 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyeriss v2: A Flexible and High-Performance Accelerator for Emerging Deep Neural Networks
Jul 10, 2018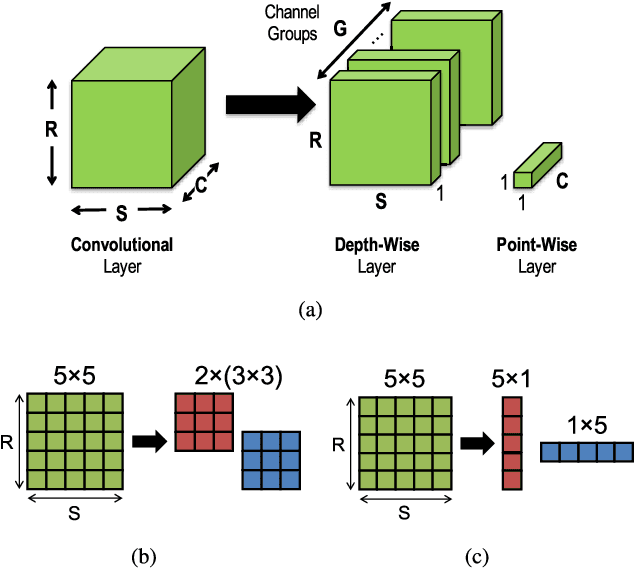
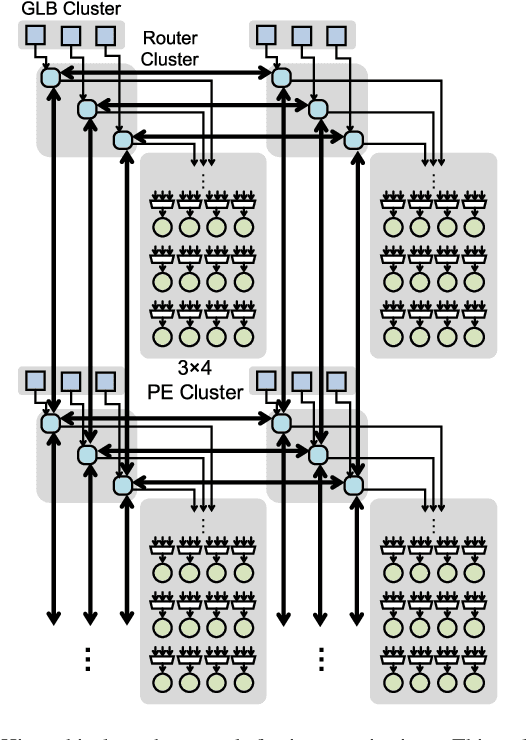
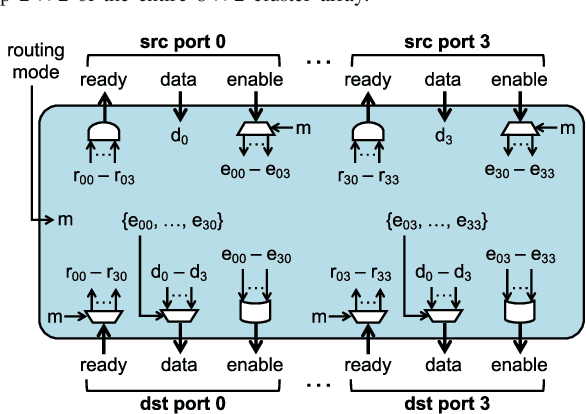
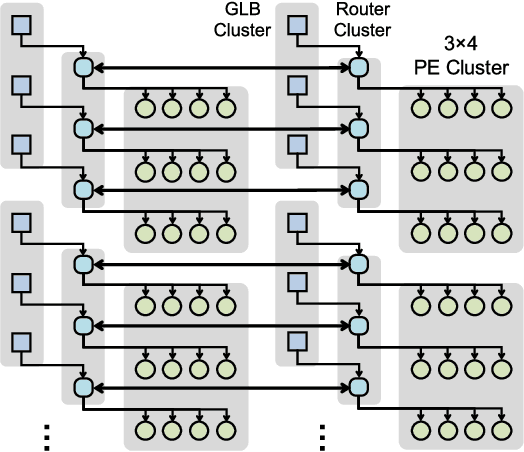
The design of DNNs has increasingly focused on reducing the computational complexity in addition to improving accuracy. While emerging DNNs tend to have fewer weights and operations, they also reduce the amount of data reuse with more widely varying layer shapes and sizes. This leads to a diverse set of DNNs, ranging from large ones with high reuse (e.g., AlexNet) to compact ones with high bandwidth requirements (e.g., MobileNet). However, many existing DNN processors depend on certain DNN properties, e.g., a large number of channels, to achieve high performance and energy efficiency and do not have sufficient flexibility to efficiently process a diverse set of DNNs. In this work, we present Eyexam, a performance analysis framework that quantitatively identifies the sources of performance loss in DNN processors. It highlights two architectural bottlenecks in many existing designs. First, their dataflows are not flexible enough to adapt to the varying layer shapes and sizes of different DNNs. Second, their network-on-chip (NoC) can't adapt to support both high data reuse and high bandwidth scenarios. Based on this analysis, we present Eyeriss v2, a high-performance DNN accelerator that adapts to a wide range of DNNs. Eyeriss v2 has a new dataflow, called Row-Stationary Plus (RS+), that enables the spatial tiling of data from all dimensions to fully utilize the parallelism for high performance. To support RS+, it has a low-cost and scalable NoC design, called hierarchical mesh, that connects the high-bandwidth global buffer to the array of processing elements (PEs) in a two-level hierarchy. This enables high-bandwidth data delivery while still being able to harness any available data reuse. Compared with Eyeriss, Eyeriss v2 has a performance increase of 10.4x-17.9x for 256 PEs, 37.7x-71.5x for 1024 PEs, and 448.8x-1086.7x for 16384 PEs on DNNs with widely varying amounts of data reuse.
