 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Learning with Super-Linear Scaling
Dec 02, 2024Scaling robot learning requires data collection pipelines that scale favorably with human effort. In this work, we propose Crowdsourcing and Amortizing Human Effort for Real-to-Sim-to-Real(CASHER), a pipeline for scaling up data collection and learning in simulation where the performance scales superlinearly with human effort. The key idea is to crowdsource digital twins of real-world scenes using 3D reconstruction and collect large-scale data in simulation, rather than the real-world. Data collection in simulation is initially driven by RL, bootstrapped with human demonstrations. As the training of a generalist policy progresses across environments, its generalization capabilities can be used to replace human effort with model generated demonstrations. This results in a pipeline where behavioral data is collected in simulation with continually reducing human effort. We show that CASHER demonstrates zero-shot and few-shot scaling laws on three real-world tasks across diverse scenarios. We show that CASHER enables fine-tuning of pre-trained policies to a target scenario using a video scan without any additional human effort. See our project website: https://casher-robot-learning.github.io/CASHER/
DexHub and DART: Towards Internet Scale Robot Data Collection
Nov 04, 2024



The quest to build a generalist robotic system is impeded by the scarcity of diverse and high-quality data. While real-world data collection effort exist, requirements for robot hardware, physical environment setups, and frequent resets significantly impede the scalability needed for modern learning frameworks. We introduce DART, a teleoperation platform designed for crowdsourcing that reimagines robotic data collection by leveraging cloud-based simulation and augmented reality (AR) to address many limitations of prior data collection efforts. Our user studies highlight that DART enables higher data collection throughput and lower physical fatigue compared to real-world teleoperation. We also demonstrate that policies trained using DART-collected datasets successfully transfer to reality and are robust to unseen visual disturbances. All data collected through DART is automatically stored in our cloud-hosted database, DexHub, which will be made publicly available upon curation, paving the path for DexHub to become an ever-growing data hub for robot learning. Videos are available at: https://dexhub.ai/project
From Imitation to Refinement -- Residual RL for Precise Visual Assembly
Jul 23, 2024Behavior cloning (BC) currently stands as a dominant paradigm for learning real-world visual manipulation. However, in tasks that require locally corrective behaviors like multi-part assembly, learning robust policies purely from human demonstrations remains challenging. Reinforcement learning (RL) can mitigate these limitations by allowing policies to acquire locally corrective behaviors through task reward supervision and exploration. This paper explores the use of RL fine-tuning to improve upon BC-trained policies in precise manipulation tasks. We analyze and overcome technical challenges associated with using RL to directly train policy networks that incorporate modern architectural components like diffusion models and action chunking. We propose training residual policies on top of frozen BC-trained diffusion models using standard policy gradient methods and sparse rewards, an approach we call ResiP (Residual for Precise manipulation). Our experimental results demonstrate that this residual learning framework can significantly improve success rates beyond the base BC-trained models in high-precision assembly tasks by learning corrective actions. We also show that by combining ResiP with teacher-student distillation and visual domain randomization, our method can enable learning real-world policies for robotic assembly directly from RGB images. Find videos and code at \url{https://residual-assembly.github.io}.
JUICER: Data-Efficient Imitation Learning for Robotic Assembly
Apr 09, 2024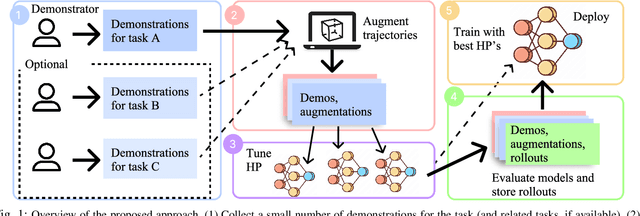
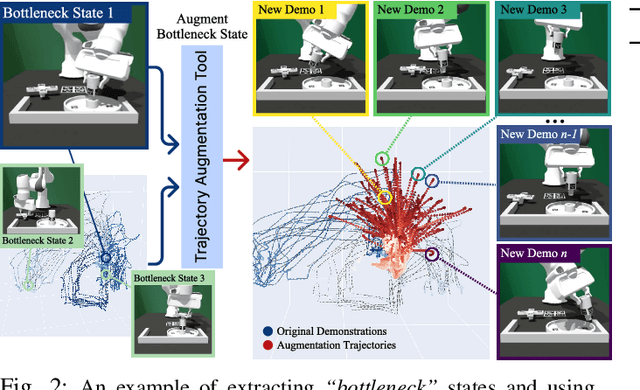

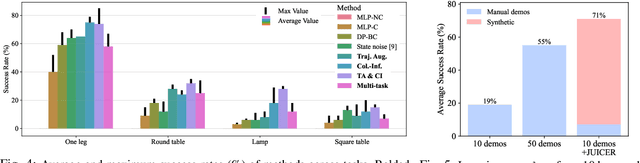
While learning from demonstrations is powerful for acquiring visuomotor policies, high-performance imitation without large demonstration datasets remains challenging for tasks requiring precise, long-horizon manipulation. This paper proposes a pipeline for improving imitation learning performance with a small human demonstration budget. We apply our approach to assembly tasks that require precisely grasping, reorienting, and inserting multiple parts over long horizons and multiple task phases. Our pipeline combines expressive policy architectures and various techniques for dataset expansion and simulation-based data augmentation. These help expand dataset support and supervise the model with locally corrective actions near bottleneck regions requiring high precision. We demonstrate our pipeline on four furniture assembly tasks in simulation, enabling a manipulator to assemble up to five parts over nearly 2500 time steps directly from RGB images, outperforming imitation and data augmentation baselines. Project website: https://imitation-juicer.github.io/.