 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReefMapGS: Enabling Large-Scale Underwater Reconstruction by Closing the Loop Between Multimodal SLAM and Gaussian Splatting
Apr 13, 20263D Gaussian Splatting is a powerful visual representation, providing high-quality and efficient 3D scene reconstruction, but it is crucially dependent on accurate camera poses typically obtained from computationally intensive processes like structure-from-motion that are unsuitable for field robot applications. However, in these domains, multimodal sensor data from acoustic, inertial, pressure, and visual sensors are available and suitable for pose-graph optimization-based SLAM methods that can estimate the vehicle's trajectory and thus our needed camera poses while providing uncertainty. We propose a 3DGS-based incremental reconstruction framework, ReefMapGS, that builds an initial model from a high certainty region and progressively expands to incorporate the whole scene. We reconstruct the scene incrementally by interleaving local tracking of new image observations with optimization of the underlying 3DGS scene. These refined poses are integrated back into the pose-graph to globally optimize the whole trajectory. We show COLMAP-free 3D reconstruction of two underwater reef sites with complex geometry as well as more accurate global pose estimation of our AUV over survey trajectories spanning up to 700 m.
RewardUQ: A Unified Framework for Uncertainty-Aware Reward Models
Feb 27, 2026Reward models are central to aligning large language models (LLMs) with human preferences. Yet most approaches rely on pointwise reward estimates that overlook the epistemic uncertainty in reward models arising from limited human feedback. Recent work suggests that quantifying this uncertainty can reduce the costs of human annotation via uncertainty-guided active learning and mitigate reward overoptimization in LLM post-training. However, uncertainty-aware reward models have so far been adopted without thorough comparison, leaving them poorly understood. This work introduces a unified framework, RewardUQ, to systematically evaluate uncertainty quantification for reward models. We compare common methods along standard metrics measuring accuracy and calibration, and we propose a new ranking strategy incorporating both dimensions for a simplified comparison. Our experimental results suggest that model size and initialization have the most meaningful impact on performance, and most prior work could have benefited from alternative design choices. To foster the development and evaluation of new methods and aid the deployment in downstream applications, we release our open-source framework as a Python package. Our code is available at https://github.com/lasgroup/rewarduq.
UpSkill: Mutual Information Skill Learning for Structured Response Diversity in LLMs
Feb 25, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has improved the reasoning abilities of large language models (LLMs) on mathematics and programming tasks, but standard approaches that optimize single-attempt accuracy can inadvertently suppress response diversity across repeated attempts, narrowing exploration and overlooking underrepresented strategies. We introduce UpSkill, a training time method that adapts Mutual Information Skill Learning (MISL) to LLMs for optimizing pass@k correctness. We propose a novel reward that we implement within Group Relative Policy Optimization (GRPO): a token-level mutual information (MI) reward that encourages trajectory specificity to z. Experiments on GSM8K with three open-weight models, Llama 3.1-8B, Qwen 2.5-7B, and R1-Distilled-Qwen2.5-Math-1.5B, show that UpSkill improves multi-attempt metrics on the stronger base models, yielding mean gains of ~3% in pass@k for both Qwen and Llama without degrading pass@1. Additionally, we find both empirical and theoretical evidence that improvements in pass@k are closely tied to the mutual information objective.
TrajFlow: Multi-modal Motion Prediction via Flow Matching
Jun 10, 2025Efficient and accurate motion prediction is crucial for ensuring safety and informed decision-making in autonomous driving, particularly under dynamic real-world conditions that necessitate multi-modal forecasts. We introduce TrajFlow, a novel flow matching-based motion prediction framework that addresses the scalability and efficiency challenges of existing generative trajectory prediction methods. Unlike conventional generative approaches that employ i.i.d. sampling and require multiple inference passes to capture diverse outcomes, TrajFlow predicts multiple plausible future trajectories in a single pass, significantly reducing computational overhead while maintaining coherence across predictions. Moreover, we propose a ranking loss based on the Plackett-Luce distribution to improve uncertainty estimation of predicted trajectories. Additionally, we design a self-conditioning training technique that reuses the model's own predictions to construct noisy inputs during a second forward pass, thereby improving generalization and accelerating inference. Extensive experiments on the large-scale Waymo Open Motion Dataset (WOMD) demonstrate that TrajFlow achieves state-of-the-art performance across various key metrics, underscoring its effectiveness for safety-critical autonomous driving applications. The code and other details are available on the project website https://traj-flow.github.io/.