Hardware for Machine Learning: Challenges and Opportunities
Oct 17, 2017

Machine learning plays a critical role in extracting meaningful information out of the zetabytes of sensor data collected every day. For some applications, the goal is to analyze and understand the data to identify trends (e.g., surveillance, portable/wearable electronics); in other applications, the goal is to take immediate action based the data (e.g., robotics/drones, self-driving cars, smart Internet of Things). For many of these applications, local embedded processing near the sensor is preferred over the cloud due to privacy or latency concerns, or limitations in the communication bandwidth. However, at the sensor there are often stringent constraints on energy consumption and cost in addition to throughput and accuracy requirements. Furthermore, flexibility is often required such that the processing can be adapted for different applications or environments (e.g., update the weights and model in the classifier). In many applications, machine learning often involves transforming the input data into a higher dimensional space, which, along with programmable weights, increases data movement and consequently energy consumption. In this paper, we will discuss how these challenges can be addressed at various levels of hardware design ranging from architecture, hardware-friendly algorithms, mixed-signal circuits, and advanced technologies (including memories and sensors).
Efficient Processing of Deep Neural Networks: A Tutorial and Survey
Aug 13, 2017

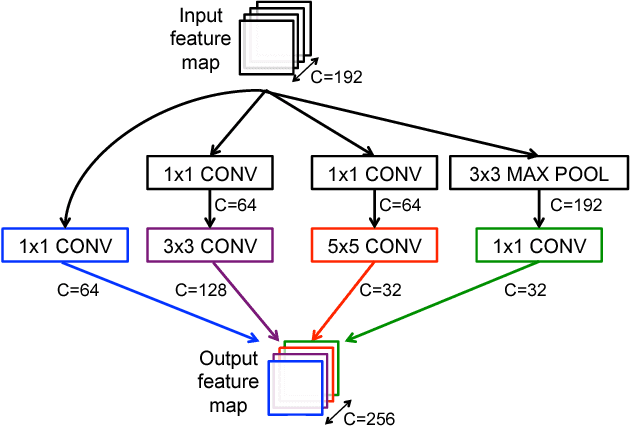
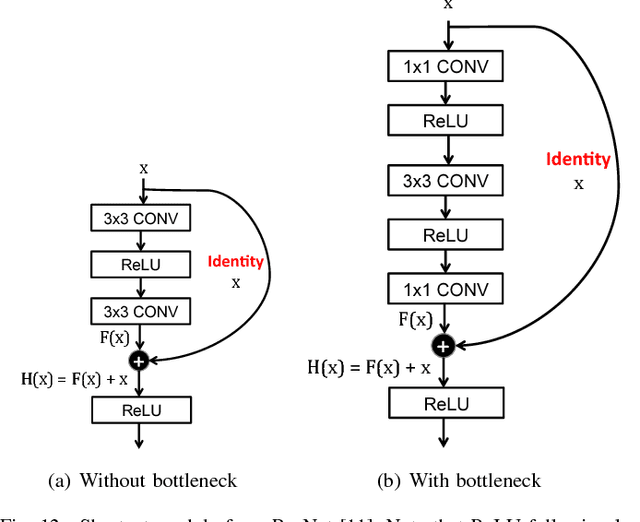
Deep neural networks (DNNs) are currently widely used for many artificial intelligence (AI) applications including computer vision, speech recognition, and robotics. While DNNs deliver state-of-the-art accuracy on many AI tasks, it comes at the cost of high computational complexity. Accordingly, techniques that enable efficient processing of DNNs to improve energy efficiency and throughput without sacrificing application accuracy or increasing hardware cost are critical to the wide deployment of DNNs in AI systems. This article aims to provide a comprehensive tutorial and survey about the recent advances towards the goal of enabling efficient processing of DNNs. Specifically, it will provide an overview of DNNs, discuss various hardware platforms and architectures that support DNNs, and highlight key trends in reducing the computation cost of DNNs either solely via hardware design changes or via joint hardware design and DNN algorithm changes. It will also summarize various development resources that enable researchers and practitioners to quickly get started in this field, and highlight important benchmarking metrics and design considerations that should be used for evaluating the rapidly growing number of DNN hardware designs, optionally including algorithmic co-designs, being proposed in academia and industry. The reader will take away the following concepts from this article: understand the key design considerations for DNNs; be able to evaluate different DNN hardware implementations with benchmarks and comparison metrics; understand the trade-offs between various hardware architectures and platforms; be able to evaluate the utility of various DNN design techniques for efficient processing; and understand recent implementation trends and opportunities.
