 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePBSCSR: The Piano Bootleg Score Composer Style Recognition Dataset
Feb 07, 2024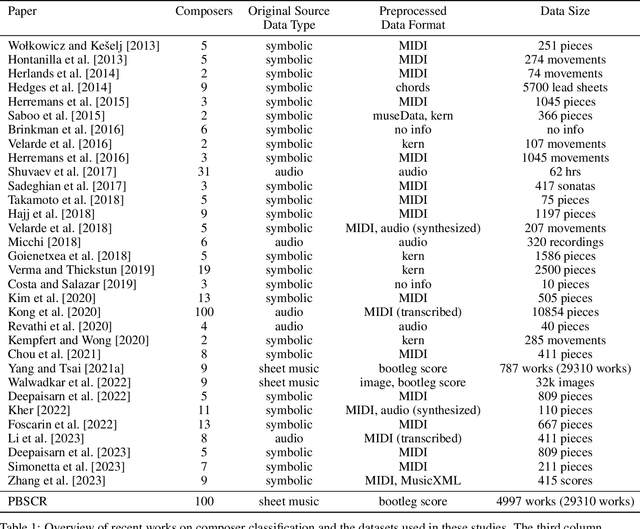


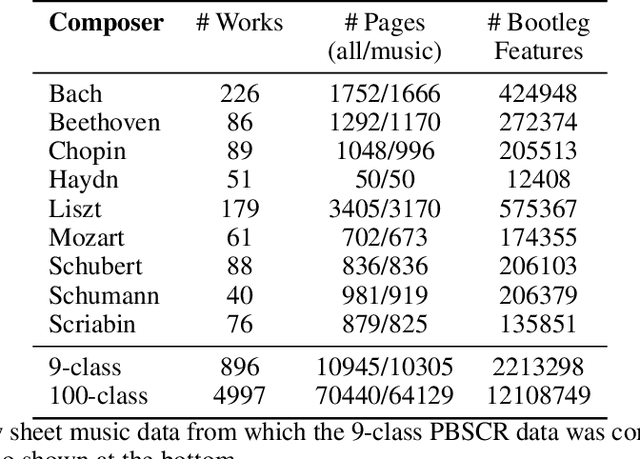
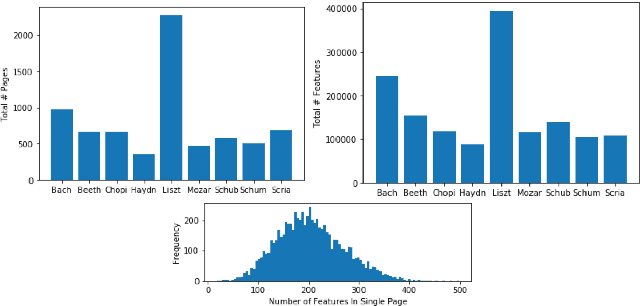
This article motivates, describes, and presents the PBSCSR dataset for studying composer style recognition of piano sheet music. Our overarching goal was to create a dataset for studying composer style recognition that is "as accessible as MNIST and as challenging as ImageNet". To achieve this goal, we use a previously proposed feature representation of sheet music called a bootleg score, which encodes the position of noteheads relative to the staff lines. Using this representation, we sample fixed-length bootleg score fragments from piano sheet music images on IMSLP. The dataset itself contains 40,000 62x64 bootleg score images for a 9-way classification task, 100,000 62x64 bootleg score images for a 100-way classification task, and 29,310 unlabeled variable-length bootleg score images for pretraining. The labeled data is presented in a form that mirrors MNIST images, in order to make it extremely easy to visualize, manipulate, and train models in an efficient manner. Additionally, we include relevant metadata to allow access to the underlying raw sheet music images and other related data on IMSLP. We describe several research tasks that could be studied with the dataset, including variations of composer style recognition in a few-shot or zero-shot setting. For tasks that have previously proposed models, we release code and baseline results for future works to compare against. We also discuss open research questions that the PBSCSR data is especially well suited to facilitate research on and areas of fruitful exploration in future work.
Composer Style Classification of Piano Sheet Music Images Using Language Model Pretraining
Jul 29, 2020