DataS^3: Dataset Subset Selection for Specialization
Apr 22, 2025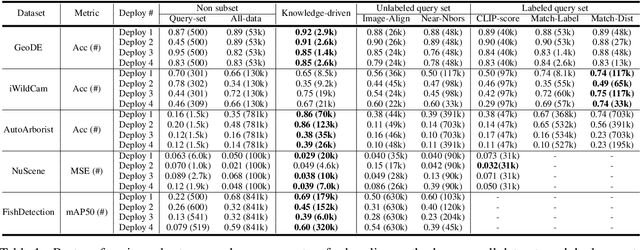
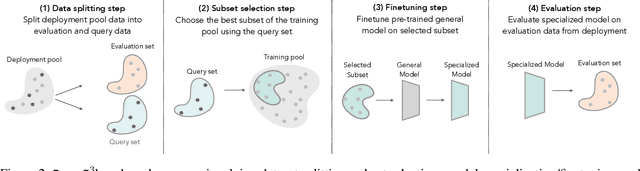
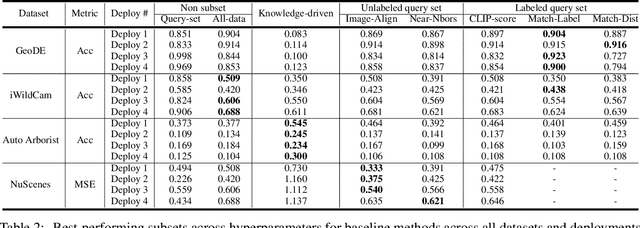
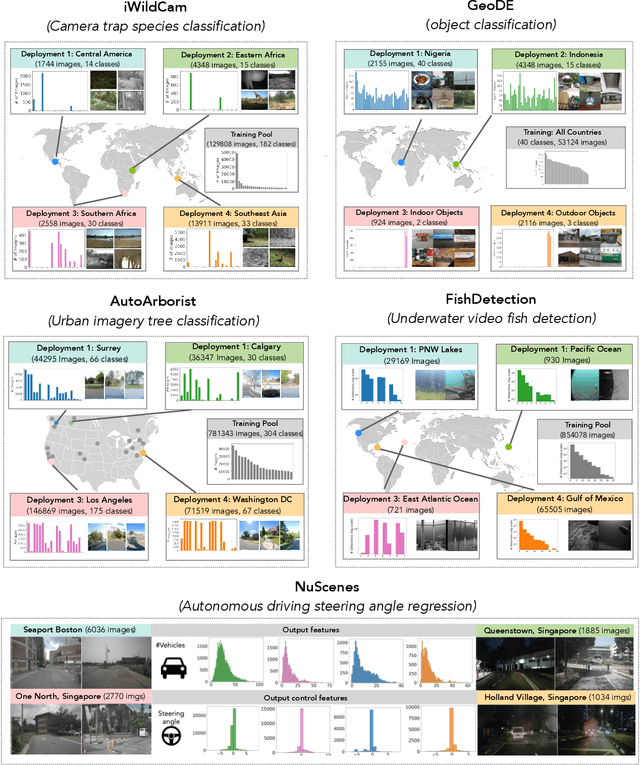
In many real-world machine learning (ML) applications (e.g. detecting broken bones in x-ray images, detecting species in camera traps), in practice models need to perform well on specific deployments (e.g. a specific hospital, a specific national park) rather than the domain broadly. However, deployments often have imbalanced, unique data distributions. Discrepancy between the training distribution and the deployment distribution can lead to suboptimal performance, highlighting the need to select deployment-specialized subsets from the available training data. We formalize dataset subset selection for specialization (DS3): given a training set drawn from a general distribution and a (potentially unlabeled) query set drawn from the desired deployment-specific distribution, the goal is to select a subset of the training data that optimizes deployment performance. We introduce DataS^3; the first dataset and benchmark designed specifically for the DS3 problem. DataS^3 encompasses diverse real-world application domains, each with a set of distinct deployments to specialize in. We conduct a comprehensive study evaluating algorithms from various families--including coresets, data filtering, and data curation--on DataS^3, and find that general-distribution methods consistently fail on deployment-specific tasks. Additionally, we demonstrate the existence of manually curated (deployment-specific) expert subsets that outperform training on all available data with accuracy gains up to 51.3 percent. Our benchmark highlights the critical role of tailored dataset curation in enhancing performance and training efficiency on deployment-specific distributions, which we posit will only become more important as global, public datasets become available across domains and ML models are deployed in the real world.
