 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Clipping and Magnitude-aware Differentiation for Improved Quantization-aware Training
Jun 13, 2022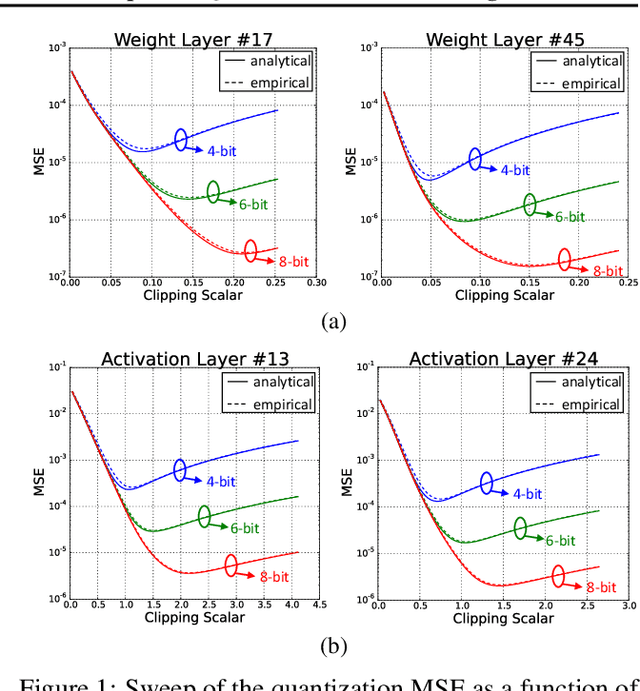

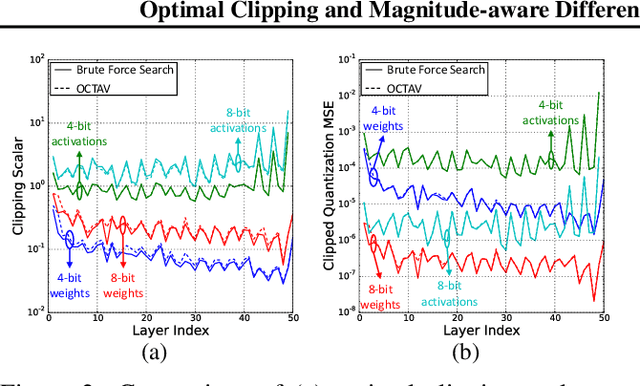
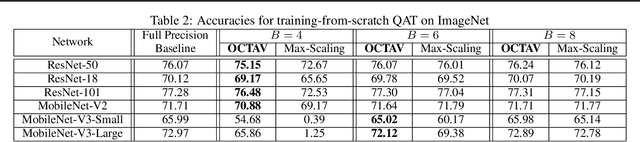
Data clipping is crucial in reducing noise in quantization operations and improving the achievable accuracy of quantization-aware training (QAT). Current practices rely on heuristics to set clipping threshold scalars and cannot be shown to be optimal. We propose Optimally Clipped Tensors And Vectors (OCTAV), a recursive algorithm to determine MSE-optimal clipping scalars. Derived from the fast Newton-Raphson method, OCTAV finds optimal clipping scalars on the fly, for every tensor, at every iteration of the QAT routine. Thus, the QAT algorithm is formulated with provably minimum quantization noise at each step. In addition, we reveal limitations in common gradient estimation techniques in QAT and propose magnitude-aware differentiation as a remedy to further improve accuracy. Experimentally, OCTAV-enabled QAT achieves state-of-the-art accuracy on multiple tasks. These include training-from-scratch and retraining ResNets and MobileNets on ImageNet, and Squad fine-tuning using BERT models, where OCTAV-enabled QAT consistently preserves accuracy at low precision (4-to-6-bits). Our results require no modifications to the baseline training recipe, except for the insertion of quantization operations where appropriate.
