 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Out-of-sample Embedding in UMAP
Jun 03, 2026Neighbor embedding algorithms reveal correlations in high-dimensional data by constructing an equivalent graph representation in a lower-dimensional space. An increasingly popular algorithm is Uniform Manifold Learning and Projection (UMAP), which uses algebraic topology to map distances between the two spaces. While it works well on many types of data sets, UMAP has trouble adding out-of-sample points to a pre-existing mapping. In particular, UMAP often places new points on the periphery of the found clusters, rather than in their interiors with their correlated neighbors. Here, we overcome this ``repulsion effect'' by optimizing pairwise interactions within the original k-nearest-neighbor graph. Moreover, we show that parameterizing UMAP obtains better embeddings than non-parametric algorithms, particularly as the data gets more complex (e.g., medical images). We also show that the repulsion effect is naturally mitigated when a parameterized UMAP is employed to embed the data. We characterize different UMAP approaches using trustworthiness, nearest neighbor classifiers, and by analyzing attractive and repulsive forces in the embeddings.
Manifold Approximation leads to Robust Kernel Alignment
Oct 27, 2025Centered kernel alignment (CKA) is a popular metric for comparing representations, determining equivalence of networks, and neuroscience research. However, CKA does not account for the underlying manifold and relies on numerous heuristics that cause it to behave differently at different scales of data. In this work, we propose Manifold approximated Kernel Alignment (MKA), which incorporates manifold geometry into the alignment task. We derive a theoretical framework for MKA. We perform empirical evaluations on synthetic datasets and real-world examples to characterize and compare MKA to its contemporaries. Our findings suggest that manifold-aware kernel alignment provides a more robust foundation for measuring representations, with potential applications in representation learning.
GastroViT: A Vision Transformer Based Ensemble Learning Approach for Gastrointestinal Disease Classification with Grad CAM & SHAP Visualization
Sep 30, 2025The gastrointestinal (GI) tract of humans can have a wide variety of aberrant mucosal abnormality findings, ranging from mild irritations to extremely fatal illnesses. Prompt identification of gastrointestinal disorders greatly contributes to arresting the progression of the illness and improving therapeutic outcomes. This paper presents an ensemble of pre-trained vision transformers (ViTs) for accurately classifying endoscopic images of the GI tract to categorize gastrointestinal problems and illnesses. ViTs, attention-based neural networks, have revolutionized image recognition by leveraging the transformative power of the transformer architecture, achieving state-of-the-art (SOTA) performance across various visual tasks. The proposed model was evaluated on the publicly available HyperKvasir dataset with 10,662 images of 23 different GI diseases for the purpose of identifying GI tract diseases. An ensemble method is proposed utilizing the predictions of two pre-trained models, MobileViT_XS and MobileViT_V2_200, which achieved accuracies of 90.57% and 90.48%, respectively. All the individual models are outperformed by the ensemble model, GastroViT, with an average precision, recall, F1 score, and accuracy of 69%, 63%, 64%, and 91.98%, respectively, in the first testing that involves 23 classes. The model comprises only 20 million (M) parameters, even without data augmentation and despite the highly imbalanced dataset. For the second testing with 16 classes, the scores are even higher, with average precision, recall, F1 score, and accuracy of 87%, 86%, 87%, and 92.70%, respectively. Additionally, the incorporation of explainable AI (XAI) methods such as Grad-CAM (Gradient Weighted Class Activation Mapping) and SHAP (Shapley Additive Explanations) enhances model interpretability, providing valuable insights for reliable GI diagnosis in real-world settings.
The Shape of Attraction in UMAP: Exploring the Embedding Forces in Dimensionality Reduction
Mar 12, 2025Uniform manifold approximation and projection (UMAP) is among the most popular neighbor embedding methods. The method relies on attractive and repulsive forces among high-dimensional data points to obtain a low-dimensional embedding. In this paper, we analyze the forces to reveal their effects on cluster formations and visualization. Repulsion emphasizes differences, controlling cluster boundaries and inter-cluster distance. Attraction is more subtle, as attractive tension between points can manifest simultaneously as attraction and repulsion in the lower-dimensional mapping. This explains the need for learning rate annealing and motivates the different treatments between attractive and repulsive terms. Moreover, by modifying attraction, we improve the consistency of cluster formation under random initialization. Overall, our analysis makes UMAP and similar embedding methods more interpretable, more robust, and more accurate.