On Verbalized Confidence Scores for LLMs
Dec 19, 2024
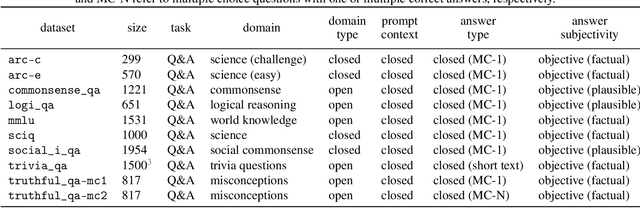

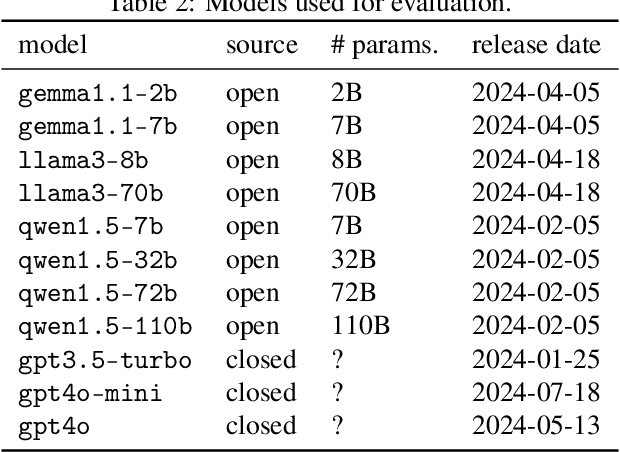
The rise of large language models (LLMs) and their tight integration into our daily life make it essential to dedicate efforts towards their trustworthiness. Uncertainty quantification for LLMs can establish more human trust into their responses, but also allows LLM agents to make more informed decisions based on each other's uncertainty. To estimate the uncertainty in a response, internal token logits, task-specific proxy models, or sampling of multiple responses are commonly used. This work focuses on asking the LLM itself to verbalize its uncertainty with a confidence score as part of its output tokens, which is a promising way for prompt- and model-agnostic uncertainty quantification with low overhead. Using an extensive benchmark, we assess the reliability of verbalized confidence scores with respect to different datasets, models, and prompt methods. Our results reveal that the reliability of these scores strongly depends on how the model is asked, but also that it is possible to extract well-calibrated confidence scores with certain prompt methods. We argue that verbalized confidence scores can become a simple but effective and versatile uncertainty quantification method in the future. Our code is available at https://github.com/danielyxyang/llm-verbalized-uq .
SeaSplat: Representing Underwater Scenes with 3D Gaussian Splatting and a Physically Grounded Image Formation Model
Sep 25, 2024We introduce SeaSplat, a method to enable real-time rendering of underwater scenes leveraging recent advances in 3D radiance fields. Underwater scenes are challenging visual environments, as rendering through a medium such as water introduces both range and color dependent effects on image capture. We constrain 3D Gaussian Splatting (3DGS), a recent advance in radiance fields enabling rapid training and real-time rendering of full 3D scenes, with a physically grounded underwater image formation model. Applying SeaSplat to the real-world scenes from SeaThru-NeRF dataset, a scene collected by an underwater vehicle in the US Virgin Islands, and simulation-degraded real-world scenes, not only do we see increased quantitative performance on rendering novel viewpoints from the scene with the medium present, but are also able to recover the underlying true color of the scene and restore renders to be without the presence of the intervening medium. We show that the underwater image formation helps learn scene structure, with better depth maps, as well as show that our improvements maintain the significant computational improvements afforded by leveraging a 3D Gaussian representation.
