 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Injected Prompt Based Fine-tuning for Multi-label Few-shot ICD Coding
Oct 07, 2022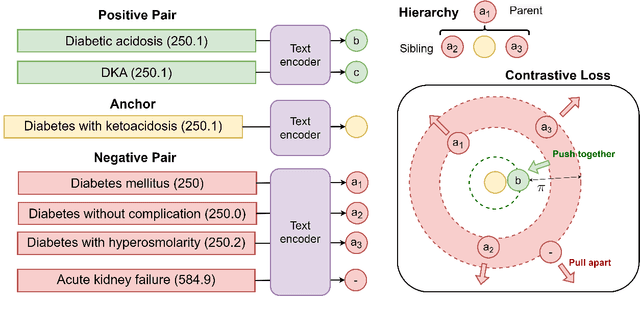
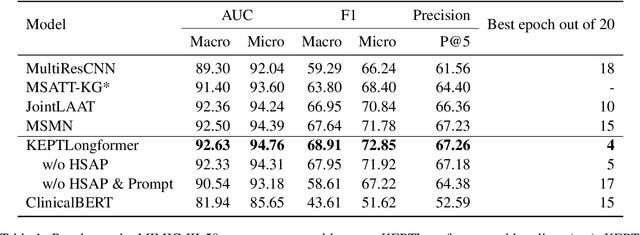
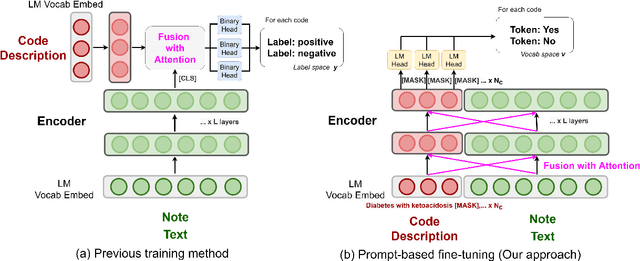
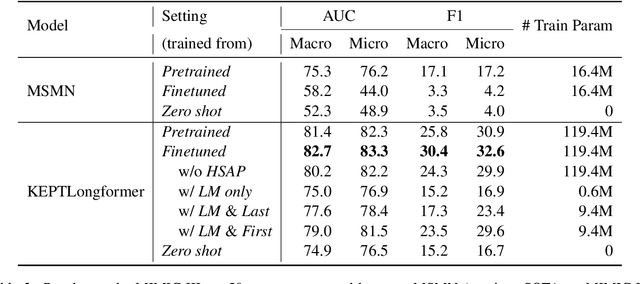
Automatic International Classification of Diseases (ICD) coding aims to assign multiple ICD codes to a medical note with average length of 3,000+ tokens. This task is challenging due to a high-dimensional space of multi-label assignment (tens of thousands of ICD codes) and the long-tail challenge: only a few codes (common diseases) are frequently assigned while most codes (rare diseases) are infrequently assigned. This study addresses the long-tail challenge by adapting a prompt-based fine-tuning technique with label semantics, which has been shown to be effective under few-shot setting. To further enhance the performance in medical domain, we propose a knowledge-enhanced longformer by injecting three domain-specific knowledge: hierarchy, synonym, and abbreviation with additional pretraining using contrastive learning. Experiments on MIMIC-III-full, a benchmark dataset of code assignment, show that our proposed method outperforms previous state-of-the-art method in 14.5% in marco F1 (from 10.3 to 11.8, P<0.001). To further test our model on few-shot setting, we created a new rare diseases coding dataset, MIMIC-III-rare50, on which our model improves marco F1 from 17.1 to 30.4 and micro F1 from 17.2 to 32.6 compared to previous method.
