 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Clipping and Magnitude-aware Differentiation for Improved Quantization-aware Training
Jun 13, 2022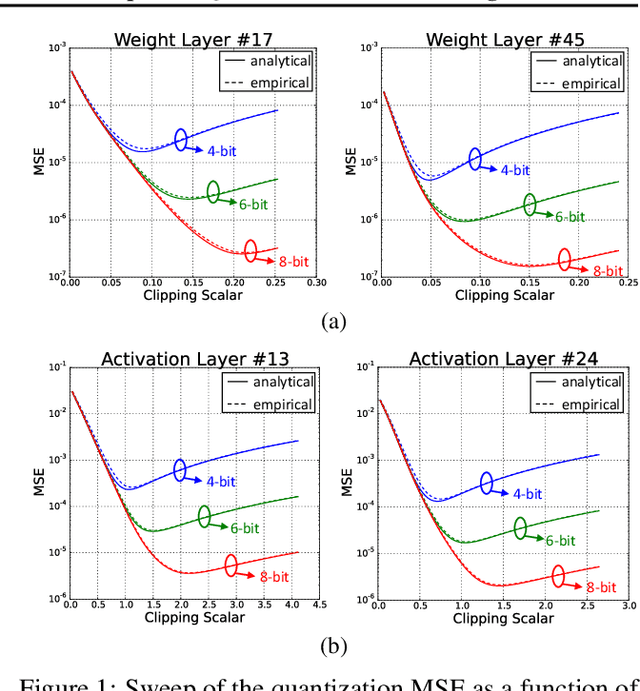

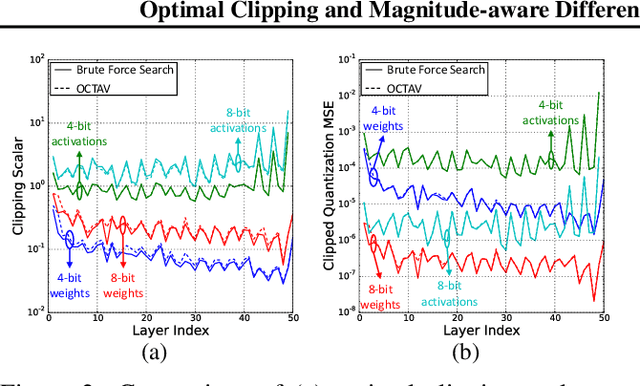
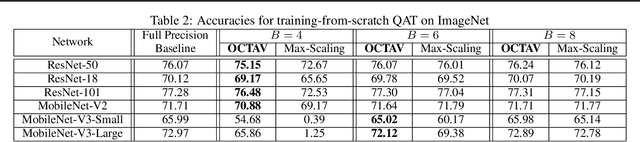
Data clipping is crucial in reducing noise in quantization operations and improving the achievable accuracy of quantization-aware training (QAT). Current practices rely on heuristics to set clipping threshold scalars and cannot be shown to be optimal. We propose Optimally Clipped Tensors And Vectors (OCTAV), a recursive algorithm to determine MSE-optimal clipping scalars. Derived from the fast Newton-Raphson method, OCTAV finds optimal clipping scalars on the fly, for every tensor, at every iteration of the QAT routine. Thus, the QAT algorithm is formulated with provably minimum quantization noise at each step. In addition, we reveal limitations in common gradient estimation techniques in QAT and propose magnitude-aware differentiation as a remedy to further improve accuracy. Experimentally, OCTAV-enabled QAT achieves state-of-the-art accuracy on multiple tasks. These include training-from-scratch and retraining ResNets and MobileNets on ImageNet, and Squad fine-tuning using BERT models, where OCTAV-enabled QAT consistently preserves accuracy at low precision (4-to-6-bits). Our results require no modifications to the baseline training recipe, except for the insertion of quantization operations where appropriate.
