 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthEHR-Eviction: Enhancing Eviction SDoH Detection with LLM-Augmented Synthetic EHR Data
Jul 10, 2025Eviction is a significant yet understudied social determinants of health (SDoH), linked to housing instability, unemployment, and mental health. While eviction appears in unstructured electronic health records (EHRs), it is rarely coded in structured fields, limiting downstream applications. We introduce SynthEHR-Eviction, a scalable pipeline combining LLMs, human-in-the-loop annotation, and automated prompt optimization (APO) to extract eviction statuses from clinical notes. Using this pipeline, we created the largest public eviction-related SDoH dataset to date, comprising 14 fine-grained categories. Fine-tuned LLMs (e.g., Qwen2.5, LLaMA3) trained on SynthEHR-Eviction achieved Macro-F1 scores of 88.8% (eviction) and 90.3% (other SDoH) on human validated data, outperforming GPT-4o-APO (87.8%, 87.3%), GPT-4o-mini-APO (69.1%, 78.1%), and BioBERT (60.7%, 68.3%), while enabling cost-effective deployment across various model sizes. The pipeline reduces annotation effort by over 80%, accelerates dataset creation, enables scalable eviction detection, and generalizes to other information extraction tasks.
Synth-SBDH: A Synthetic Dataset of Social and Behavioral Determinants of Health for Clinical Text
Jun 10, 2024



Social and behavioral determinants of health (SBDH) play a crucial role in health outcomes and are frequently documented in clinical text. Automatically extracting SBDH information from clinical text relies on publicly available good-quality datasets. However, existing SBDH datasets exhibit substantial limitations in their availability and coverage. In this study, we introduce Synth-SBDH, a novel synthetic dataset with detailed SBDH annotations, encompassing status, temporal information, and rationale across 15 SBDH categories. We showcase the utility of Synth-SBDH on three tasks using real-world clinical datasets from two distinct hospital settings, highlighting its versatility, generalizability, and distillation capabilities. Models trained on Synth-SBDH consistently outperform counterparts with no Synth-SBDH training, achieving up to 62.5% macro-F improvements. Additionally, Synth-SBDH proves effective for rare SBDH categories and under-resource constraints. Human evaluation demonstrates a Human-LLM alignment of 71.06% and uncovers areas for future refinements.
UMass-BioNLP at MEDIQA-M3G 2024: DermPrompt -- A Systematic Exploration of Prompt Engineering with GPT-4V for Dermatological Diagnosis
Apr 27, 2024



This paper presents our team's participation in the MEDIQA-ClinicalNLP2024 shared task B. We present a novel approach to diagnosing clinical dermatology cases by integrating large multimodal models, specifically leveraging the capabilities of GPT-4V under a retriever and a re-ranker framework. Our investigation reveals that GPT-4V, when used as a retrieval agent, can accurately retrieve the correct skin condition 85% of the time using dermatological images and brief patient histories. Additionally, we empirically show that Naive Chain-of-Thought (CoT) works well for retrieval while Medical Guidelines Grounded CoT is required for accurate dermatological diagnosis. Further, we introduce a Multi-Agent Conversation (MAC) framework and show its superior performance and potential over the best CoT strategy. The experiments suggest that using naive CoT for retrieval and multi-agent conversation for critique-based diagnosis, GPT-4V can lead to an early and accurate diagnosis of dermatological conditions. The implications of this work extend to improving diagnostic workflows, supporting dermatological education, and enhancing patient care by providing a scalable, accessible, and accurate diagnostic tool.
ClinicalMamba: A Generative Clinical Language Model on Longitudinal Clinical Notes
Mar 09, 2024



The advancement of natural language processing (NLP) systems in healthcare hinges on language model ability to interpret the intricate information contained within clinical notes. This process often requires integrating information from various time points in a patient's medical history. However, most earlier clinical language models were pretrained with a context length limited to roughly one clinical document. In this study, We introduce ClinicalMamba, a specialized version of the Mamba language model, pretrained on a vast corpus of longitudinal clinical notes to address the unique linguistic characteristics and information processing needs of the medical domain. ClinicalMamba, with 130 million and 2.8 billion parameters, demonstrates a superior performance in modeling clinical language across extended text lengths compared to Mamba and clinical Llama. With few-shot learning, ClinicalMamba achieves notable benchmarks in speed and accuracy, outperforming existing clinical language models and general domain large models like GPT-4 in longitudinal clinical notes information extraction tasks.
UMASS_BioNLP at MEDIQA-Chat 2023: Can LLMs generate high-quality synthetic note-oriented doctor-patient conversations?
Jun 29, 2023This paper presents UMASS_BioNLP team participation in the MEDIQA-Chat 2023 shared task for Task-A and Task-C. We focus especially on Task-C and propose a novel LLMs cooperation system named a doctor-patient loop to generate high-quality conversation data sets. The experiment results demonstrate that our approaches yield reasonable performance as evaluated by automatic metrics such as ROUGE, medical concept recall, BLEU, and Self-BLEU. Furthermore, we conducted a comparative analysis between our proposed method and ChatGPT and GPT-4. This analysis also investigates the potential of utilizing cooperation LLMs to generate high-quality datasets.
Associations Between Natural Language Processing (NLP) Enriched Social Determinants of Health and Suicide Death among US Veterans
Dec 14, 2022