SCNN: An Accelerator for Compressed-sparse Convolutional Neural Networks
May 23, 2017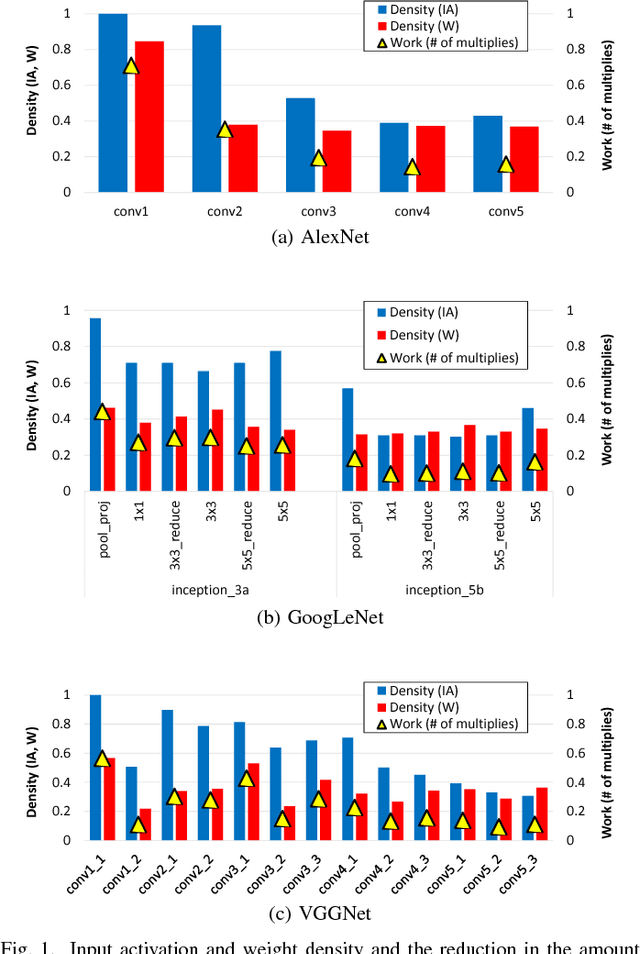
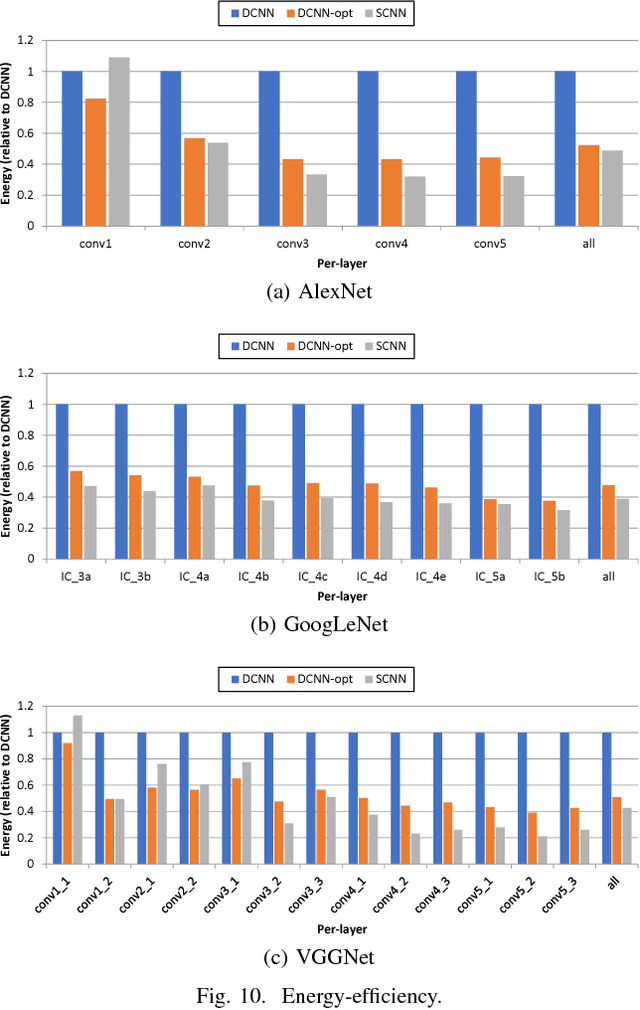
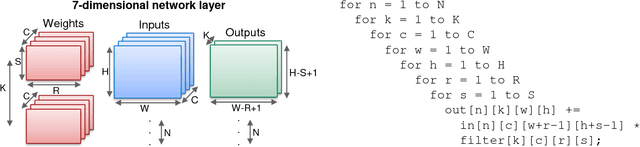

Convolutional Neural Networks (CNNs) have emerged as a fundamental technology for machine learning. High performance and extreme energy efficiency are critical for deployments of CNNs in a wide range of situations, especially mobile platforms such as autonomous vehicles, cameras, and electronic personal assistants. This paper introduces the Sparse CNN (SCNN) accelerator architecture, which improves performance and energy efficiency by exploiting the zero-valued weights that stem from network pruning during training and zero-valued activations that arise from the common ReLU operator applied during inference. Specifically, SCNN employs a novel dataflow that enables maintaining the sparse weights and activations in a compressed encoding, which eliminates unnecessary data transfers and reduces storage requirements. Furthermore, the SCNN dataflow facilitates efficient delivery of those weights and activations to the multiplier array, where they are extensively reused. In addition, the accumulation of multiplication products are performed in a novel accumulator array. Our results show that on contemporary neural networks, SCNN can improve both performance and energy by a factor of 2.7x and 2.3x, respectively, over a comparably provisioned dense CNN accelerator.