Soil Characterization of Watermelon Field through Internet of Things: A New Approach to Soil Salinity Measurement
Nov 22, 2024
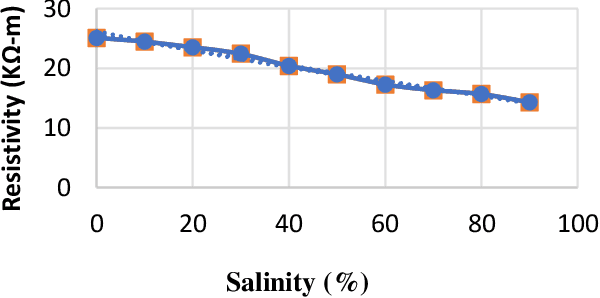
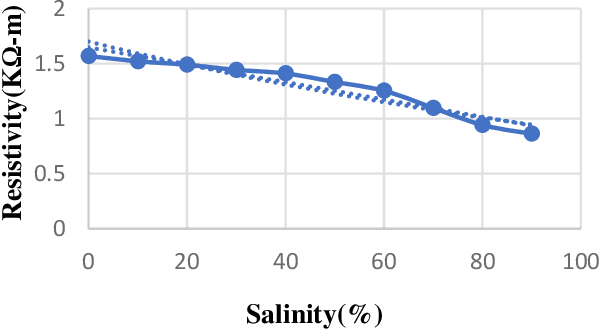
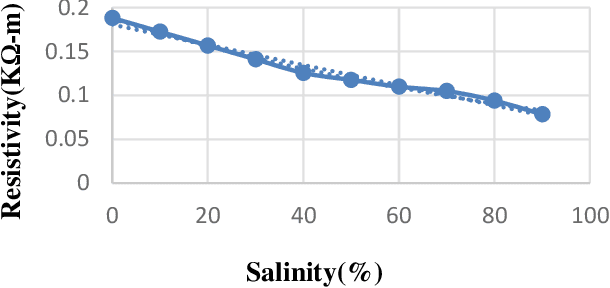
In the modern agricultural industry, technology plays a crucial role in the advancement of cultivation. To increase crop productivity, soil require some specific characteristics. For watermelon cultivation, soil needs to be sandy and of high temperature with proper irrigation. This research aims to design and implement an intelligent IoT-based soil characterization system for the watermelon field to measure the soil characteristics. IoT based developed system measures moisture, temperature, and pH of soil using different sensors, and the sensor data is uploaded to the cloud via Arduino and Raspberry Pi, from where users can obtain the data using mobile application and webpage developed for this system. To ensure the precision of the framework, this study includes the comparison between the readings of the soil parameters by the existing field soil meters, the values obtained from the sensors integrated IoT system, and data obtained from soil science laboratory. Excessive salinity in soil affects the watermelon yield. This paper proposes a model for the measurement of soil salinity based on soil resistivity. It establishes a relationship between soil salinity and soil resistivity from the data obtained in the laboratory using artificial neural network (ANN).
