 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSepsis Prediction and Vital Signs Ranking in Intensive Care Unit Patients
Dec 19, 2018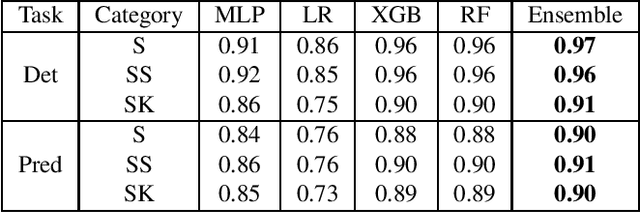

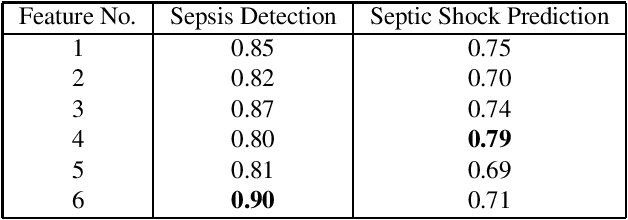
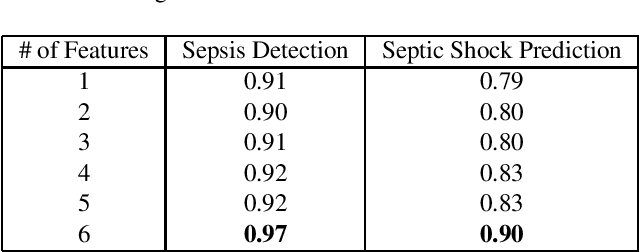
We study multiple rule-based and machine learning (ML) models for sepsis detection. We report the first neural network detection and prediction results on three categories of sepsis. We have used the retrospective Medical Information Mart for Intensive Care (MIMIC)-III dataset, restricted to intensive care unit (ICU) patients. Features for prediction were created from only common vital sign measurements. We show significant improvement of AUC score using neural network based ensemble model compared to single ML and rule-based models. For the detection of sepsis, severe sepsis, and septic shock, our model achieves an AUC of 0.94, 0.91 and 0.89, respectively. Four hours before the onset, it predicts the same three categories with an AUC of 0.80, 0.81 and 0.84 respectively. Further, we ranked the features and found that using six vital signs consistently provides higher detection and prediction AUC for all the models tested. Our novel ensemble model achieves highest AUC in detecting and predicting sepsis, severe sepsis, and septic shock in the MIMIC-III ICU patients, and is amenable to deployment in hospital settings.
Pathology Extraction from Chest X-Ray Radiology Reports: A Performance Study
Dec 06, 2018



Extraction of relevant pathological terms from radiology reports is important for correct image label generation and disease population studies. In this letter, we compare the performance of some known application program interface (APIs) for the task of thoracic abnormality extraction from radiology reports. We explored several medical domain specific annotation tools like Medical Text Indexer(MTI) with Non-MEDLINE and Mesh On Demand(MOD) options and generic Natural Language Understanding (NLU) API provided by the IBM cloud. Our results show that although MTI and MOD are intended for extracting medical terms, their performance is worst compared to generic extraction API like IBM NLU. Finally, we trained a DNN-based Named Entity Recognition (NER) model to extract the key concept words from radiology reports. Our model outperforms the medical specific and generic API performance by a large margin. Our results demonstrate the inadequacy of generic APIs for pathology extraction task and establish the importance of domain specific model training for improved results. We hope that these results motivate the research community to release larger de-identified radiology reports corpus for building high accuracy machine learning models for the important task of pathology extraction.
