 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePBSCSR: The Piano Bootleg Score Composer Style Recognition Dataset
Paper and Code
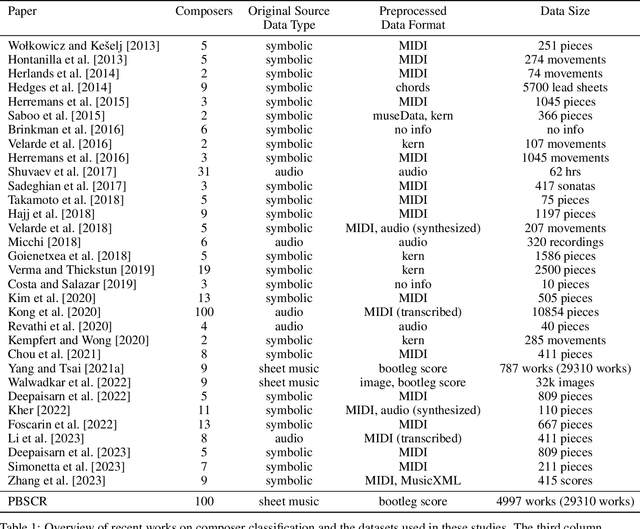


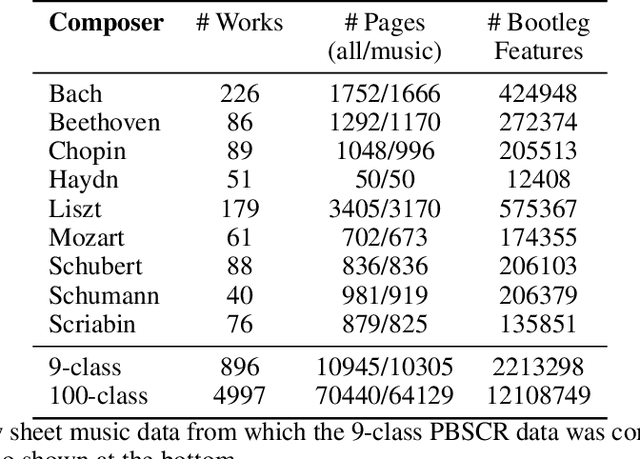
This article motivates, describes, and presents the PBSCSR dataset for studying composer style recognition of piano sheet music. Our overarching goal was to create a dataset for studying composer style recognition that is "as accessible as MNIST and as challenging as ImageNet". To achieve this goal, we use a previously proposed feature representation of sheet music called a bootleg score, which encodes the position of noteheads relative to the staff lines. Using this representation, we sample fixed-length bootleg score fragments from piano sheet music images on IMSLP. The dataset itself contains 40,000 62x64 bootleg score images for a 9-way classification task, 100,000 62x64 bootleg score images for a 100-way classification task, and 29,310 unlabeled variable-length bootleg score images for pretraining. The labeled data is presented in a form that mirrors MNIST images, in order to make it extremely easy to visualize, manipulate, and train models in an efficient manner. Additionally, we include relevant metadata to allow access to the underlying raw sheet music images and other related data on IMSLP. We describe several research tasks that could be studied with the dataset, including variations of composer style recognition in a few-shot or zero-shot setting. For tasks that have previously proposed models, we release code and baseline results for future works to compare against. We also discuss open research questions that the PBSCSR data is especially well suited to facilitate research on and areas of fruitful exploration in future work.