ScAN: Suicide Attempt and Ideation Events Dataset
May 12, 2022
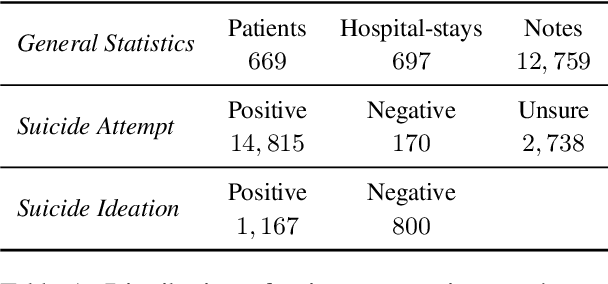

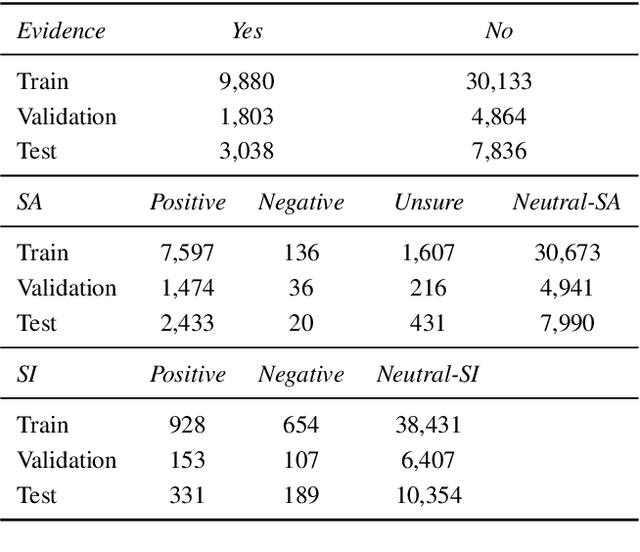
Suicide is an important public health concern and one of the leading causes of death worldwide. Suicidal behaviors, including suicide attempts (SA) and suicide ideations (SI), are leading risk factors for death by suicide. Information related to patients' previous and current SA and SI are frequently documented in the electronic health record (EHR) notes. Accurate detection of such documentation may help improve surveillance and predictions of patients' suicidal behaviors and alert medical professionals for suicide prevention efforts. In this study, we first built Suicide Attempt and Ideation Events (ScAN) dataset, a subset of the publicly available MIMIC III dataset spanning over 12k+ EHR notes with 19k+ annotated SA and SI events information. The annotations also contain attributes such as method of suicide attempt. We also provide a strong baseline model ScANER (Suicide Attempt and Ideation Events Retriever), a multi-task RoBERTa-based model with a retrieval module to extract all the relevant suicidal behavioral evidences from EHR notes of an hospital-stay and, and a prediction module to identify the type of suicidal behavior (SA and SI) concluded during the patient's stay at the hospital. ScANER achieved a macro-weighted F1-score of 0.83 for identifying suicidal behavioral evidences and a macro F1-score of 0.78 and 0.60 for classification of SA and SI for the patient's hospital-stay, respectively. ScAN and ScANER are publicly available.
Membership Inference Attack Susceptibility of Clinical Language Models
Apr 16, 2021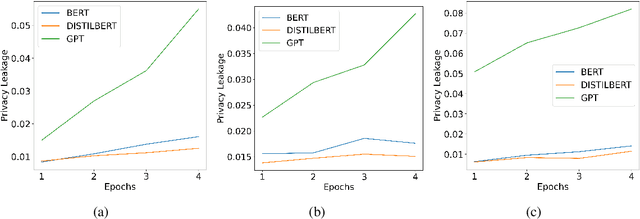
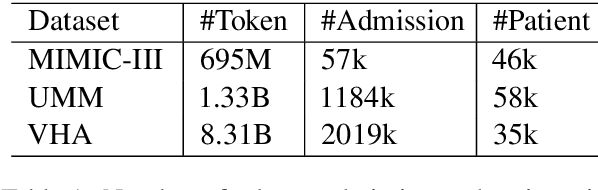
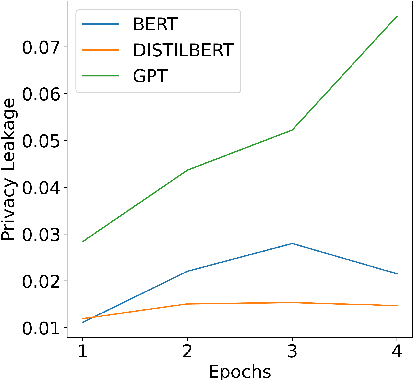

Deep Neural Network (DNN) models have been shown to have high empirical privacy leakages. Clinical language models (CLMs) trained on clinical data have been used to improve performance in biomedical natural language processing tasks. In this work, we investigate the risks of training-data leakage through white-box or black-box access to CLMs. We design and employ membership inference attacks to estimate the empirical privacy leaks for model architectures like BERT and GPT2. We show that membership inference attacks on CLMs lead to non-trivial privacy leakages of up to 7%. Our results show that smaller models have lower empirical privacy leakages than larger ones, and masked LMs have lower leakages than auto-regressive LMs. We further show that differentially private CLMs can have improved model utility on clinical domain while ensuring low empirical privacy leakage. Lastly, we also study the effects of group-level membership inference and disease rarity on CLM privacy leakages.
