 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialDF: Benchmark Dataset and Detection Model for Mitigating Harmful Deepfake Content on Social Media Platforms
Jun 05, 2025The rapid advancement of deep generative models has significantly improved the realism of synthetic media, presenting both opportunities and security challenges. While deepfake technology has valuable applications in entertainment and accessibility, it has emerged as a potent vector for misinformation campaigns, particularly on social media. Existing detection frameworks struggle to distinguish between benign and adversarially generated deepfakes engineered to manipulate public perception. To address this challenge, we introduce SocialDF, a curated dataset reflecting real-world deepfake challenges on social media platforms. This dataset encompasses high-fidelity deepfakes sourced from various online ecosystems, ensuring broad coverage of manipulative techniques. We propose a novel LLM-based multi-factor detection approach that combines facial recognition, automated speech transcription, and a multi-agent LLM pipeline to cross-verify audio-visual cues. Our methodology emphasizes robust, multi-modal verification techniques that incorporate linguistic, behavioral, and contextual analysis to effectively discern synthetic media from authentic content.
Role of Attentive History Selection in Conversational Information Seeking
Feb 07, 2021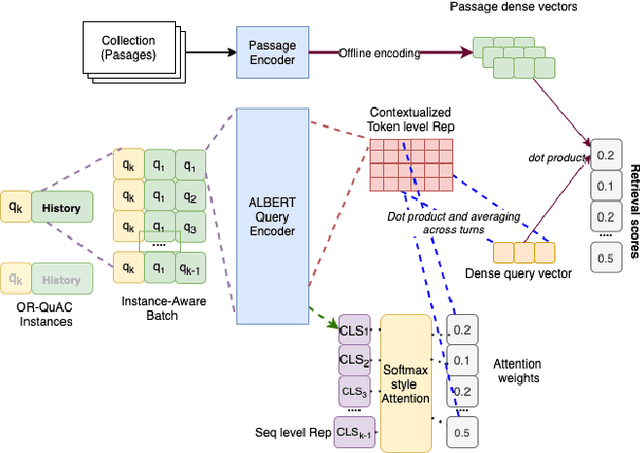

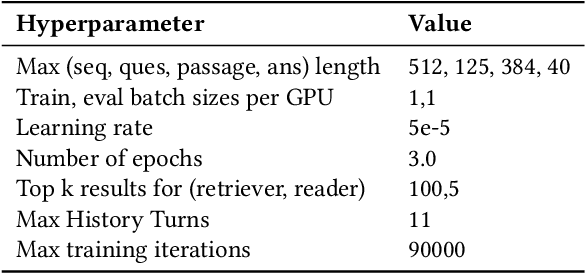
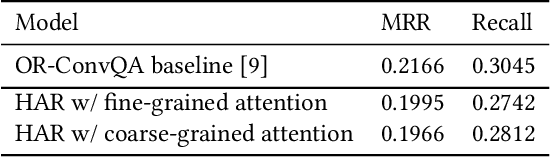
The rise of intelligent assistant systems like Siri and Alexa have led to the emergence of Conversational Search, a research track of Information Retrieval (IR) that involves interactive and iterative information-seeking user-system dialog. Recently released OR-QuAC and TCAsT19 datasets narrow their research focus on the retrieval aspect of conversational search i.e. fetching the relevant documents (passages) from a large collection using the conversational search history. Currently proposed models for these datasets incorporate history in retrieval by appending the last N turns to the current question before encoding. We propose to use another history selection approach that dynamically selects and weighs history turns using the attention mechanism for question embedding. The novelty of our approach lies in experimenting with soft attention-based history selection approach in an open-retrieval setting.
BERT Based Multilingual Machine Comprehension in English and Hindi
Jun 02, 2020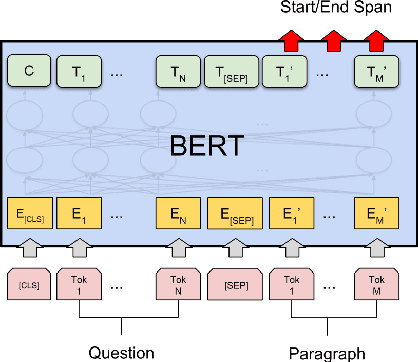


