 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Robotic Reinforcement Learning with Asynchronous Human Feedback
Oct 31, 2023Ideally, we would place a robot in a real-world environment and leave it there improving on its own by gathering more experience autonomously. However, algorithms for autonomous robotic learning have been challenging to realize in the real world. While this has often been attributed to the challenge of sample complexity, even sample-efficient techniques are hampered by two major challenges - the difficulty of providing well "shaped" rewards, and the difficulty of continual reset-free training. In this work, we describe a system for real-world reinforcement learning that enables agents to show continual improvement by training directly in the real world without requiring painstaking effort to hand-design reward functions or reset mechanisms. Our system leverages occasional non-expert human-in-the-loop feedback from remote users to learn informative distance functions to guide exploration while leveraging a simple self-supervised learning algorithm for goal-directed policy learning. We show that in the absence of resets, it is particularly important to account for the current "reachability" of the exploration policy when deciding which regions of the space to explore. Based on this insight, we instantiate a practical learning system - GEAR, which enables robots to simply be placed in real-world environments and left to train autonomously without interruption. The system streams robot experience to a web interface only requiring occasional asynchronous feedback from remote, crowdsourced, non-expert humans in the form of binary comparative feedback. We evaluate this system on a suite of robotic tasks in simulation and demonstrate its effectiveness at learning behaviors both in simulation and the real world. Project website https://guided-exploration-autonomous-rl.github.io/GEAR/.
Breadcrumbs to the Goal: Goal-Conditioned Exploration from Human-in-the-Loop Feedback
Jul 20, 2023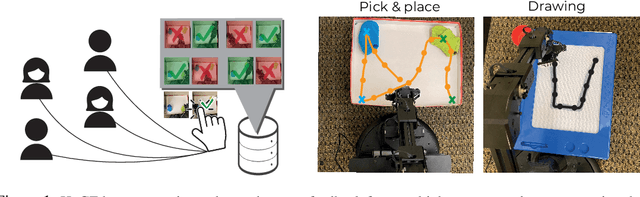



Exploration and reward specification are fundamental and intertwined challenges for reinforcement learning. Solving sequential decision-making tasks requiring expansive exploration requires either careful design of reward functions or the use of novelty-seeking exploration bonuses. Human supervisors can provide effective guidance in the loop to direct the exploration process, but prior methods to leverage this guidance require constant synchronous high-quality human feedback, which is expensive and impractical to obtain. In this work, we present a technique called Human Guided Exploration (HuGE), which uses low-quality feedback from non-expert users that may be sporadic, asynchronous, and noisy. HuGE guides exploration for reinforcement learning not only in simulation but also in the real world, all without meticulous reward specification. The key concept involves bifurcating human feedback and policy learning: human feedback steers exploration, while self-supervised learning from the exploration data yields unbiased policies. This procedure can leverage noisy, asynchronous human feedback to learn policies with no hand-crafted reward design or exploration bonuses. HuGE is able to learn a variety of challenging multi-stage robotic navigation and manipulation tasks in simulation using crowdsourced feedback from non-expert users. Moreover, this paradigm can be scaled to learning directly on real-world robots, using occasional, asynchronous feedback from human supervisors.