 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEM: Multi-Scale Embodied Memory for Vision Language Action Models
Mar 04, 2026Conventionally, memory in end-to-end robotic learning involves inputting a sequence of past observations into the learned policy. However, in complex multi-stage real-world tasks, the robot's memory must represent past events at multiple levels of granularity: from long-term memory that captures abstracted semantic concepts (e.g., a robot cooking dinner should remember which stages of the recipe are already done) to short-term memory that captures recent events and compensates for occlusions (e.g., a robot remembering the object it wants to pick up once its arm occludes it). In this work, our main insight is that an effective memory architecture for long-horizon robotic control should combine multiple modalities to capture these different levels of abstraction. We introduce Multi-Scale Embodied Memory (MEM), an approach for mixed-modal long-horizon memory in robot policies. MEM combines video-based short-horizon memory, compressed via a video encoder, with text-based long-horizon memory. Together, they enable robot policies to perform tasks that span up to fifteen minutes, like cleaning up a kitchen, or preparing a grilled cheese sandwich. Additionally, we find that memory enables MEM policies to intelligently adapt manipulation strategies in-context.
PolaRiS: Scalable Real-to-Sim Evaluations for Generalist Robot Policies
Dec 18, 2025A significant challenge for robot learning research is our ability to accurately measure and compare the performance of robot policies. Benchmarking in robotics is historically challenging due to the stochasticity, reproducibility, and time-consuming nature of real-world rollouts. This challenge is exacerbated for recent generalist policies, which has to be evaluated across a wide variety of scenes and tasks. Evaluation in simulation offers a scalable complement to real world evaluations, but the visual and physical domain gap between existing simulation benchmarks and the real world has made them an unreliable signal for policy improvement. Furthermore, building realistic and diverse simulated environments has traditionally required significant human effort and expertise. To bridge the gap, we introduce Policy Evaluation and Environment Reconstruction in Simulation (PolaRiS), a scalable real-to-sim framework for high-fidelity simulated robot evaluation. PolaRiS utilizes neural reconstruction methods to turn short video scans of real-world scenes into interactive simulation environments. Additionally, we develop a simple simulation data co-training recipe that bridges remaining real-to-sim gaps and enables zero-shot evaluation in unseen simulation environments. Through extensive paired evaluations between simulation and the real world, we demonstrate that PolaRiS evaluations provide a much stronger correlation to real world generalist policy performance than existing simulated benchmarks. Its simplicity also enables rapid creation of diverse simulated environments. As such, this work takes a step towards distributed and democratized evaluation for the next generation of robotic foundation models.
$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
Learning Long-Context Diffusion Policies via Past-Token Prediction
May 14, 2025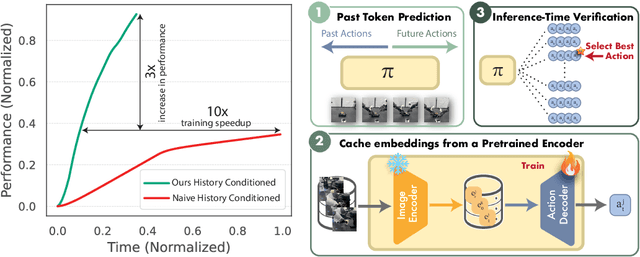


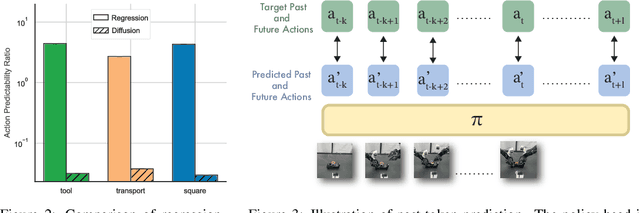
Reasoning over long sequences of observations and actions is essential for many robotic tasks. Yet, learning effective long-context policies from demonstrations remains challenging. As context length increases, training becomes increasingly expensive due to rising memory demands, and policy performance often degrades as a result of spurious correlations. Recent methods typically sidestep these issues by truncating context length, discarding historical information that may be critical for subsequent decisions. In this paper, we propose an alternative approach that explicitly regularizes the retention of past information. We first revisit the copycat problem in imitation learning and identify an opposite challenge in recent diffusion policies: rather than over-relying on prior actions, they often fail to capture essential dependencies between past and future actions. To address this, we introduce Past-Token Prediction (PTP), an auxiliary task in which the policy learns to predict past action tokens alongside future ones. This regularization significantly improves temporal modeling in the policy head, with minimal reliance on visual representations. Building on this observation, we further introduce a multistage training strategy: pre-train the visual encoder with short contexts, and fine-tune the policy head using cached long-context embeddings. This strategy preserves the benefits of PTP while greatly reducing memory and computational overhead. Finally, we extend PTP into a self-verification mechanism at test time, enabling the policy to score and select candidates consistent with past actions during inference. Experiments across four real-world and six simulated tasks demonstrate that our proposed method improves the performance of long-context diffusion policies by 3x and accelerates policy training by more than 10x.
