 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlier Detection in Large Radiological Datasets using UMAP
Paper and Code
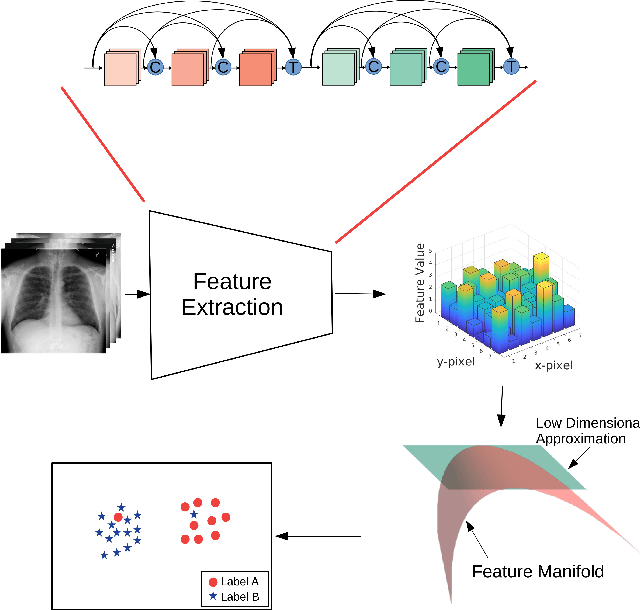
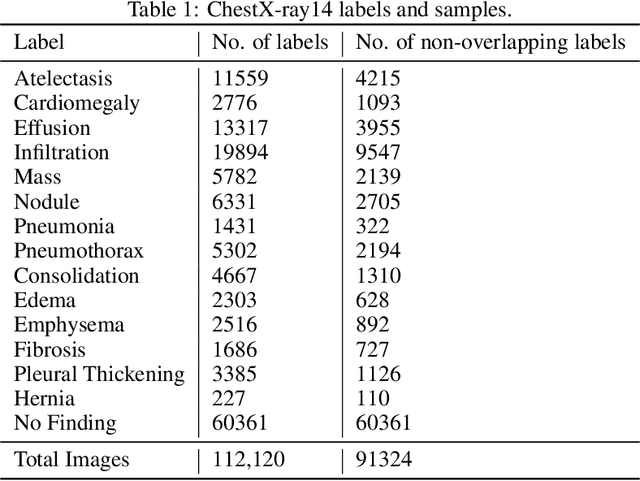
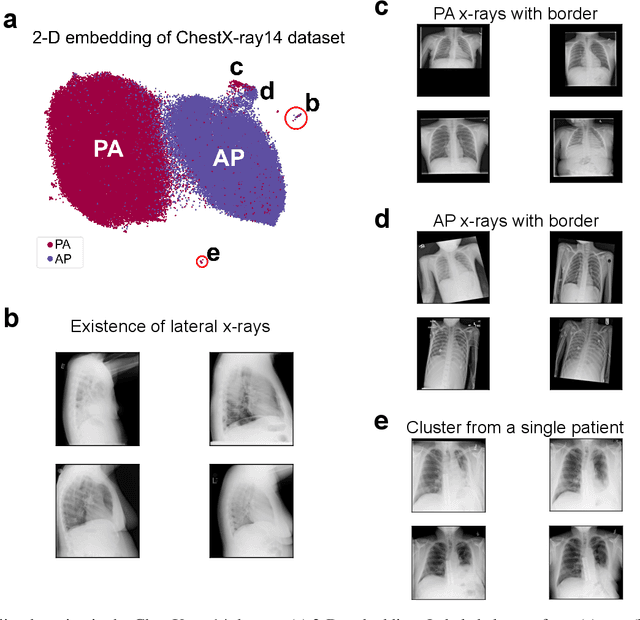
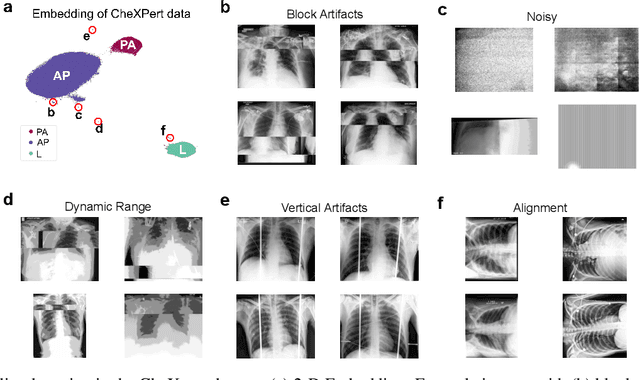
The success of machine learning algorithms heavily relies on the quality of samples and the accuracy of their corresponding labels. However, building and maintaining large, high-quality datasets is an enormous task. This is especially true for biomedical data and for meta-sets that are compiled from smaller ones, as variations in image quality, labeling, reports, and archiving can lead to errors, inconsistencies, and repeated samples. Here, we show that the uniform manifold approximation and projection (UMAP) algorithm can find these anomalies essentially by forming independent clusters that are distinct from the main (good) data but similar to other points with the same error type. As a representative example, we apply UMAP to discover outliers in the publicly available ChestX-ray14, CheXpert, and MURA datasets. While the results are archival and retrospective and focus on radiological images, the graph-based methods work for any data type and will prove equally beneficial for curation at the time of dataset creation.