Outlier Detection in Large Radiological Datasets using UMAP
Aug 01, 2024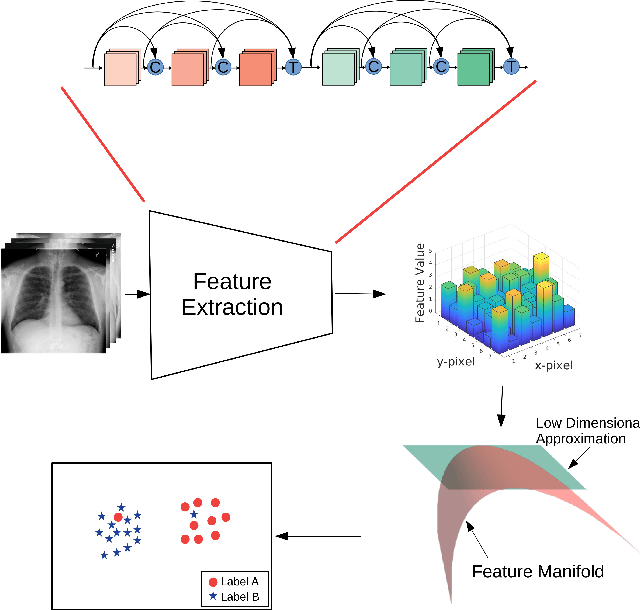
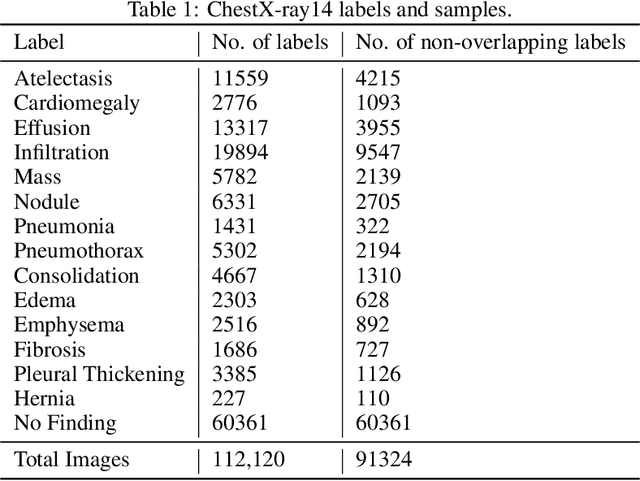
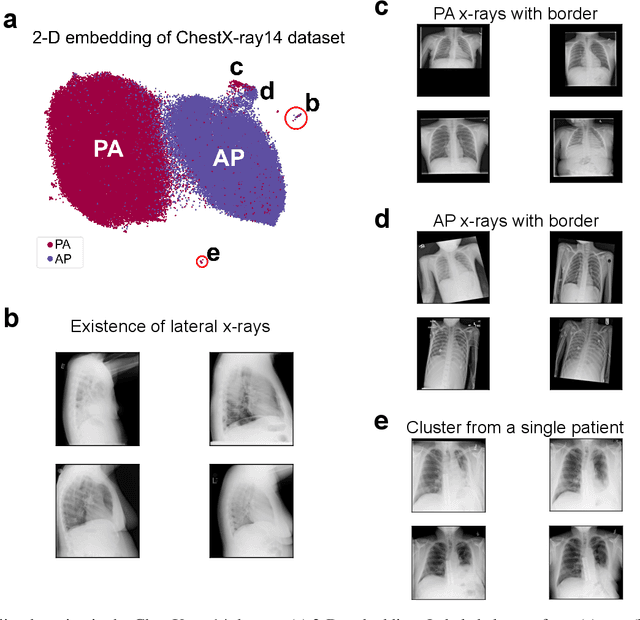
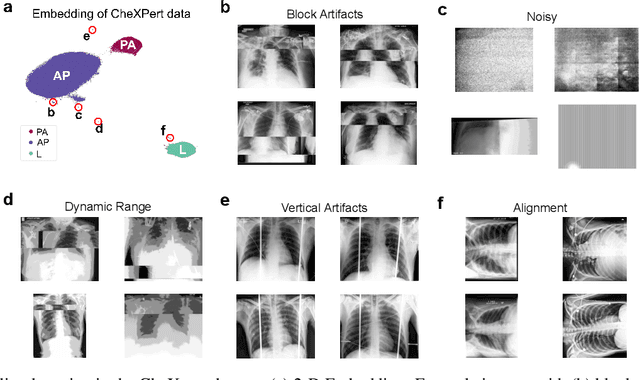
The success of machine learning algorithms heavily relies on the quality of samples and the accuracy of their corresponding labels. However, building and maintaining large, high-quality datasets is an enormous task. This is especially true for biomedical data and for meta-sets that are compiled from smaller ones, as variations in image quality, labeling, reports, and archiving can lead to errors, inconsistencies, and repeated samples. Here, we show that the uniform manifold approximation and projection (UMAP) algorithm can find these anomalies essentially by forming independent clusters that are distinct from the main (good) data but similar to other points with the same error type. As a representative example, we apply UMAP to discover outliers in the publicly available ChestX-ray14, CheXpert, and MURA datasets. While the results are archival and retrospective and focus on radiological images, the graph-based methods work for any data type and will prove equally beneficial for curation at the time of dataset creation.