Robot Learning with Super-Linear Scaling
Dec 02, 2024Scaling robot learning requires data collection pipelines that scale favorably with human effort. In this work, we propose Crowdsourcing and Amortizing Human Effort for Real-to-Sim-to-Real(CASHER), a pipeline for scaling up data collection and learning in simulation where the performance scales superlinearly with human effort. The key idea is to crowdsource digital twins of real-world scenes using 3D reconstruction and collect large-scale data in simulation, rather than the real-world. Data collection in simulation is initially driven by RL, bootstrapped with human demonstrations. As the training of a generalist policy progresses across environments, its generalization capabilities can be used to replace human effort with model generated demonstrations. This results in a pipeline where behavioral data is collected in simulation with continually reducing human effort. We show that CASHER demonstrates zero-shot and few-shot scaling laws on three real-world tasks across diverse scenarios. We show that CASHER enables fine-tuning of pre-trained policies to a target scenario using a video scan without any additional human effort. See our project website: https://casher-robot-learning.github.io/CASHER/
From Imitation to Refinement -- Residual RL for Precise Visual Assembly
Jul 23, 2024Behavior cloning (BC) currently stands as a dominant paradigm for learning real-world visual manipulation. However, in tasks that require locally corrective behaviors like multi-part assembly, learning robust policies purely from human demonstrations remains challenging. Reinforcement learning (RL) can mitigate these limitations by allowing policies to acquire locally corrective behaviors through task reward supervision and exploration. This paper explores the use of RL fine-tuning to improve upon BC-trained policies in precise manipulation tasks. We analyze and overcome technical challenges associated with using RL to directly train policy networks that incorporate modern architectural components like diffusion models and action chunking. We propose training residual policies on top of frozen BC-trained diffusion models using standard policy gradient methods and sparse rewards, an approach we call ResiP (Residual for Precise manipulation). Our experimental results demonstrate that this residual learning framework can significantly improve success rates beyond the base BC-trained models in high-precision assembly tasks by learning corrective actions. We also show that by combining ResiP with teacher-student distillation and visual domain randomization, our method can enable learning real-world policies for robotic assembly directly from RGB images. Find videos and code at \url{https://residual-assembly.github.io}.