PatchNet -- Short-range Template Matching for Efficient Video Processing
Mar 10, 2021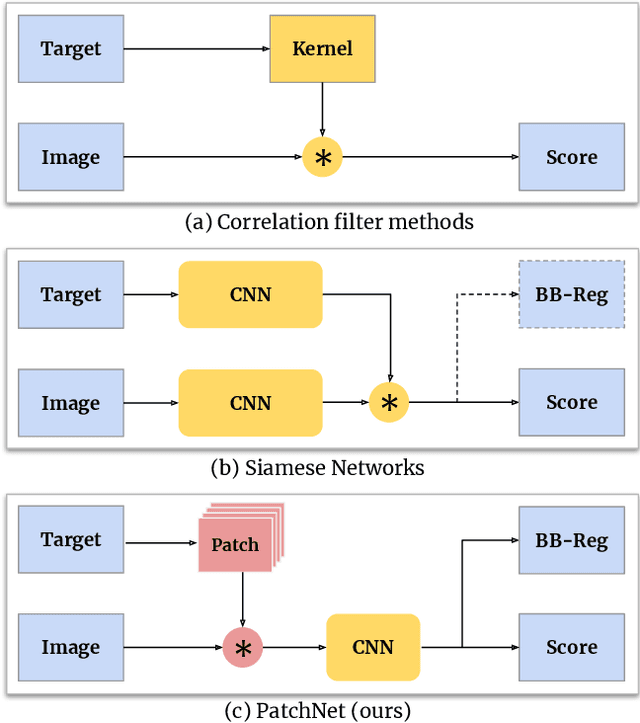
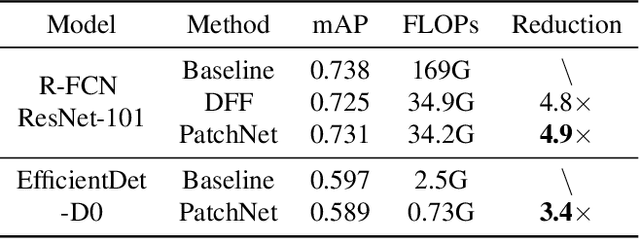

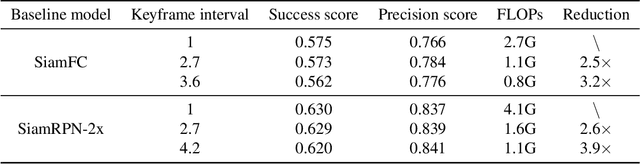
Object recognition is a fundamental problem in many video processing tasks, accurately locating seen objects at low computation cost paves the way for on-device video recognition. We propose PatchNet, an efficient convolutional neural network to match objects in adjacent video frames. It learns the patchwise correlation features instead of pixel features. PatchNet is very compact, running at just 58MFLOPs, $5\times$ simpler than MobileNetV2. We demonstrate its application on two tasks, video object detection and visual object tracking. On ImageNet VID, PatchNet reduces the flops of R-FCN ResNet-101 by 5x and EfficientDet-D0 by 3.4x with less than 1% mAP loss. On OTB2015, PatchNet reduces SiamFC and SiamRPN by 2.5x with no accuracy loss. Experiments on Jetson Nano further demonstrate 2.8x to 4.3x speed-ups associated with flops reduction. Code is open sourced at https://github.com/RalphMao/PatchNet.
VS-Quant: Per-vector Scaled Quantization for Accurate Low-Precision Neural Network Inference
Feb 08, 2021
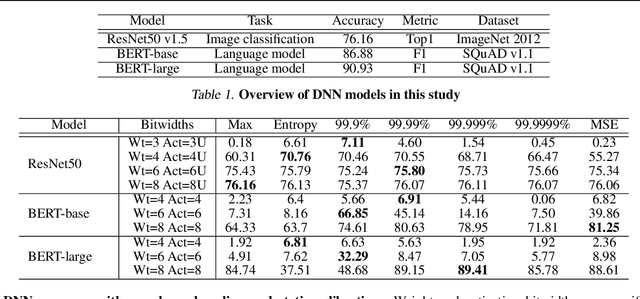
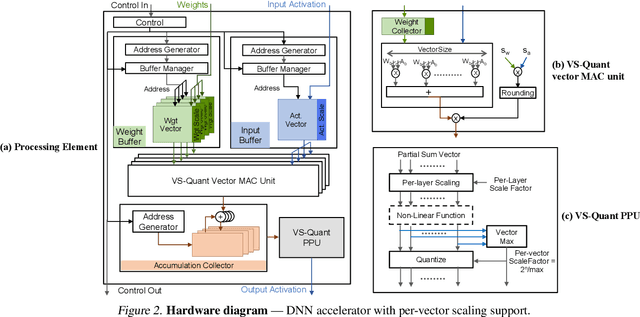
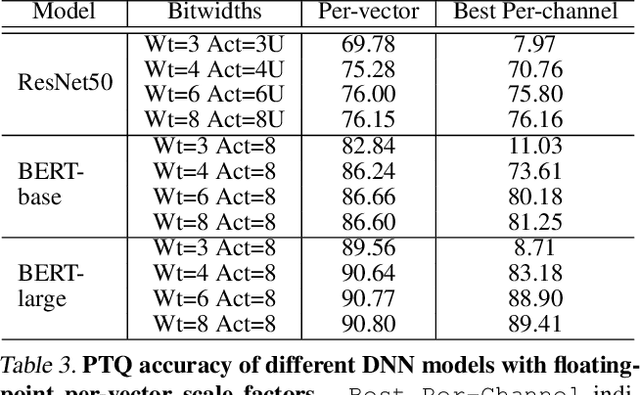
Quantization enables efficient acceleration of deep neural networks by reducing model memory footprint and exploiting low-cost integer math hardware units. Quantization maps floating-point weights and activations in a trained model to low-bitwidth integer values using scale factors. Excessive quantization, reducing precision too aggressively, results in accuracy degradation. When scale factors are shared at a coarse granularity across many dimensions of each tensor, effective precision of individual elements within the tensor are limited. To reduce quantization-related accuracy loss, we propose using a separate scale factor for each small vector of ($\approx$16-64) elements within a single dimension of a tensor. To achieve an efficient hardware implementation, the per-vector scale factors can be implemented with low-bitwidth integers when calibrated using a two-level quantization scheme. We find that per-vector scaling consistently achieves better inference accuracy at low precision compared to conventional scaling techniques for popular neural networks without requiring retraining. We also modify a deep learning accelerator hardware design to study the area and energy overheads of per-vector scaling support. Our evaluation demonstrates that per-vector scaled quantization with 4-bit weights and activations achieves 37% area saving and 24% energy saving while maintaining over 75% accuracy for ResNet50 on ImageNet. 