 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Verbalized Confidence Scores for LLMs
Paper and Code

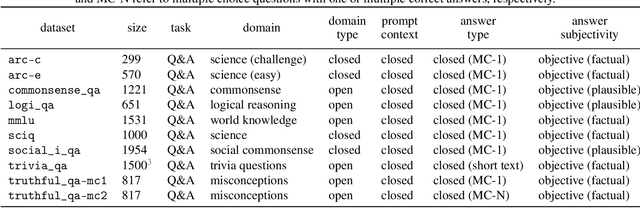

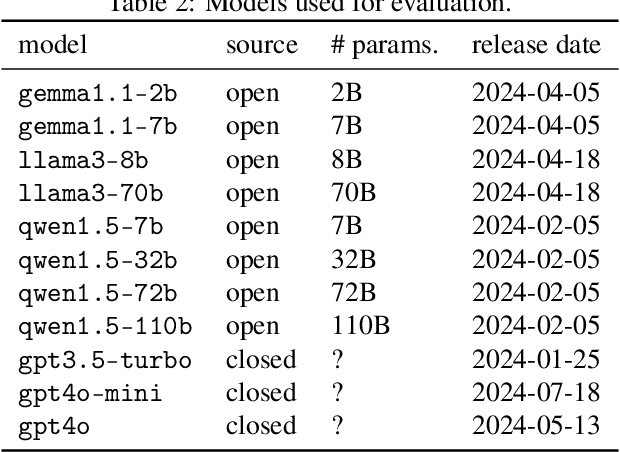
The rise of large language models (LLMs) and their tight integration into our daily life make it essential to dedicate efforts towards their trustworthiness. Uncertainty quantification for LLMs can establish more human trust into their responses, but also allows LLM agents to make more informed decisions based on each other's uncertainty. To estimate the uncertainty in a response, internal token logits, task-specific proxy models, or sampling of multiple responses are commonly used. This work focuses on asking the LLM itself to verbalize its uncertainty with a confidence score as part of its output tokens, which is a promising way for prompt- and model-agnostic uncertainty quantification with low overhead. Using an extensive benchmark, we assess the reliability of verbalized confidence scores with respect to different datasets, models, and prompt methods. Our results reveal that the reliability of these scores strongly depends on how the model is asked, but also that it is possible to extract well-calibrated confidence scores with certain prompt methods. We argue that verbalized confidence scores can become a simple but effective and versatile uncertainty quantification method in the future. Our code is available at https://github.com/danielyxyang/llm-verbalized-uq .