VS-Quant: Per-vector Scaled Quantization for Accurate Low-Precision Neural Network Inference
Feb 08, 2021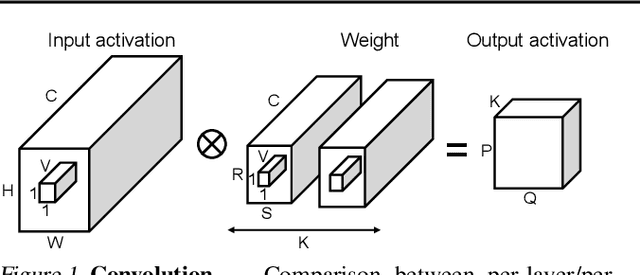
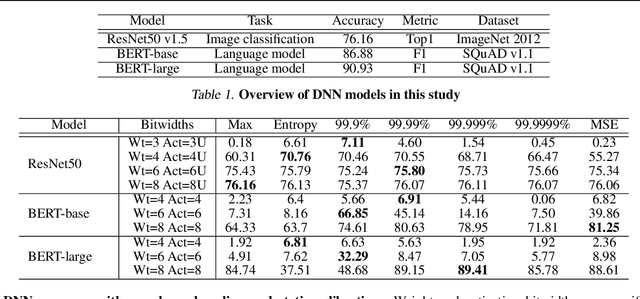
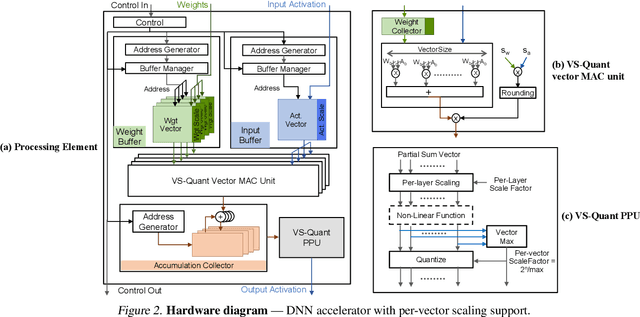
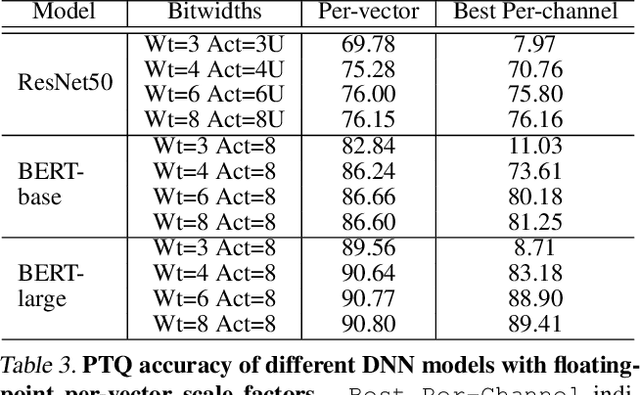
Quantization enables efficient acceleration of deep neural networks by reducing model memory footprint and exploiting low-cost integer math hardware units. Quantization maps floating-point weights and activations in a trained model to low-bitwidth integer values using scale factors. Excessive quantization, reducing precision too aggressively, results in accuracy degradation. When scale factors are shared at a coarse granularity across many dimensions of each tensor, effective precision of individual elements within the tensor are limited. To reduce quantization-related accuracy loss, we propose using a separate scale factor for each small vector of ($\approx$16-64) elements within a single dimension of a tensor. To achieve an efficient hardware implementation, the per-vector scale factors can be implemented with low-bitwidth integers when calibrated using a two-level quantization scheme. We find that per-vector scaling consistently achieves better inference accuracy at low precision compared to conventional scaling techniques for popular neural networks without requiring retraining. We also modify a deep learning accelerator hardware design to study the area and energy overheads of per-vector scaling support. Our evaluation demonstrates that per-vector scaled quantization with 4-bit weights and activations achieves 37% area saving and 24% energy saving while maintaining over 75% accuracy for ResNet50 on ImageNet. 4-bit weights and 8-bit activations achieve near-full-precision accuracy for both BERT-base and BERT-large on SQuAD while reducing area by 26% compared to an 8-bit baseline.