Manifold-aligned Neighbor Embedding
May 19, 2022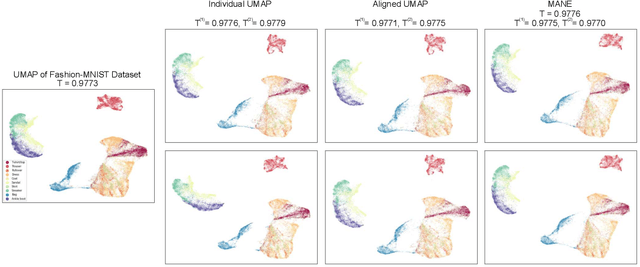


In this paper, we introduce a neighbor embedding framework for manifold alignment. We demonstrate the efficacy of the framework using a manifold-aligned version of the uniform manifold approximation and projection algorithm. We show that our algorithm can learn an aligned manifold that is visually competitive to embedding of the whole dataset.
A Shallow U-Net Architecture for Reliably Predicting Blood Pressure from Photoplethysmogram and Electrocardiogram Signals
Nov 12, 2021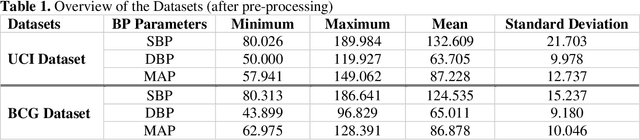
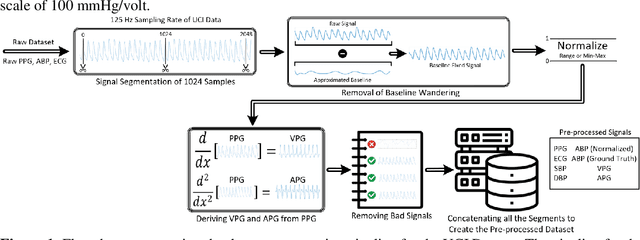
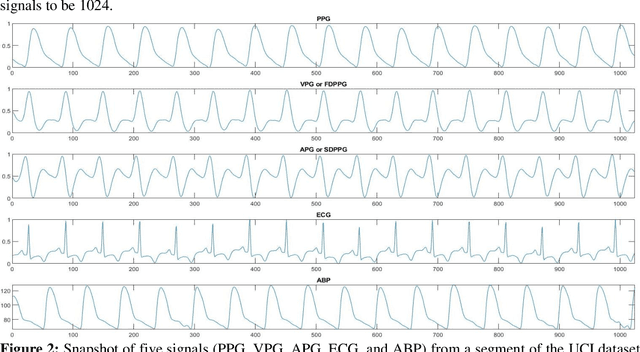
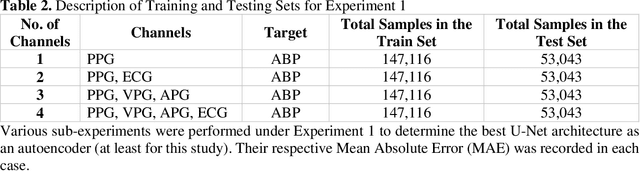
Cardiovascular diseases are the most common causes of death around the world. To detect and treat heart-related diseases, continuous Blood Pressure (BP) monitoring along with many other parameters are required. Several invasive and non-invasive methods have been developed for this purpose. Most existing methods used in the hospitals for continuous monitoring of BP are invasive. On the contrary, cuff-based BP monitoring methods, which can predict Systolic Blood Pressure (SBP) and Diastolic Blood Pressure (DBP), cannot be used for continuous monitoring. Several studies attempted to predict BP from non-invasively collectible signals such as Photoplethysmogram (PPG) and Electrocardiogram (ECG), which can be used for continuous monitoring. In this study, we explored the applicability of autoencoders in predicting BP from PPG and ECG signals. The investigation was carried out on 12,000 instances of 942 patients of the MIMIC-II dataset and it was found that a very shallow, one-dimensional autoencoder can extract the relevant features to predict the SBP and DBP with the state-of-the-art performance on a very large dataset. Independent test set from a portion of the MIMIC-II dataset provides an MAE of 2.333 and 0.713 for SBP and DBP, respectively. On an external dataset of forty subjects, the model trained on the MIMIC-II dataset, provides an MAE of 2.728 and 1.166 for SBP and DBP, respectively. For both the cases, the results met British Hypertension Society (BHS) Grade A and surpassed the studies from the current literature.