Abnormality Detection and Localization in Chest X-Rays using Deep Convolutional Neural Networks
Sep 27, 2017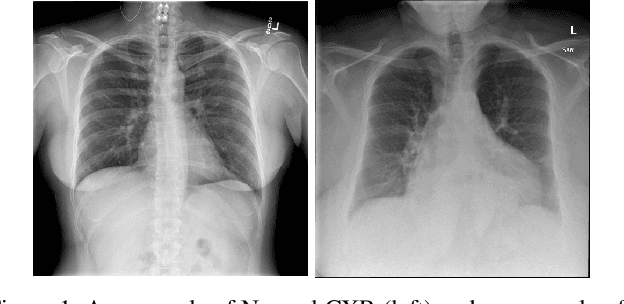
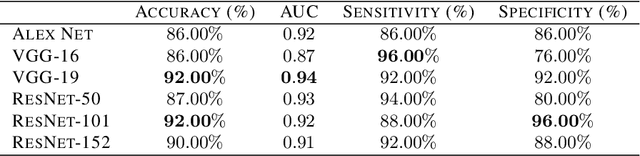
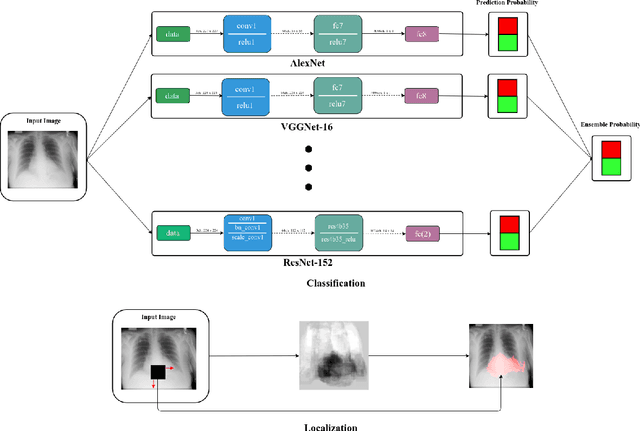
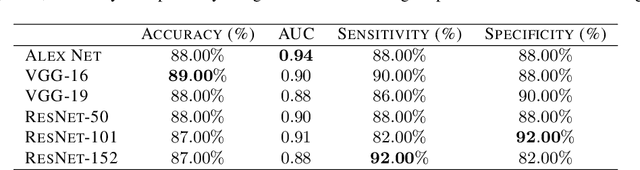
Chest X-Rays (CXRs) are widely used for diagnosing abnormalities in the heart and lung area. Automatically detecting these abnormalities with high accuracy could greatly enhance real world diagnosis processes. Lack of standard publicly available dataset and benchmark studies, however, makes it difficult to compare various detection methods. In order to overcome these difficulties, we have used a publicly available Indiana CXR, JSRT and Shenzhen dataset and studied the performance of known deep convolutional network (DCN) architectures on different abnormalities. We find that the same DCN architecture doesn't perform well across all abnormalities. Shallow features or earlier layers consistently provide higher detection accuracy compared to deep features. We have also found ensemble models to improve classification significantly compared to single model. Combining these insight, we report the highest accuracy on chest X-Ray abnormality detection on these datasets. We find that for cardiomegaly detection, the deep learning method improves the accuracy by a staggering 17 percentage point compared to rule based methods. We applied the techniques to the problem of tuberculosis detection on a different dataset and achieved the highest accuracy. Our localization experiments using these trained classifiers show that for spatially spread out abnormalities like cardiomegaly and pulmonary edema, the network can localize the abnormalities successfully most of the time. One remarkable result of the cardiomegaly localization is that the heart and its surrounding region is most responsible for cardiomegaly detection, in contrast to the rule based models where the ratio of heart and lung area is used as the measure. We believe that through deep learning based classification and localization, we will discover many more interesting features in medical image diagnosis that are not considered traditionally.