Conversational Machine Comprehension: a Literature Review
Jun 01, 2020
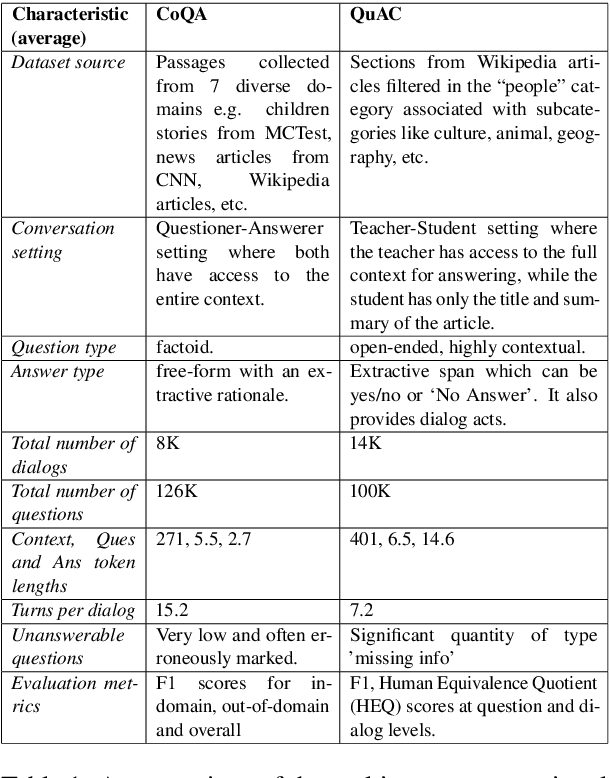

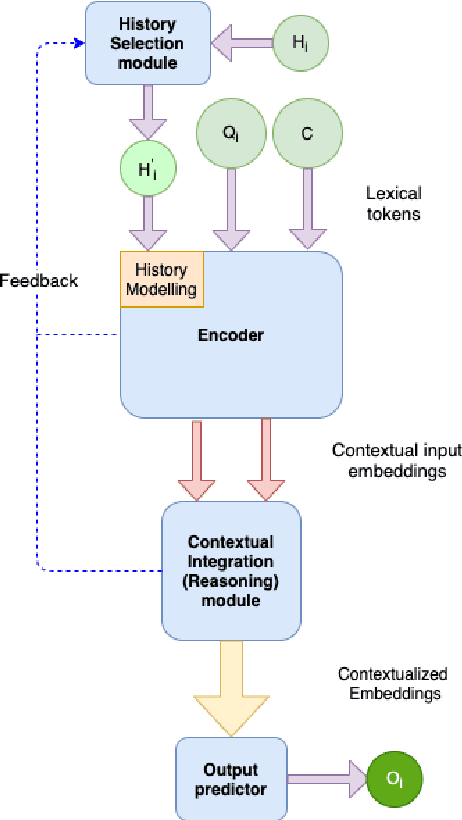
Conversational Machine Comprehension (CMC) is a research track in conversational AI which expects the machine to understand an open-domain text and thereafter engage in a multi-turn conversation to answer questions related to the text. While most of the research in Machine Reading Comprehension (MRC) revolves around single-turn question answering, multi-turn CMC has recently gained prominence, thanks to the advancement in natural language understanding via neural language models like BERT and the introduction of large-scale conversational datasets like CoQA and QuAC. The rise in interest has, however, led to a flurry of concurrent publications, each with a different yet structurally similar modeling approach and an inconsistent view of the surrounding literature. With the volume of model submissions to conversational datasets increasing every year, there exists a need to consolidate the scattered knowledge in this domain to streamline future research. This literature review, therefore, is a first-of-its-kind attempt at providing a holistic overview of CMC, with an emphasis on the common trends across recently published models, specifically in their approach to tackling conversational history. It focuses on synthesizing a generic framework for CMC models, rather than describing the models individually. The review is intended to serve as a compendium for future researchers in this domain.