Towards Closing the Energy Gap Between HOG and CNN Features for Embedded Vision
Mar 17, 2017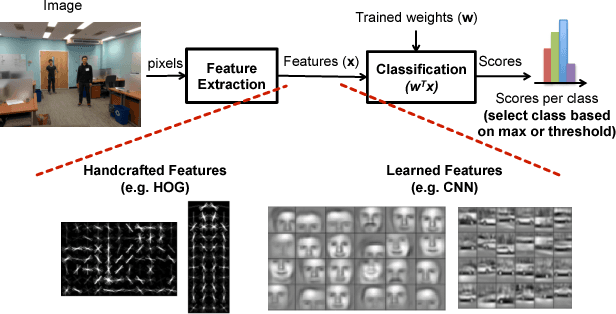
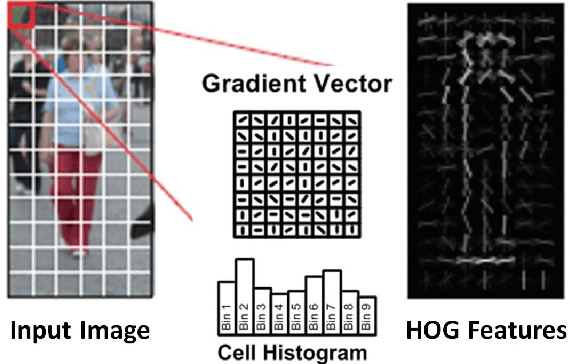


Computer vision enables a wide range of applications in robotics/drones, self-driving cars, smart Internet of Things, and portable/wearable electronics. For many of these applications, local embedded processing is preferred due to privacy and/or latency concerns. Accordingly, energy-efficient embedded vision hardware delivering real-time and robust performance is crucial. While deep learning is gaining popularity in several computer vision algorithms, a significant energy consumption difference exists compared to traditional hand-crafted approaches. In this paper, we provide an in-depth analysis of the computation, energy and accuracy trade-offs between learned features such as deep Convolutional Neural Networks (CNN) and hand-crafted features such as Histogram of Oriented Gradients (HOG). This analysis is supported by measurements from two chips that implement these algorithms. Our goal is to understand the source of the energy discrepancy between the two approaches and to provide insight about the potential areas where CNNs can be improved and eventually approach the energy-efficiency of HOG while maintaining its outstanding performance accuracy.