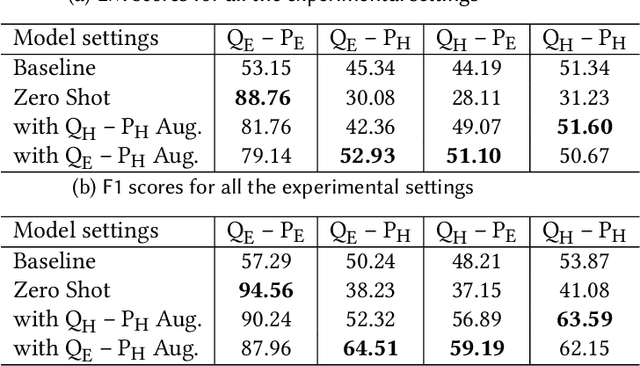
Multilingual Machine Comprehension (MMC) is a Question-Answering (QA) sub-task that involves quoting the answer for a question from a given snippet, where the question and the snippet can be in different languages. Recently released multilingual variant of BERT (m-BERT), pre-trained with 104 languages, has performed well in both zero-shot and fine-tuned settings for multilingual tasks; however, it has not been used for English-Hindi MMC yet. We, therefore, present in this article, our experiments with m-BERT for MMC in zero-shot, mono-lingual (e.g. Hindi Question-Hindi Snippet) and cross-lingual (e.g. English QuestionHindi Snippet) fine-tune setups. These model variants are evaluated on all possible multilingual settings and results are compared against the current state-of-the-art sequential QA system for these languages. Experiments show that m-BERT, with fine-tuning, improves performance on all evaluation settings across both the datasets used by the prior model, therefore establishing m-BERT based MMC as the new state-of-the-art for English and Hindi. We also publish our results on an extended version of the recently released XQuAD dataset, which we propose to use as the evaluation benchmark for future research.
Conversational Machine Comprehension: a Literature Review
Jun 01, 2020
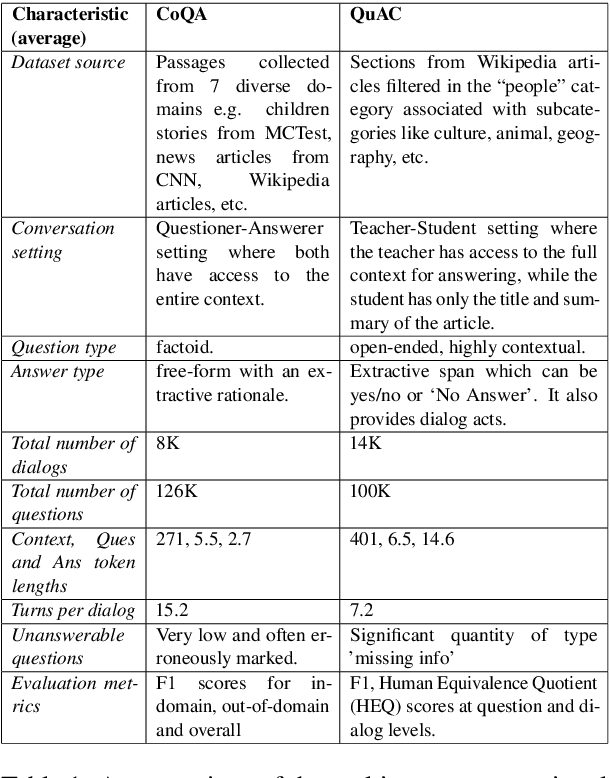

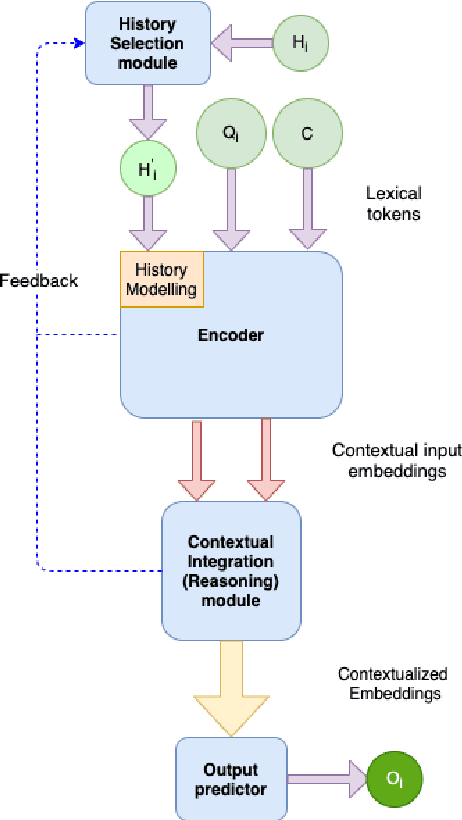
Conversational Machine Comprehension (CMC) is a research track in conversational AI which expects the machine to understand an open-domain text and thereafter engage in a multi-turn conversation to answer questions related to the text. While most of the research in Machine Reading Comprehension (MRC) revolves around single-turn question answering, multi-turn CMC has recently gained prominence, thanks to the advancement in natural language understanding via neural language models like BERT and the introduction of large-scale conversational datasets like CoQA and QuAC. The rise in interest has, however, led to a flurry of concurrent publications, each with a different yet structurally similar modeling approach and an inconsistent view of the surrounding literature. With the volume of model submissions to conversational datasets increasing every year, there exists a need to consolidate the scattered knowledge in this domain to streamline future research. This literature review, therefore, is a first-of-its-kind attempt at providing a holistic overview of CMC, with an emphasis on the common trends across recently published models, specifically in their approach to tackling conversational history. It focuses on synthesizing a generic framework for CMC models, rather than describing the models individually. The review is intended to serve as a compendium for future researchers in this domain.