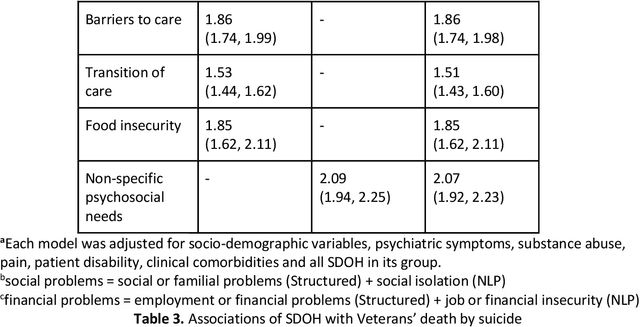
Importance: Social determinants of health (SDOH) are known to be associated with increased risk of suicidal behaviors, but few studies utilized SDOH from unstructured electronic health record (EHR) notes. Objective: To investigate associations between suicide and recent SDOH, identified using structured and unstructured data. Design: Nested case-control study. Setting: EHR data from the US Veterans Health Administration (VHA). Participants: 6,122,785 Veterans who received care in the US VHA between October 1, 2010, and September 30, 2015. Exposures: Occurrence of SDOH over a maximum span of two years compared with no occurrence of SDOH. Main Outcomes and Measures: Cases of suicide deaths were matched with 4 controls on birth year, cohort entry date, sex, and duration of follow-up. We developed an NLP system to extract SDOH from unstructured notes. Structured data, NLP on unstructured data, and combining them yielded seven, eight and nine SDOH respectively. Adjusted odds ratios (aORs) and 95% confidence intervals (CIs) were estimated using conditional logistic regression. Results: In our cohort, 8,821 Veterans committed suicide during 23,725,382 person-years of follow-up (incidence rate 37.18 /100,000 person-years). Our cohort was mostly male (92.23%) and white (76.99%). Across the six common SDOH as covariates, NLP-extracted SDOH, on average, covered 84.38% of all SDOH occurrences. All SDOH, measured by structured data and NLP, were significantly associated with increased risk of suicide. The SDOH with the largest effects was legal problems (aOR=2.67, 95% CI=2.46-2.89), followed by violence (aOR=2.26, 95% CI=2.11-2.43). NLP-extracted and structured SDOH were also associated with suicide. Conclusions and Relevance: NLP-extracted SDOH were always significantly associated with increased risk of suicide among Veterans, suggesting the potential of NLP in public health studies.
Knowledge Injected Prompt Based Fine-tuning for Multi-label Few-shot ICD Coding
Oct 07, 2022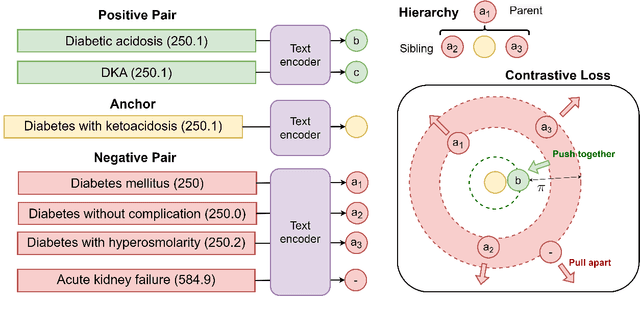
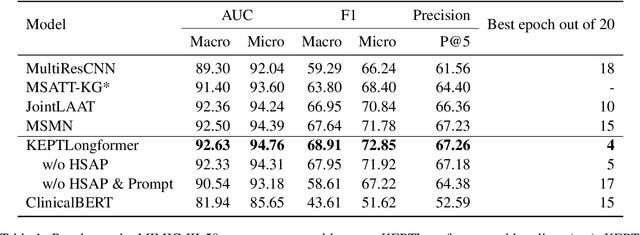
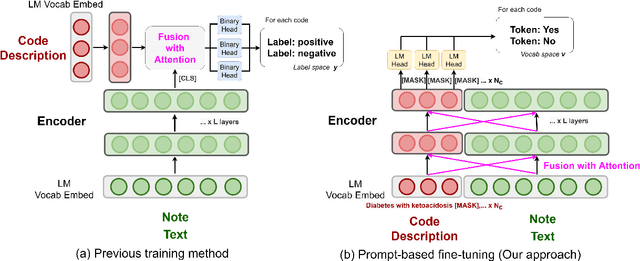
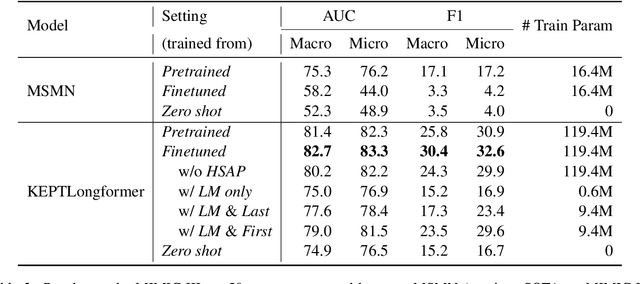
Automatic International Classification of Diseases (ICD) coding aims to assign multiple ICD codes to a medical note with average length of 3,000+ tokens. This task is challenging due to a high-dimensional space of multi-label assignment (tens of thousands of ICD codes) and the long-tail challenge: only a few codes (common diseases) are frequently assigned while most codes (rare diseases) are infrequently assigned. This study addresses the long-tail challenge by adapting a prompt-based fine-tuning technique with label semantics, which has been shown to be effective under few-shot setting. To further enhance the performance in medical domain, we propose a knowledge-enhanced longformer by injecting three domain-specific knowledge: hierarchy, synonym, and abbreviation with additional pretraining using contrastive learning. Experiments on MIMIC-III-full, a benchmark dataset of code assignment, show that our proposed method outperforms previous state-of-the-art method in 14.5% in marco F1 (from 10.3 to 11.8, P<0.001). To further test our model on few-shot setting, we created a new rare diseases coding dataset, MIMIC-III-rare50, on which our model improves marco F1 from 17.1 to 30.4 and micro F1 from 17.2 to 32.6 compared to previous method.
Sepsis Prediction and Vital Signs Ranking in Intensive Care Unit Patients
Dec 19, 2018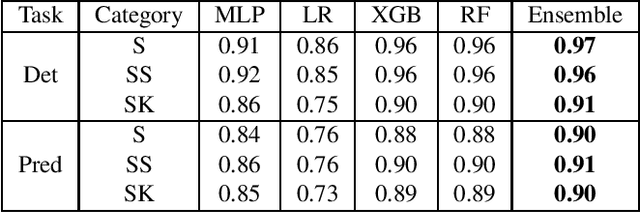