4-bit weights and 8-bit activations achieve near-full-precision accuracy for both BERT-base and BERT-large on SQuAD while reducing area by 26% compared to an 8-bit baseline.
A Delay Metric for Video Object Detection: What Average Precision Fails to Tell
Aug 18, 2019



Average precision (AP) is a widely used metric to evaluate detection accuracy of image and video object detectors. In this paper, we analyze object detection from videos and point out that AP alone is not sufficient to capture the temporal nature of video object detection. To tackle this problem, we propose a comprehensive metric, average delay (AD), to measure and compare detection delay. To facilitate delay evaluation, we carefully select a subset of ImageNet VID, which we name as ImageNet VIDT with an emphasis on complex trajectories. By extensively evaluating a wide range of detectors on VIDT, we show that most methods drastically increase the detection delay but still preserve AP well. In other words, AP is not sensitive enough to reflect the temporal characteristics of a video object detector. Our results suggest that video object detection methods should be additionally evaluated with a delay metric, particularly for latency-critical applications such as autonomous vehicle perception.
CaTDet: Cascaded Tracked Detector for Efficient Object Detection from Video
Sep 30, 2018



Detecting objects in a video is a compute-intensive task. In this paper we propose CaTDet, a system to speedup object detection by leveraging the temporal correlation in video. CaTDet consists of two DNN models that form a cascaded detector, and an additional tracker to predict regions of interests based on historic detections. We also propose a new metric, mean Delay(mD), which is designed for latency-critical video applications. Experiments on the KITTI dataset show that CaTDet reduces operation count by 5.1-8.7x with the same mean Average Precision(mAP) as the single-model Faster R-CNN detector and incurs additional delay of 0.3 frame. On CityPersons dataset, CaTDet achieves 13.0x reduction in operations with 0.8% mAP loss.
