 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT Based Multilingual Machine Comprehension in English and Hindi
Paper and Code
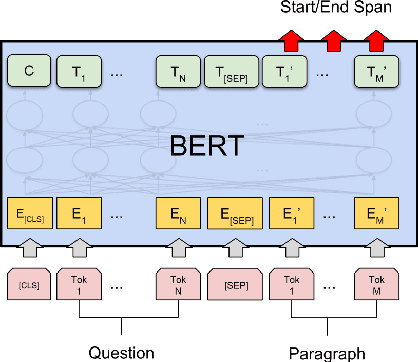


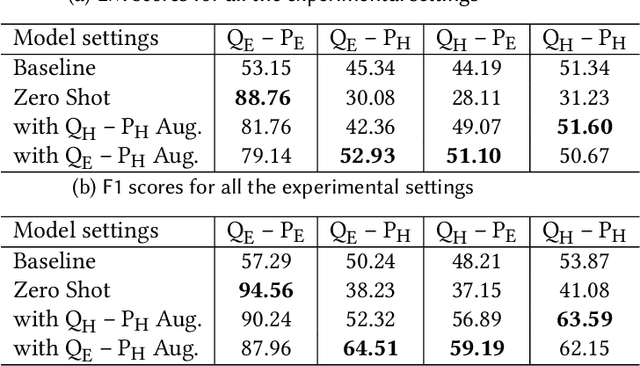
Multilingual Machine Comprehension (MMC) is a Question-Answering (QA) sub-task that involves quoting the answer for a question from a given snippet, where the question and the snippet can be in different languages. Recently released multilingual variant of BERT (m-BERT), pre-trained with 104 languages, has performed well in both zero-shot and fine-tuned settings for multilingual tasks; however, it has not been used for English-Hindi MMC yet. We, therefore, present in this article, our experiments with m-BERT for MMC in zero-shot, mono-lingual (e.g. Hindi Question-Hindi Snippet) and cross-lingual (e.g. English QuestionHindi Snippet) fine-tune setups. These model variants are evaluated on all possible multilingual settings and results are compared against the current state-of-the-art sequential QA system for these languages. Experiments show that m-BERT, with fine-tuning, improves performance on all evaluation settings across both the datasets used by the prior model, therefore establishing m-BERT based MMC as the new state-of-the-art for English and Hindi. We also publish our results on an extended version of the recently released XQuAD dataset, which we propose to use as the evaluation benchmark for future research.