 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolaRiS: Scalable Real-to-Sim Evaluations for Generalist Robot Policies
Dec 18, 2025A significant challenge for robot learning research is our ability to accurately measure and compare the performance of robot policies. Benchmarking in robotics is historically challenging due to the stochasticity, reproducibility, and time-consuming nature of real-world rollouts. This challenge is exacerbated for recent generalist policies, which has to be evaluated across a wide variety of scenes and tasks. Evaluation in simulation offers a scalable complement to real world evaluations, but the visual and physical domain gap between existing simulation benchmarks and the real world has made them an unreliable signal for policy improvement. Furthermore, building realistic and diverse simulated environments has traditionally required significant human effort and expertise. To bridge the gap, we introduce Policy Evaluation and Environment Reconstruction in Simulation (PolaRiS), a scalable real-to-sim framework for high-fidelity simulated robot evaluation. PolaRiS utilizes neural reconstruction methods to turn short video scans of real-world scenes into interactive simulation environments. Additionally, we develop a simple simulation data co-training recipe that bridges remaining real-to-sim gaps and enables zero-shot evaluation in unseen simulation environments. Through extensive paired evaluations between simulation and the real world, we demonstrate that PolaRiS evaluations provide a much stronger correlation to real world generalist policy performance than existing simulated benchmarks. Its simplicity also enables rapid creation of diverse simulated environments. As such, this work takes a step towards distributed and democratized evaluation for the next generation of robotic foundation models.
SocialDF: Benchmark Dataset and Detection Model for Mitigating Harmful Deepfake Content on Social Media Platforms
Jun 05, 2025The rapid advancement of deep generative models has significantly improved the realism of synthetic media, presenting both opportunities and security challenges. While deepfake technology has valuable applications in entertainment and accessibility, it has emerged as a potent vector for misinformation campaigns, particularly on social media. Existing detection frameworks struggle to distinguish between benign and adversarially generated deepfakes engineered to manipulate public perception. To address this challenge, we introduce SocialDF, a curated dataset reflecting real-world deepfake challenges on social media platforms. This dataset encompasses high-fidelity deepfakes sourced from various online ecosystems, ensuring broad coverage of manipulative techniques. We propose a novel LLM-based multi-factor detection approach that combines facial recognition, automated speech transcription, and a multi-agent LLM pipeline to cross-verify audio-visual cues. Our methodology emphasizes robust, multi-modal verification techniques that incorporate linguistic, behavioral, and contextual analysis to effectively discern synthetic media from authentic content.
DRAWER: Digital Reconstruction and Articulation With Environment Realism
Apr 22, 2025Creating virtual digital replicas from real-world data unlocks significant potential across domains like gaming and robotics. In this paper, we present DRAWER, a novel framework that converts a video of a static indoor scene into a photorealistic and interactive digital environment. Our approach centers on two main contributions: (i) a reconstruction module based on a dual scene representation that reconstructs the scene with fine-grained geometric details, and (ii) an articulation module that identifies articulation types and hinge positions, reconstructs simulatable shapes and appearances and integrates them into the scene. The resulting virtual environment is photorealistic, interactive, and runs in real time, with compatibility for game engines and robotic simulation platforms. We demonstrate the potential of DRAWER by using it to automatically create an interactive game in Unreal Engine and to enable real-to-sim-to-real transfer for robotics applications.