Efficient Sparse-Winograd Convolutional Neural Networks
Feb 18, 2018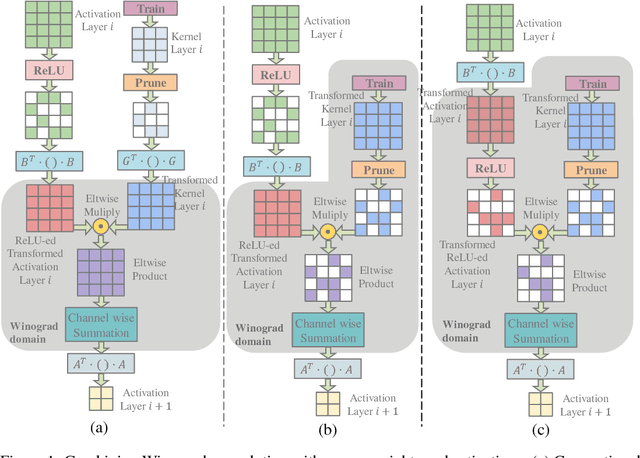
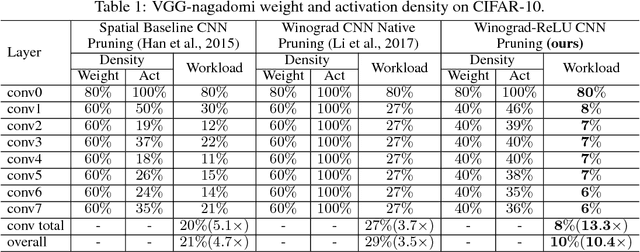
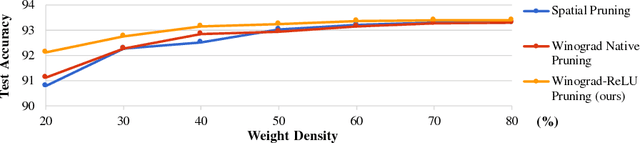
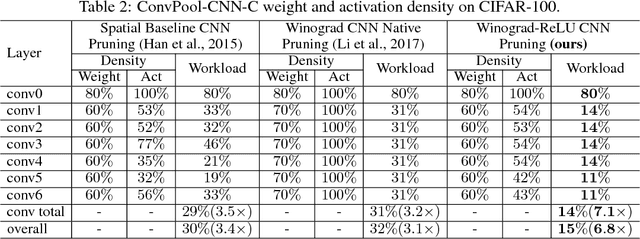
Convolutional Neural Networks (CNNs) are computationally intensive, which limits their application on mobile devices. Their energy is dominated by the number of multiplies needed to perform the convolutions. Winograd's minimal filtering algorithm (Lavin, 2015) and network pruning (Han et al., 2015) can reduce the operation count, but these two methods cannot be directly combined $-$ applying the Winograd transform fills in the sparsity in both the weights and the activations. We propose two modifications to Winograd-based CNNs to enable these methods to exploit sparsity. First, we move the ReLU operation into the Winograd domain to increase the sparsity of the transformed activations. Second, we prune the weights in the Winograd domain to exploit static weight sparsity. For models on CIFAR-10, CIFAR-100 and ImageNet datasets, our method reduces the number of multiplications by $10.4\times$, $6.8\times$ and $10.8\times$ respectively with loss of accuracy less than $0.1\%$, outperforming previous baselines by $2.0\times$-$3.0\times$. We also show that moving ReLU to the Winograd domain allows more aggressive pruning.