Rank2Reward: Learning Shaped Reward Functions from Passive Video
Apr 23, 2024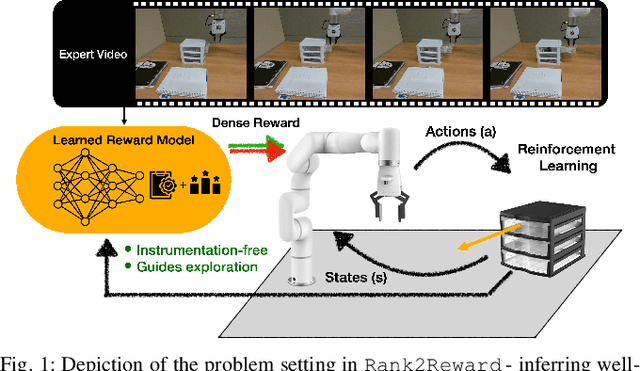
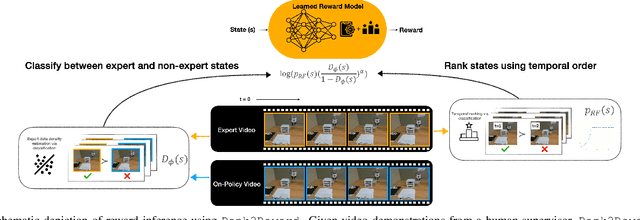


Teaching robots novel skills with demonstrations via human-in-the-loop data collection techniques like kinesthetic teaching or teleoperation puts a heavy burden on human supervisors. In contrast to this paradigm, it is often significantly easier to provide raw, action-free visual data of tasks being performed. Moreover, this data can even be mined from video datasets or the web. Ideally, this data can serve to guide robot learning for new tasks in novel environments, informing both "what" to do and "how" to do it. A powerful way to encode both the "what" and the "how" is to infer a well-shaped reward function for reinforcement learning. The challenge is determining how to ground visual demonstration inputs into a well-shaped and informative reward function. We propose a technique Rank2Reward for learning behaviors from videos of tasks being performed without access to any low-level states and actions. We do so by leveraging the videos to learn a reward function that measures incremental "progress" through a task by learning how to temporally rank the video frames in a demonstration. By inferring an appropriate ranking, the reward function is able to guide reinforcement learning by indicating when task progress is being made. This ranking function can be integrated into an adversarial imitation learning scheme resulting in an algorithm that can learn behaviors without exploiting the learned reward function. We demonstrate the effectiveness of Rank2Reward at learning behaviors from raw video on a number of tabletop manipulation tasks in both simulations and on a real-world robotic arm. We also demonstrate how Rank2Reward can be easily extended to be applicable to web-scale video datasets.
Can Text-to-image Model Assist Multi-modal Learning for Visual Recognition with Visual Modality Missing?
Feb 14, 2024Multi-modal learning has emerged as an increasingly promising avenue in vision recognition, driving innovations across diverse domains ranging from media and education to healthcare and transportation. Despite its success, the robustness of multi-modal learning for visual recognition is often challenged by the unavailability of a subset of modalities, especially the visual modality. Conventional approaches to mitigate missing modalities in multi-modal learning rely heavily on algorithms and modality fusion schemes. In contrast, this paper explores the use of text-to-image models to assist multi-modal learning. Specifically, we propose a simple but effective multi-modal learning framework GTI-MM to enhance the data efficiency and model robustness against missing visual modality by imputing the missing data with generative transformers. Using multiple multi-modal datasets with visual recognition tasks, we present a comprehensive analysis of diverse conditions involving missing visual modality in data, including model training. Our findings reveal that synthetic images benefit training data efficiency with visual data missing in training and improve model robustness with visual data missing involving training and testing. Moreover, we demonstrate GTI-MM is effective with lower generation quantity and simple prompt techniques.
Context Unlocks Emotions: Text-based Emotion Classification Dataset Auditing with Large Language Models
Nov 06, 2023



The lack of contextual information in text data can make the annotation process of text-based emotion classification datasets challenging. As a result, such datasets often contain labels that fail to consider all the relevant emotions in the vocabulary. This misalignment between text inputs and labels can degrade the performance of machine learning models trained on top of them. As re-annotating entire datasets is a costly and time-consuming task that cannot be done at scale, we propose to use the expressive capabilities of large language models to synthesize additional context for input text to increase its alignment with the annotated emotional labels. In this work, we propose a formal definition of textual context to motivate a prompting strategy to enhance such contextual information. We provide both human and empirical evaluation to demonstrate the efficacy of the enhanced context. Our method improves alignment between inputs and their human-annotated labels from both an empirical and human-evaluated standpoint.