Multimodal EEG and Keystroke Dynamics Based Biometric System Using Machine Learning Algorithms
Mar 10, 2021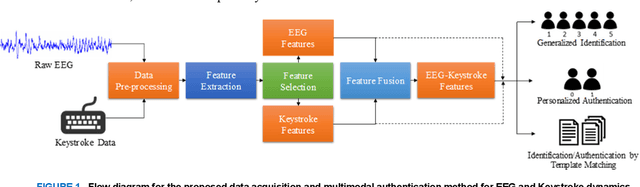
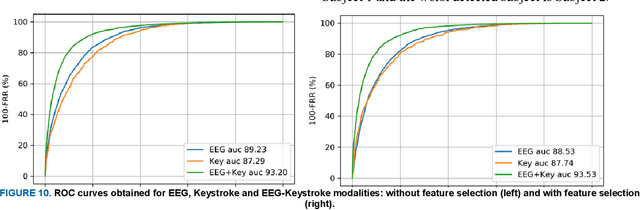

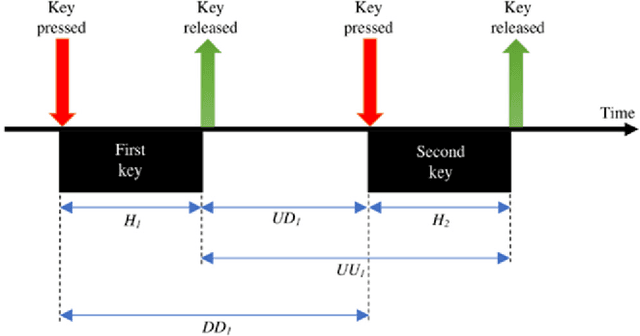
With the rapid advancement of technology, different biometric user authentication, and identification systems are emerging. Traditional biometric systems like face, fingerprint, and iris recognition, keystroke dynamics, etc. are prone to cyber-attacks and suffer from different disadvantages. Electroencephalography (EEG) based authentication has shown promise in overcoming these limitations. However, EEG-based authentication is less accurate due to signal variability at different psychological and physiological conditions. On the other hand, keystroke dynamics-based identification offers high accuracy but suffers from different spoofing attacks. To overcome these challenges, we propose a novel multimodal biometric system combining EEG and keystroke dynamics. Firstly, a dataset was created by acquiring both keystroke dynamics and EEG signals from 10 users with 500 trials per user at 10 different sessions. Different statistical, time, and frequency domain features were extracted and ranked from the EEG signals and key features were extracted from the keystroke dynamics. Different classifiers were trained, validated, and tested for both individual and combined modalities for two different classification strategies - personalized and generalized. Results show that very high accuracy can be achieved both in generalized and personalized cases for the combination of EEG and keystroke dynamics. The identification and authentication accuracies were found to be 99.80% and 99.68% for Extreme Gradient Boosting (XGBoost) and Random Forest classifiers, respectively which outperform the individual modalities with a significant margin (around 5 percent). We also developed a binary template matching-based algorithm, which gives 93.64% accuracy 6X faster. The proposed method is secured and reliable for any kind of biometric authentication.