Entity-Enriched Neural Models for Clinical Question Answering
May 13, 2020
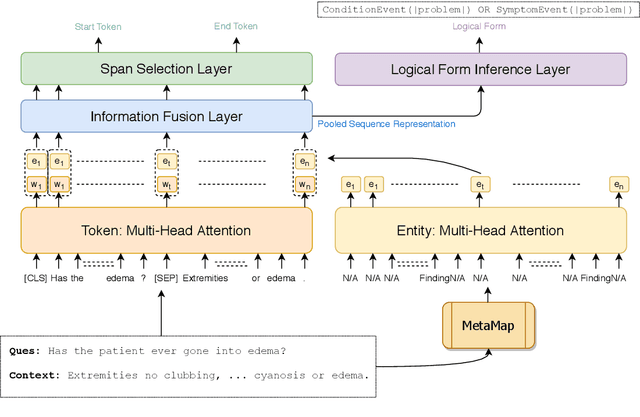

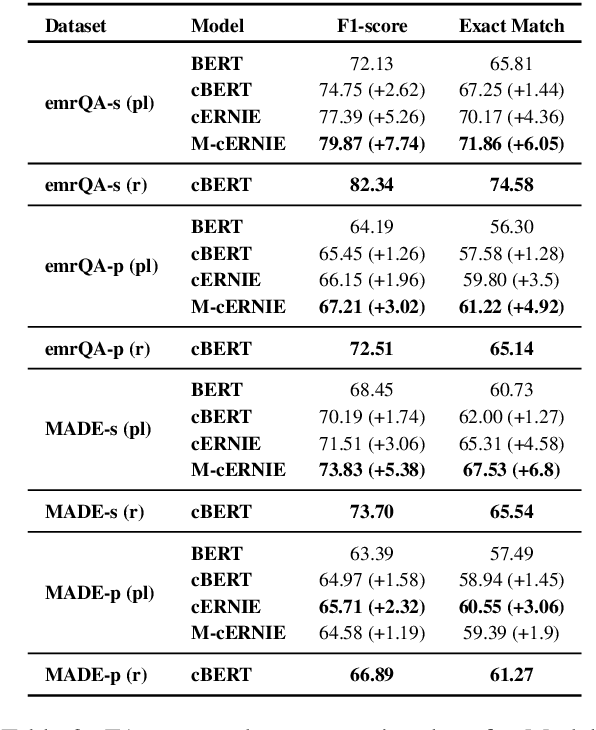
We explore state-of-the-art neural models for question answering on electronic medical records and improve their ability to generalize better on previously unseen (paraphrased) questions at test time. We enable this by learning to predict logical forms as an auxiliary task along with the main task of answer span detection. The predicted logical forms also serve as a rationale for the answer. Further, we also incorporate medical entity information in these models via the ERNIE architecture. We train our models on the large-scale emrQA dataset and observe that our multi-task entity-enriched models generalize to paraphrased questions ~5% better than the baseline BERT model.
Improved Pretraining for Domain-specific Contextual Embedding Models
Apr 05, 2020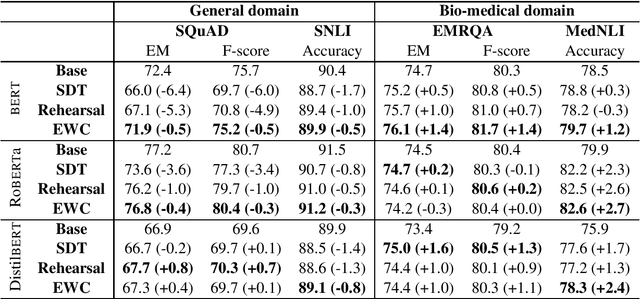
We investigate methods to mitigate catastrophic forgetting during domain-specific pretraining of contextual embedding models such as BERT, DistilBERT, and RoBERTa. Recently proposed domain-specific models such as BioBERT, SciBERT and ClinicalBERT are constructed by continuing the pretraining phase on a domain-specific text corpus. Such pretraining is susceptible to catastrophic forgetting, where the model forgets some of the information learned in the general domain. We propose the use of two continual learning techniques (rehearsal and elastic weight consolidation) to improve domain-specific training. Our results show that models trained by our proposed approaches can better maintain their performance on the general domain tasks, and at the same time, outperform domain-specific baseline models on downstream domain tasks.