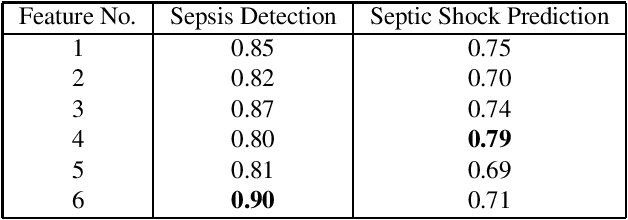
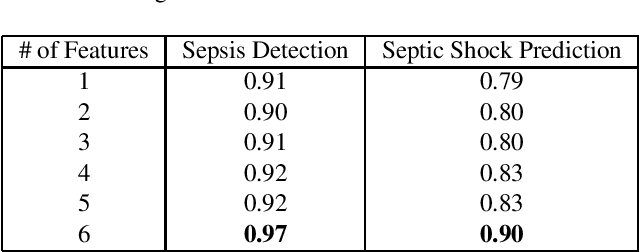
We study multiple rule-based and machine learning (ML) models for sepsis detection. We report the first neural network detection and prediction results on three categories of sepsis. We have used the retrospective Medical Information Mart for Intensive Care (MIMIC)-III dataset, restricted to intensive care unit (ICU) patients. Features for prediction were created from only common vital sign measurements. We show significant improvement of AUC score using neural network based ensemble model compared to single ML and rule-based models. For the detection of sepsis, severe sepsis, and septic shock, our model achieves an AUC of 0.94, 0.91 and 0.89, respectively. Four hours before the onset, it predicts the same three categories with an AUC of 0.80, 0.81 and 0.84 respectively. Further, we ranked the features and found that using six vital signs consistently provides higher detection and prediction AUC for all the models tested. Our novel ensemble model achieves highest AUC in detecting and predicting sepsis, severe sepsis, and septic shock in the MIMIC-III ICU patients, and is amenable to deployment in hospital settings.