Robot Learning with Super-Linear Scaling
Dec 02, 2024Scaling robot learning requires data collection pipelines that scale favorably with human effort. In this work, we propose Crowdsourcing and Amortizing Human Effort for Real-to-Sim-to-Real(CASHER), a pipeline for scaling up data collection and learning in simulation where the performance scales superlinearly with human effort. The key idea is to crowdsource digital twins of real-world scenes using 3D reconstruction and collect large-scale data in simulation, rather than the real-world. Data collection in simulation is initially driven by RL, bootstrapped with human demonstrations. As the training of a generalist policy progresses across environments, its generalization capabilities can be used to replace human effort with model generated demonstrations. This results in a pipeline where behavioral data is collected in simulation with continually reducing human effort. We show that CASHER demonstrates zero-shot and few-shot scaling laws on three real-world tasks across diverse scenarios. We show that CASHER enables fine-tuning of pre-trained policies to a target scenario using a video scan without any additional human effort. See our project website: https://casher-robot-learning.github.io/CASHER/
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
PBSCSR: The Piano Bootleg Score Composer Style Recognition Dataset
Feb 07, 2024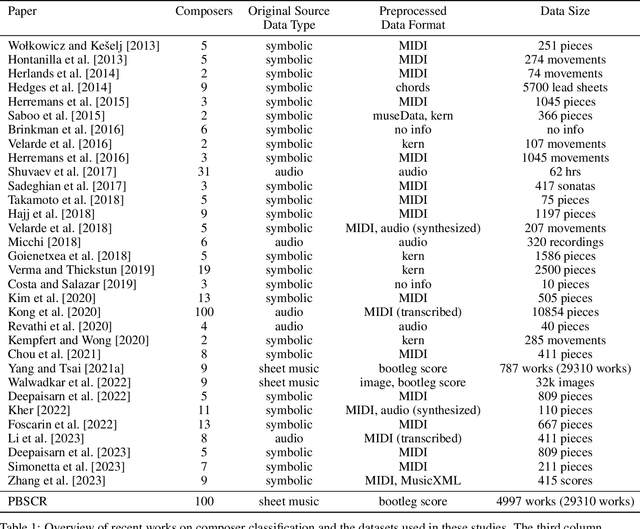


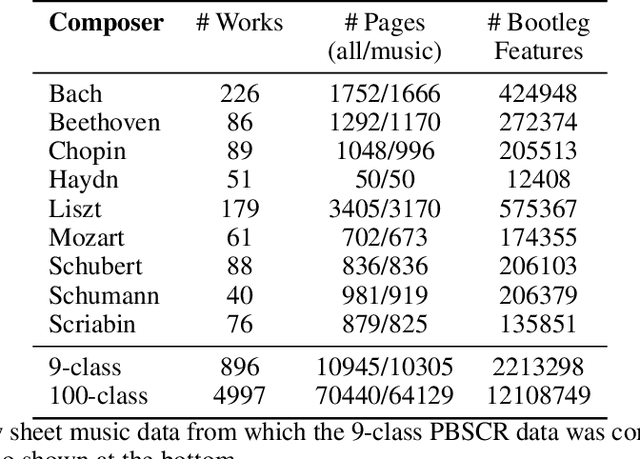
This article motivates, describes, and presents the PBSCSR dataset for studying composer style recognition of piano sheet music. Our overarching goal was to create a dataset for studying composer style recognition that is "as accessible as MNIST and as challenging as ImageNet". To achieve this goal, we use a previously proposed feature representation of sheet music called a bootleg score, which encodes the position of noteheads relative to the staff lines. Using this representation, we sample fixed-length bootleg score fragments from piano sheet music images on IMSLP. The dataset itself contains 40,000 62x64 bootleg score images for a 9-way classification task, 100,000 62x64 bootleg score images for a 100-way classification task, and 29,310 unlabeled variable-length bootleg score images for pretraining. The labeled data is presented in a form that mirrors MNIST images, in order to make it extremely easy to visualize, manipulate, and train models in an efficient manner. Additionally, we include relevant metadata to allow access to the underlying raw sheet music images and other related data on IMSLP. We describe several research tasks that could be studied with the dataset, including variations of composer style recognition in a few-shot or zero-shot setting. For tasks that have previously proposed models, we release code and baseline results for future works to compare against. We also discuss open research questions that the PBSCSR data is especially well suited to facilitate research on and areas of fruitful exploration in future work.