A Unified Learning Approach for Hand Gesture Recognition and Fingertip Detection
Jan 06, 2021
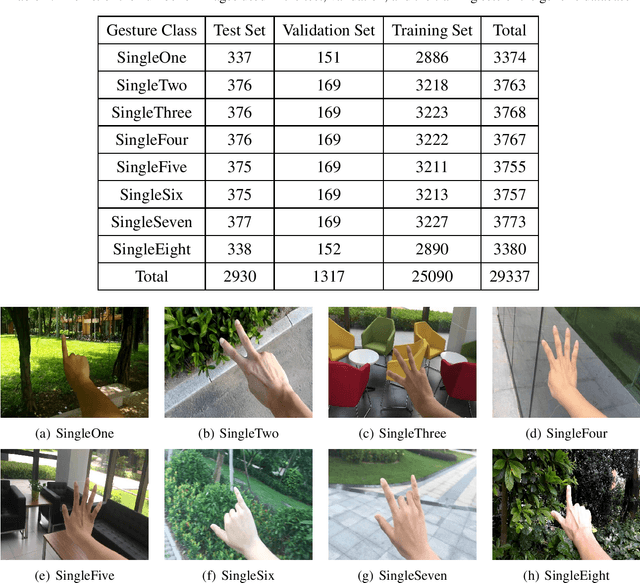
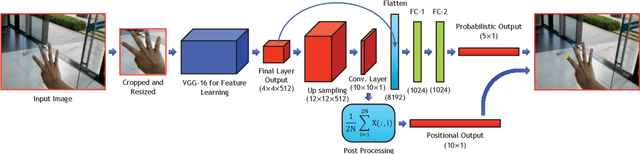
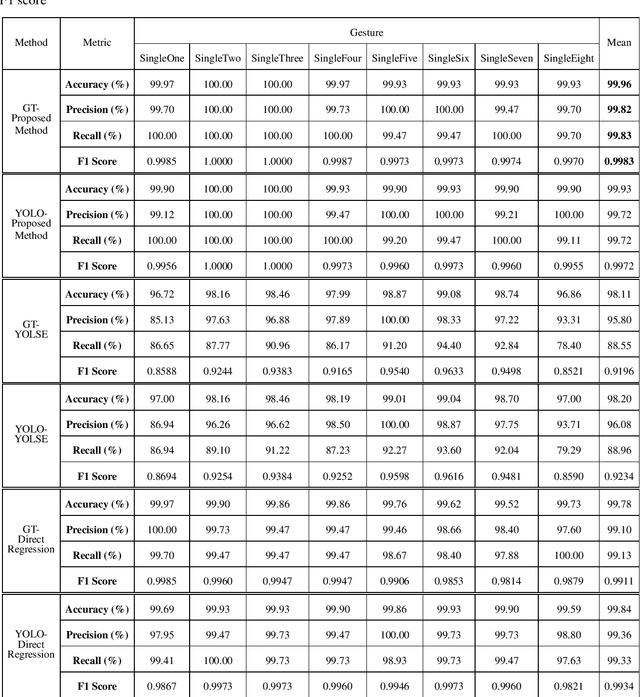
In human-computer interaction or sign language interpretation, recognizing hand gestures and detecting fingertips become ubiquitous in computer vision research. In this paper, a unified approach of convolutional neural network for both hand gesture recognition and fingertip detection is introduced. The proposed algorithm uses a single network to predict the probabilities of finger class and positions of fingertips in one forward propagation of the network. Instead of directly regressing the positions of fingertips from the fully connected layer, the ensemble of the position of fingertips is regressed from the fully convolutional network. Subsequently, the ensemble average is taken to regress the final position of fingertips. Since the whole pipeline uses a single network, it is significantly fast in computation. The proposed method results in remarkably less pixel error as compared to that in the direct regression approach and it outperforms the existing fingertip detection approaches including the Heatmap-based framework.