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
Feb 05, 2018
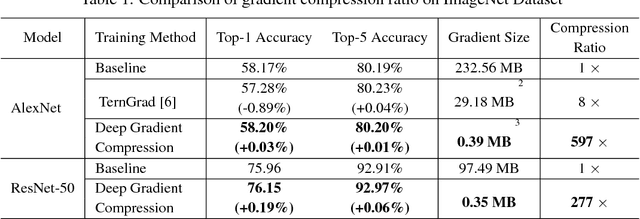

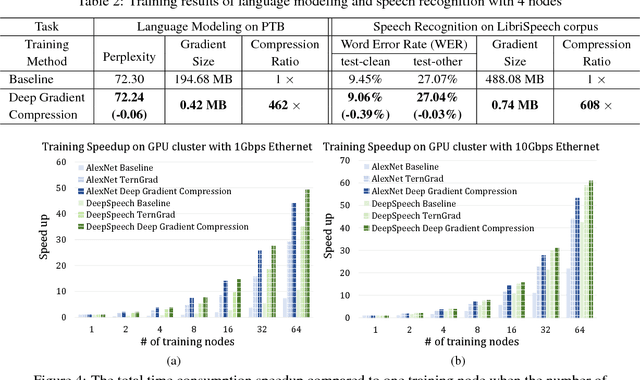
Large-scale distributed training requires significant communication bandwidth for gradient exchange that limits the scalability of multi-node training, and requires expensive high-bandwidth network infrastructure. The situation gets even worse with distributed training on mobile devices (federated learning), which suffers from higher latency, lower throughput, and intermittent poor connections. In this paper, we find 99.9% of the gradient exchange in distributed SGD is redundant, and propose Deep Gradient Compression (DGC) to greatly reduce the communication bandwidth. To preserve accuracy during compression, DGC employs four methods: momentum correction, local gradient clipping, momentum factor masking, and warm-up training. We have applied Deep Gradient Compression to image classification, speech recognition, and language modeling with multiple datasets including Cifar10, ImageNet, Penn Treebank, and Librispeech Corpus. On these scenarios, Deep Gradient Compression achieves a gradient compression ratio from 270x to 600x without losing accuracy, cutting the gradient size of ResNet-50 from 97MB to 0.35MB, and for DeepSpeech from 488MB to 0.74MB. Deep gradient compression enables large-scale distributed training on inexpensive commodity 1Gbps Ethernet and facilitates distributed training on mobile.
* we find 99.9% of the gradient exchange in distributed SGD is redundant; we reduce the communication bandwidth by two orders of magnitude without losing accuracy
Exploring the Regularity of Sparse Structure in Convolutional Neural Networks
Jun 05, 2017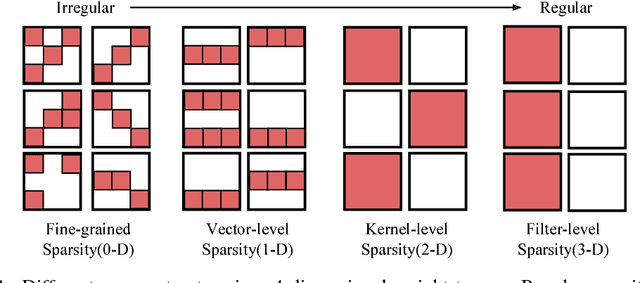
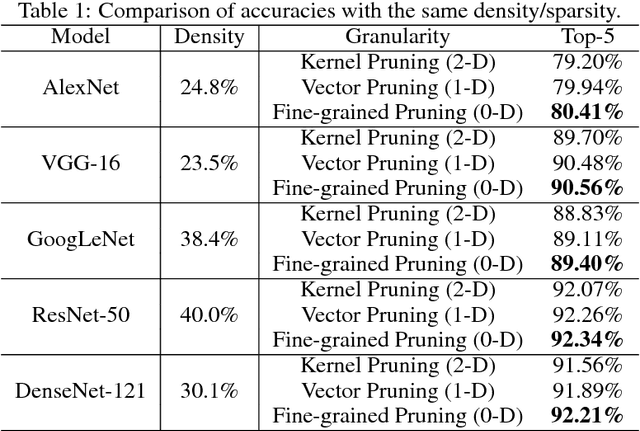
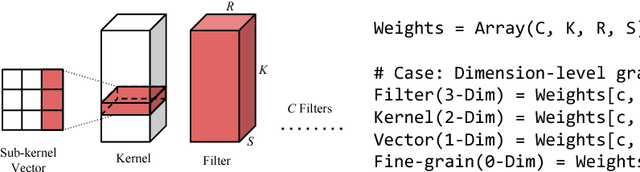
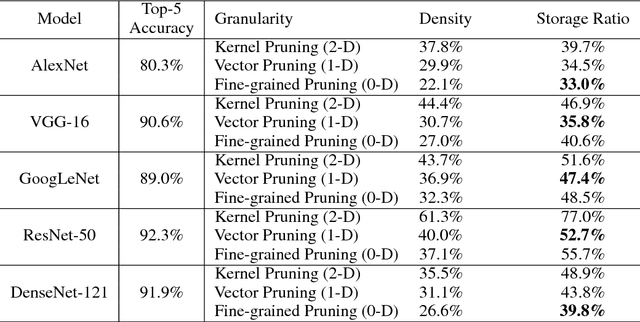