Reconciling Reality through Simulation: A Real-to-Sim-to-Real Approach for Robust Manipulation
Mar 06, 2024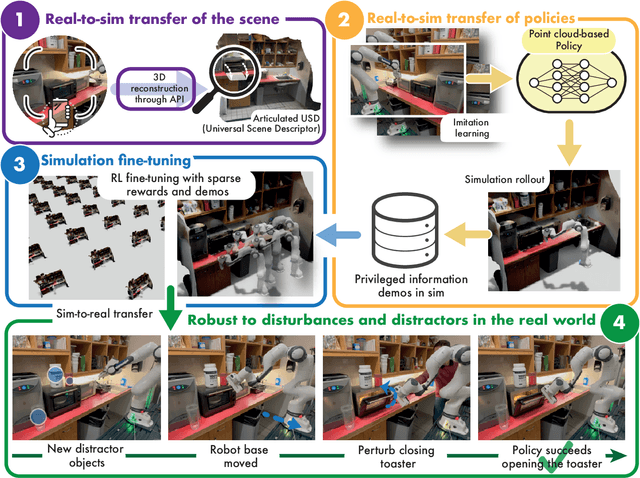



Imitation learning methods need significant human supervision to learn policies robust to changes in object poses, physical disturbances, and visual distractors. Reinforcement learning, on the other hand, can explore the environment autonomously to learn robust behaviors but may require impractical amounts of unsafe real-world data collection. To learn performant, robust policies without the burden of unsafe real-world data collection or extensive human supervision, we propose RialTo, a system for robustifying real-world imitation learning policies via reinforcement learning in "digital twin" simulation environments constructed on the fly from small amounts of real-world data. To enable this real-to-sim-to-real pipeline, RialTo proposes an easy-to-use interface for quickly scanning and constructing digital twins of real-world environments. We also introduce a novel "inverse distillation" procedure for bringing real-world demonstrations into simulated environments for efficient fine-tuning, with minimal human intervention and engineering required. We evaluate RialTo across a variety of robotic manipulation problems in the real world, such as robustly stacking dishes on a rack, placing books on a shelf, and six other tasks. RialTo increases (over 67%) in policy robustness without requiring extensive human data collection. Project website and videos at https://real-to-sim-to-real.github.io/RialTo/
Autonomous Robotic Reinforcement Learning with Asynchronous Human Feedback
Oct 31, 2023Ideally, we would place a robot in a real-world environment and leave it there improving on its own by gathering more experience autonomously. However, algorithms for autonomous robotic learning have been challenging to realize in the real world. While this has often been attributed to the challenge of sample complexity, even sample-efficient techniques are hampered by two major challenges - the difficulty of providing well "shaped" rewards, and the difficulty of continual reset-free training. In this work, we describe a system for real-world reinforcement learning that enables agents to show continual improvement by training directly in the real world without requiring painstaking effort to hand-design reward functions or reset mechanisms. Our system leverages occasional non-expert human-in-the-loop feedback from remote users to learn informative distance functions to guide exploration while leveraging a simple self-supervised learning algorithm for goal-directed policy learning. We show that in the absence of resets, it is particularly important to account for the current "reachability" of the exploration policy when deciding which regions of the space to explore. Based on this insight, we instantiate a practical learning system - GEAR, which enables robots to simply be placed in real-world environments and left to train autonomously without interruption. The system streams robot experience to a web interface only requiring occasional asynchronous feedback from remote, crowdsourced, non-expert humans in the form of binary comparative feedback. We evaluate this system on a suite of robotic tasks in simulation and demonstrate its effectiveness at learning behaviors both in simulation and the real world. Project website https://guided-exploration-autonomous-rl.github.io/GEAR/.
Breadcrumbs to the Goal: Goal-Conditioned Exploration from Human-in-the-Loop Feedback
Jul 20, 2023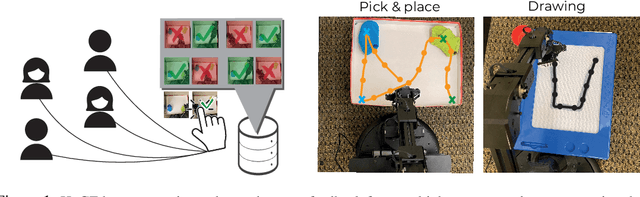



Exploration and reward specification are fundamental and intertwined challenges for reinforcement learning. Solving sequential decision-making tasks requiring expansive exploration requires either careful design of reward functions or the use of novelty-seeking exploration bonuses. Human supervisors can provide effective guidance in the loop to direct the exploration process, but prior methods to leverage this guidance require constant synchronous high-quality human feedback, which is expensive and impractical to obtain. In this work, we present a technique called Human Guided Exploration (HuGE), which uses low-quality feedback from non-expert users that may be sporadic, asynchronous, and noisy. HuGE guides exploration for reinforcement learning not only in simulation but also in the real world, all without meticulous reward specification. The key concept involves bifurcating human feedback and policy learning: human feedback steers exploration, while self-supervised learning from the exploration data yields unbiased policies. This procedure can leverage noisy, asynchronous human feedback to learn policies with no hand-crafted reward design or exploration bonuses. HuGE is able to learn a variety of challenging multi-stage robotic navigation and manipulation tasks in simulation using crowdsourced feedback from non-expert users. Moreover, this paradigm can be scaled to learning directly on real-world robots, using occasional, asynchronous feedback from human supervisors.