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Nov 04, 2016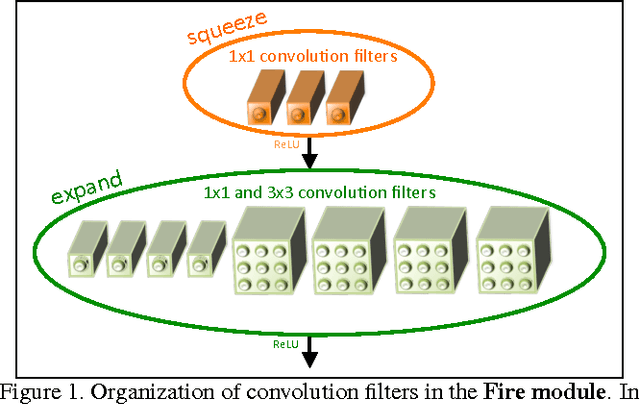
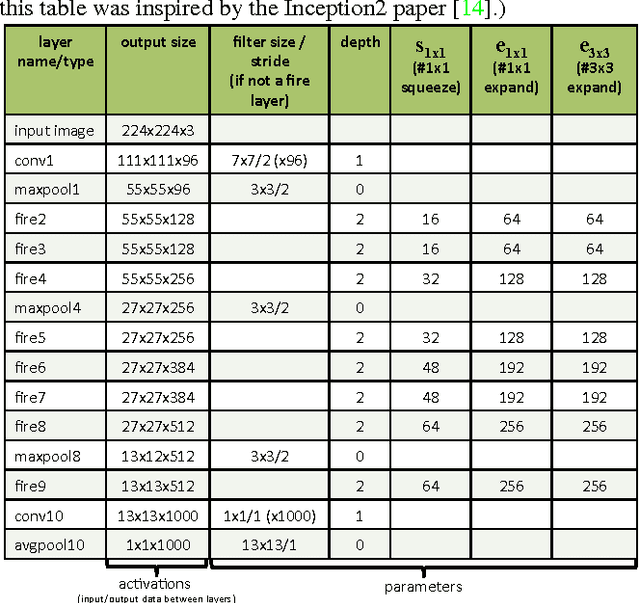
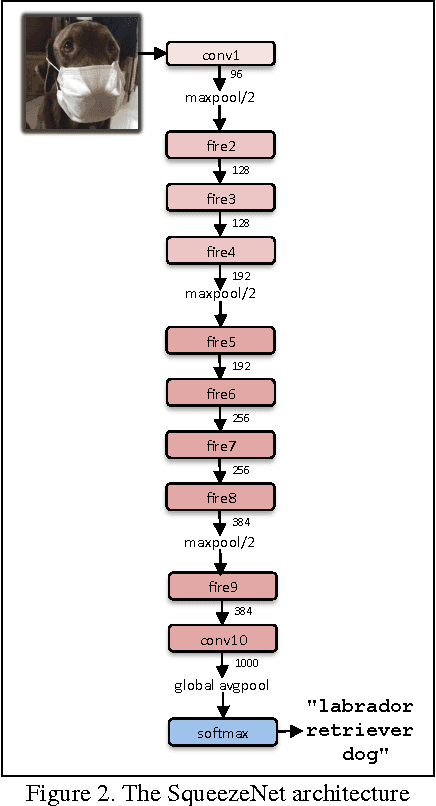
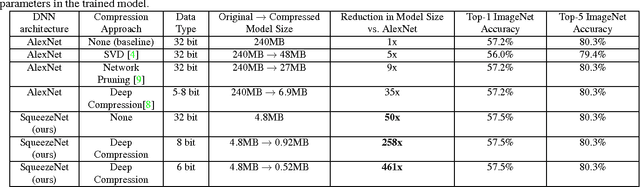
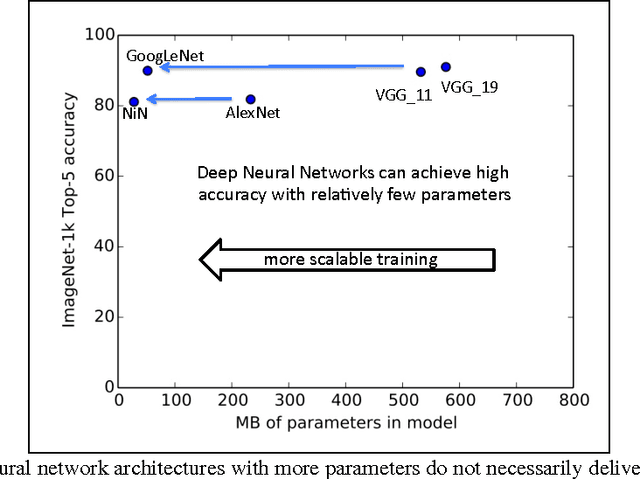
Recent research on deep neural networks has focused primarily on improving accuracy. For a given accuracy level, it is typically possible to identify multiple DNN architectures that achieve that accuracy level. With equivalent accuracy, smaller DNN architectures offer at least three advantages: (1) Smaller DNNs require less communication across servers during distributed training. (2) Smaller DNNs require less bandwidth to export a new model from the cloud to an autonomous car. (3) Smaller DNNs are more feasible to deploy on FPGAs and other hardware with limited memory. To provide all of these advantages, we propose a small DNN architecture called SqueezeNet. SqueezeNet achieves AlexNet-level accuracy on ImageNet with 50x fewer parameters. Additionally, with model compression techniques we are able to compress SqueezeNet to less than 0.5MB (510x smaller than AlexNet). The SqueezeNet architecture is available for download here: https://github.com/DeepScale/SqueezeNet
Shallow Networks for High-Accuracy Road Object-Detection
Jun 05, 2016

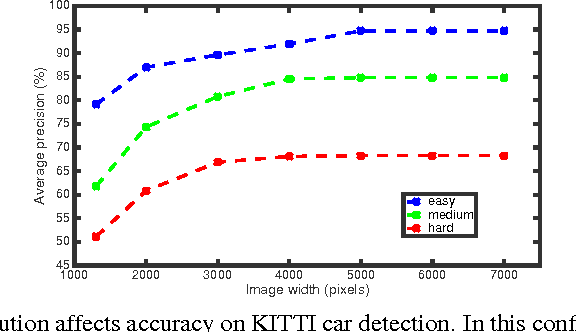

The ability to automatically detect other vehicles on the road is vital to the safety of partially-autonomous and fully-autonomous vehicles. Most of the high-accuracy techniques for this task are based on R-CNN or one of its faster variants. In the research community, much emphasis has been applied to using 3D vision or complex R-CNN variants to achieve higher accuracy. However, are there more straightforward modifications that could deliver higher accuracy? Yes. We show that increasing input image resolution (i.e. upsampling) offers up to 12 percentage-points higher accuracy compared to an off-the-shelf