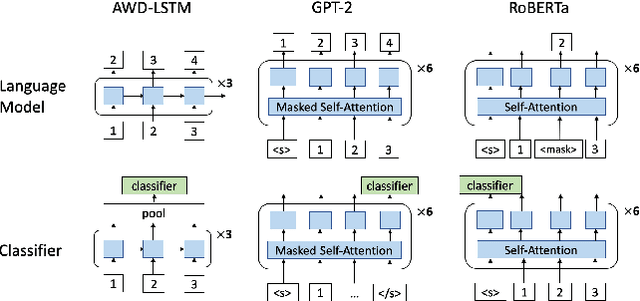
This paper studies composer style classification of piano sheet music images. Previous approaches to the composer classification task have been limited by a scarcity of data. We address this issue in two ways: (1) we recast the problem to be based on raw sheet music images rather than a symbolic music format, and (2) we propose an approach that can be trained on unlabeled data. Our approach first converts the sheet music image into a sequence of musical "words" based on the bootleg feature representation, and then feeds the sequence into a text classifier. We show that it is possible to significantly improve classifier performance by first training a language model on a set of unlabeled data, initializing the classifier with the pretrained language model weights, and then finetuning the classifier on a small amount of labeled data. We train AWD-LSTM, GPT-2, and RoBERTa language models on all piano sheet music images in IMSLP. We find that transformer-based architectures outperform CNN and LSTM models, and pretraining boosts classification accuracy for the GPT-2 model from 46\% to 70\% on a 9-way classification task. The trained model can also be used as a feature extractor that projects piano sheet music into a feature space that characterizes compositional style.
Camera-Based Piano Sheet Music Identification
Jul 29, 2020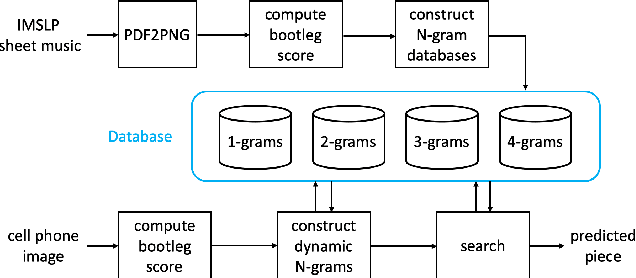
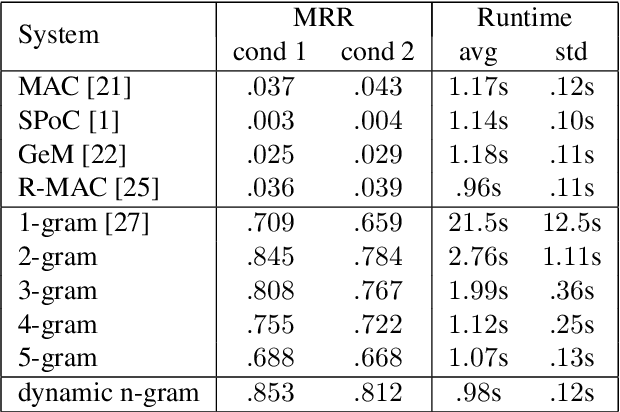

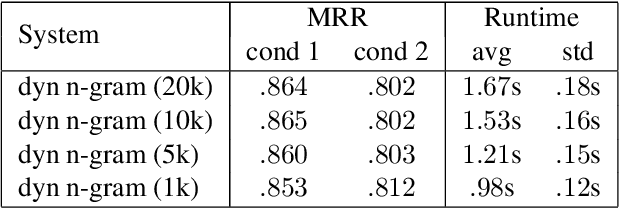
This paper presents a method for large-scale retrieval of piano sheet music images. Our work differs from previous studies on sheet music retrieval in two ways. First, we investigate the problem at a much larger scale than previous studies, using all solo piano sheet music images in the entire IMSLP dataset as a searchable database. Second, we use cell phone images of sheet music as our input queries, which lends itself to a practical, user-facing application. We show that a previously proposed fingerprinting method for sheet music retrieval is far too slow for a real-time application, and we diagnose its shortcomings. We propose a novel hashing scheme called dynamic n-gram fingerprinting that significantly reduces runtime while simultaneously boosting retrieval accuracy. In experiments on IMSLP data, our proposed method achieves a mean reciprocal rank of 0.85 and an average runtime of 0.98 seconds per query.