of statistical descriptors of simple time-frequency features for acoustic signals and binary features for the presence of symptoms. Unlike previous works, we primarily focus on the application of simple linear classifiers like logistic regression and support vector machines for acoustic data while decision tree models are employed on the symptoms data. We show that a multi-modal integration of acoustics and symptoms classifiers achieves an area-under-curve (AUC) of 92.40, a significant improvement over any individual modality. Several ablation experiments are also provided which highlight the acoustic and symptom dimensions that are important for the task of COVID-19 diagnostics.
DiCOVA Challenge: Dataset, task, and baseline system for COVID-19 diagnosis using acoustics
Apr 05, 2021
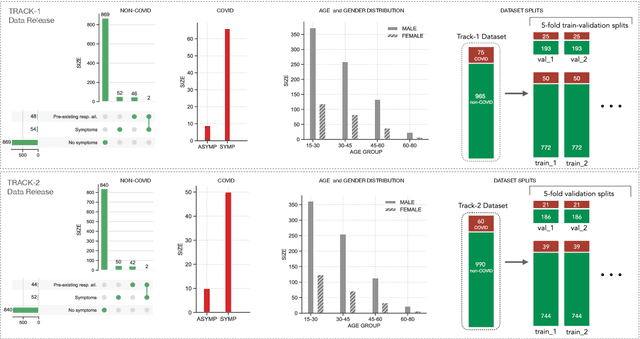
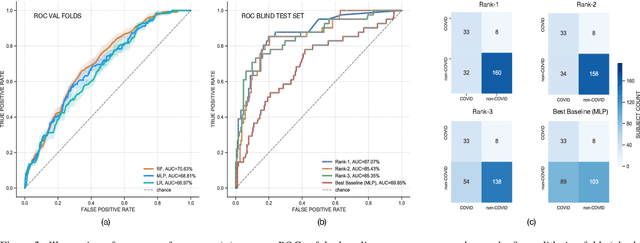
The DiCOVA challenge aims at accelerating research in diagnosing COVID-19 using acoustics (DiCOVA), a topic at the intersection of speech and audio processing, respiratory health diagnosis, and machine learning. This challenge is an open call for researchers to analyze a dataset of sound recordings collected from COVID-19 infected and non-COVID-19 individuals for a two-class classification. These recordings were collected via crowdsourcing from multiple countries, through a website application. The challenge features two tracks, one focusing on cough sounds, and the other on using a collection of breath, sustained vowel phonation, and number counting speech recordings. In this paper, we introduce the challenge and provide a detailed description of the task, and present a baseline system for the task.