Sparsity helps reduce the computational complexity of deep neural networks by skipping zeros. Taking advantage of sparsity is listed as a high priority in next generation DNN accelerators such as TPU. The structure of sparsity, i.e., the granularity of pruning, affects the efficiency of hardware accelerator design as well as the prediction accuracy. Coarse-grained pruning creates regular sparsity patterns, making it more amenable for hardware acceleration but more challenging to maintain the same accuracy. In this paper we quantitatively measure the trade-off between sparsity regularity and prediction accuracy, providing insights in how to maintain accuracy while having more a more structured sparsity pattern. Our experimental results show that coarse-grained pruning can achieve a sparsity ratio similar to unstructured pruning without loss of accuracy. Moreover, due to the index saving effect, coarse-grained pruning is able to obtain a better compression ratio than fine-grained sparsity at the same accuracy threshold. Based on the recent sparse convolutional neural network accelerator (SCNN), our experiments further demonstrate that coarse-grained sparsity saves about 2x the memory references compared to fine-grained sparsity. Since memory reference is more than two orders of magnitude more expensive than arithmetic operations, the regularity of sparse structure leads to more efficient hardware design.
SCNN: An Accelerator for Compressed-sparse Convolutional Neural Networks
May 23, 2017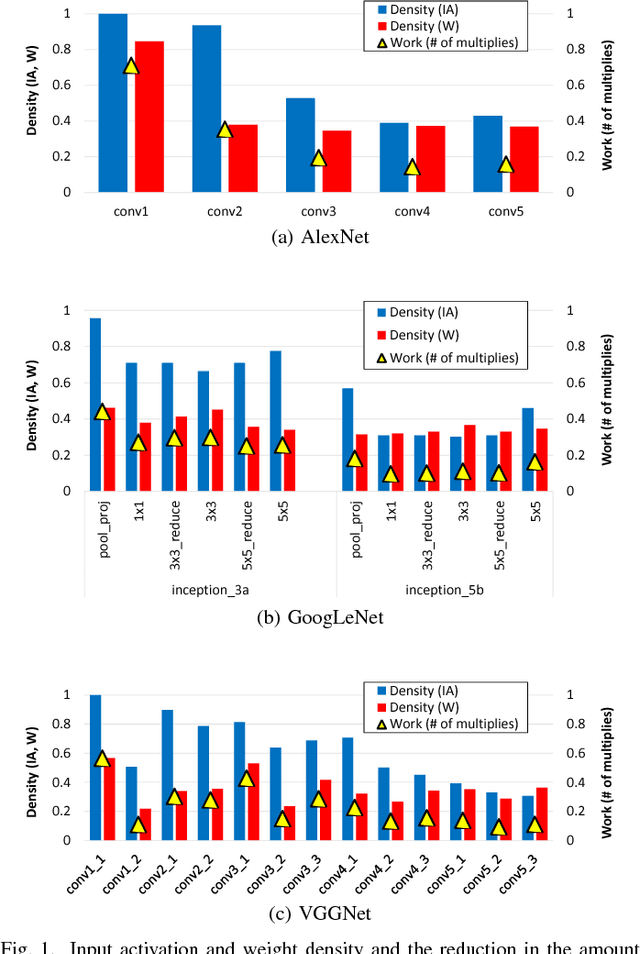
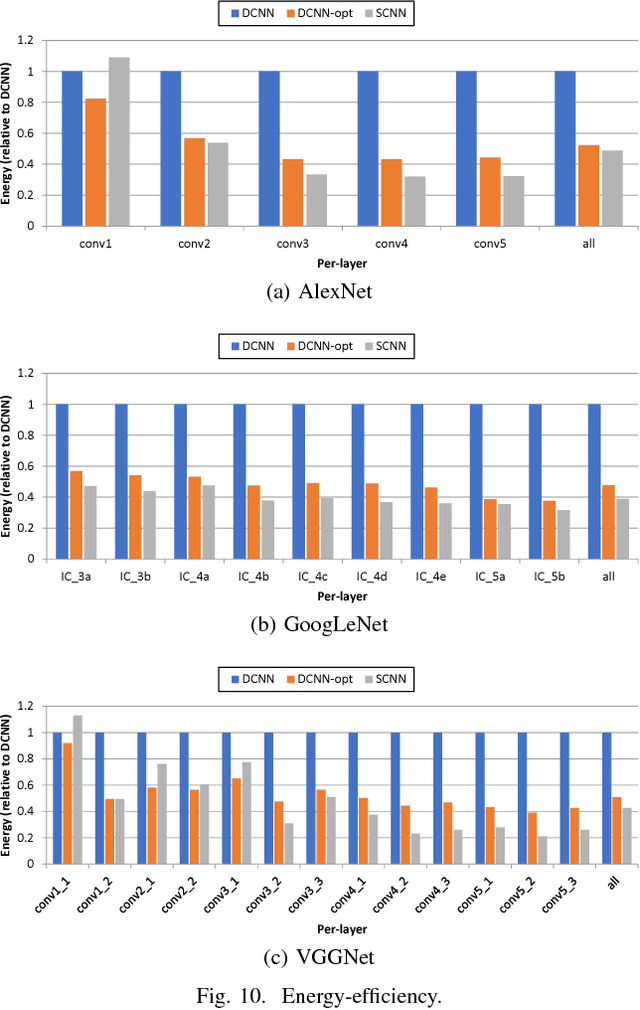
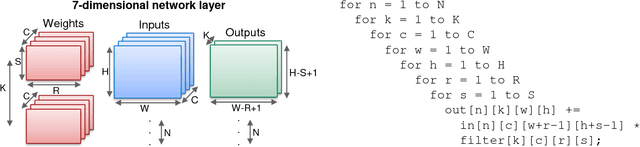

Convolutional Neural Networks (CNNs) have emerged as a fundamental technology for machine learning. High performance and extreme energy efficiency are critical for deployments of CNNs in a wide range of situations, especially mobile platforms such as autonomous vehicles, cameras, and electronic personal assistants. This paper introduces the Sparse CNN (SCNN) accelerator architecture, which improves performance and energy efficiency by exploiting the zero-valued weights that stem from network pruning during training and zero-valued activations that arise from the common ReLU operator applied during inference. Specifically, SCNN