Group Affect Prediction Using Multimodal Distributions
Mar 12, 2018

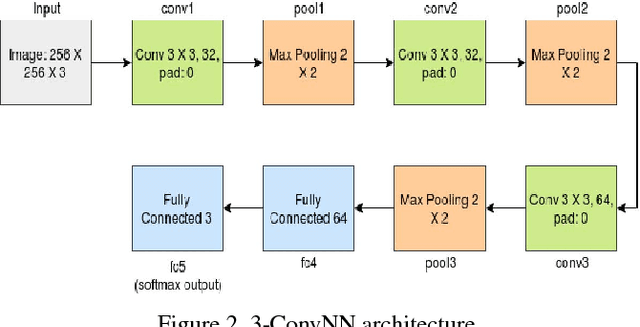
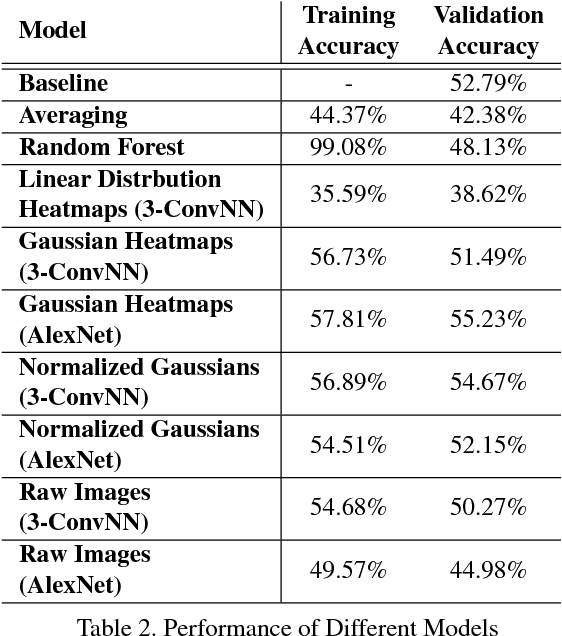
We describe our approach towards building an efficient predictive model to detect emotions for a group of people in an image. We have proposed that training a Convolutional Neural Network (CNN) model on the emotion heatmaps extracted from the image, outperforms a CNN model trained entirely on the raw images. The comparison of the models have been done on a recently published dataset of Emotion Recognition in the Wild (EmotiW) challenge, 2017. The proposed method achieved validation accuracy of 55.23% which is 2.44% above the baseline accuracy, provided by the EmotiW organizers.
Can Evolutionary Sampling Improve Bagged Ensembles?
Oct 03, 2016
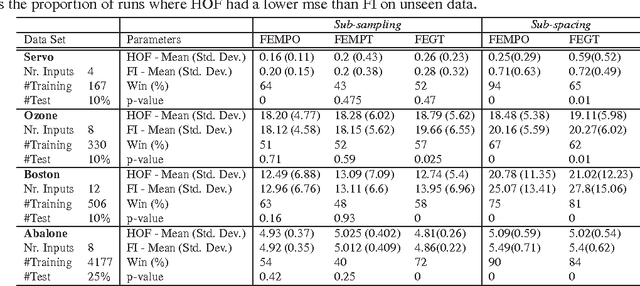
Perturb and Combine (P&C) group of methods generate multiple versions of the predictor by perturbing the training set or construction and then combining them into a single predictor (Breiman, 1996b). The motive is to improve the accuracy in unstable classification and regression methods. One of the most well known method in this group is Bagging. Arcing or Adaptive Resampling and Combining methods like AdaBoost are smarter variants of P&C methods. In this extended abstract, we lay the groundwork for a new family of methods under the P&C umbrella, known as Evolutionary Sampling (ES). We employ Evolutionary algorithms to suggest smarter sampling in both the feature space (sub-spaces) as well as training samples. We discuss multiple fitness functions to assess ensembles and empirically compare our performance against randomized sampling of training data and feature sub-spaces.