 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoli: A dataset for understanding stuttering experience and analyzing stuttered speech
Jan 27, 2025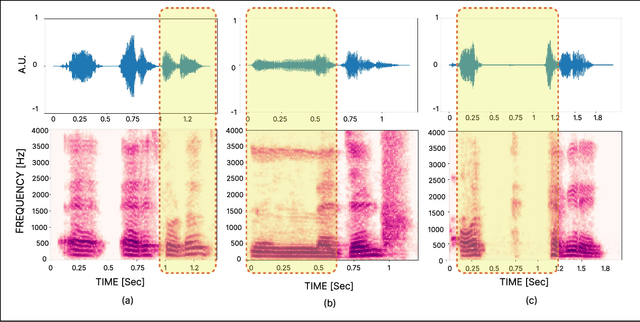
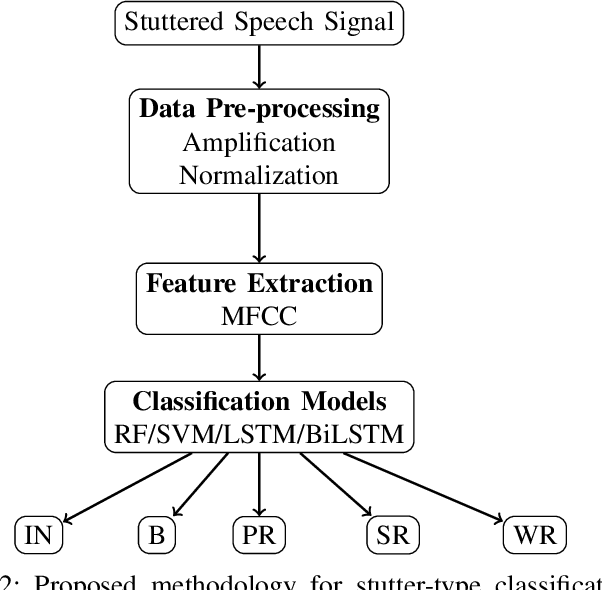
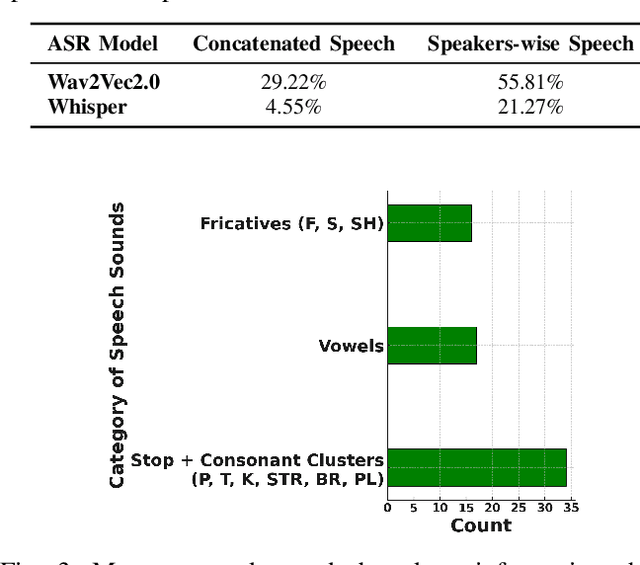

There is a growing need for diverse, high-quality stuttered speech data, particularly in the context of Indian languages. This paper introduces Project Boli, a multi-lingual stuttered speech dataset designed to advance scientific understanding and technology development for individuals who stutter, particularly in India. The dataset constitutes (a) anonymized metadata (gender, age, country, mother tongue) and responses to a questionnaire about how stuttering affects their daily lives, (b) captures both read speech (using the Rainbow Passage) and spontaneous speech (through image description tasks) for each participant and (c) includes detailed annotations of five stutter types: blocks, prolongations, interjections, sound repetitions and word repetitions. We present a comprehensive analysis of the dataset, including the data collection procedure, experience summarization of people who stutter, severity assessment of stuttering events and technical validation of the collected data. The dataset is released as an open access to further speech technology development.