employs a novel dataflow that enables maintaining the sparse weights and activations in a compressed encoding, which eliminates unnecessary data transfers and reduces storage requirements. Furthermore, the SCNN dataflow facilitates efficient delivery of those weights and activations to the multiplier array, where they are extensively reused. In addition, the accumulation of multiplication products are performed in a novel accumulator array. Our results show that on contemporary neural networks, SCNN can improve both performance and energy by a factor of 2.7x and 2.3x, respectively, over a comparably provisioned dense CNN accelerator.
Trained Ternary Quantization
Feb 23, 2017


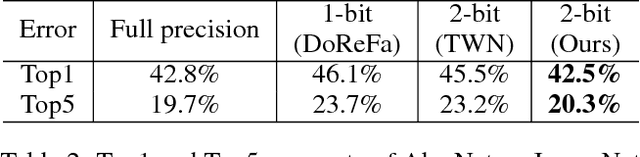
Deep neural networks are widely used in machine learning applications. However, the deployment of large neural networks models can be difficult to deploy on mobile devices with limited power budgets. To solve this problem, we propose Trained Ternary Quantization (TTQ), a method that can reduce the precision of weights in neural networks to ternary values. This method has very little accuracy degradation and can even improve the accuracy of some models (32, 44, 56-layer ResNet) on CIFAR-10 and AlexNet on ImageNet. And our AlexNet model is trained from scratch, which means it's as easy as to train normal full precision model. We highlight our trained quantization method that can learn both ternary values and ternary assignment. During inference, only ternary values (2-bit weights) and scaling factors are needed, therefore our models are nearly 16x smaller than full-precision models. Our ternary models can also be viewed as sparse binary weight networks, which can potentially be accelerated with custom circuit. Experiments on CIFAR-10 show that the ternary models obtained by trained quantization method outperform full-precision models of ResNet-32,44,56 by 0.04%, 0.16%, 0.36%, respectively. On ImageNet, our model outperforms full-precision AlexNet model by 0.3% of Top-1 accuracy and outperforms previous ternary models by 3%.