baseline. We also find situations where earlier/shallower layers of CNN provide higher accuracy than later/deeper layers. We further show that shallow models and upsampled images yield competitive accuracy. Our findings contrast with the current trend towards deeper and larger models to achieve high accuracy in domain specific detection tasks.
FireCaffe: near-linear acceleration of deep neural network training on compute clusters
Jan 08, 2016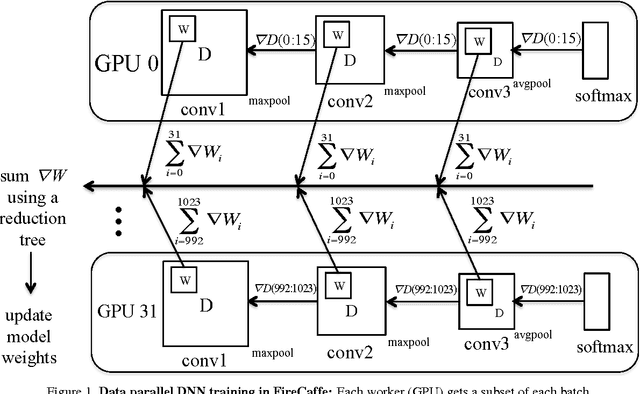


Long training times for high-accuracy deep neural networks (DNNs) impede research into new DNN architectures and slow the development of high-accuracy DNNs. In this paper we present FireCaffe, which successfully scales deep neural network training across a cluster of GPUs. We also present a number of best practices to aid in comparing advancements in methods for scaling and accelerating the training of deep neural networks. The speed and scalability of distributed algorithms is almost always limited by the overhead of communicating between servers; DNN training is not an exception to this rule. Therefore, the key consideration here is to reduce communication overhead wherever possible, while not degrading the accuracy of the DNN models that we train. Our approach has three key pillars. First, we select network hardware that achieves high bandwidth between GPU servers -- Infiniband or Cray interconnects are ideal for this. Second, we consider a number of communication algorithms, and we find that reduction trees are more efficient and scalable than the traditional parameter server approach. Third, we optionally increase the batch size to reduce the total quantity of communication during DNN training, and we identify hyperparameters that allow us to reproduce the small-batch accuracy while training with large batch sizes. When training GoogLeNet and Network-in-Network on ImageNet, we achieve a 47x and 39x speedup, respectively, when training on a cluster of 128 GPUs.