 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional MCLP Analysis and Reconstruction for Spatial Speech Communication
Sep 09, 2021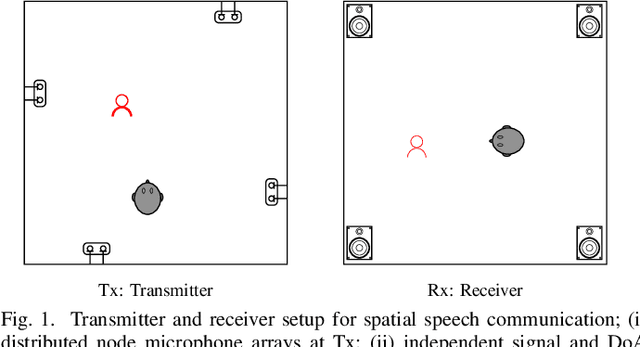

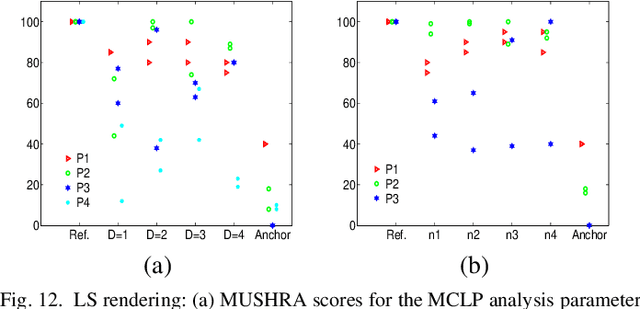
Spatial speech communication, i.e., the reconstruction of spoken signal along with the relative speaker position in the enclosure (reverberation information) is considered in this paper. Directional, diffuse components and the source position information are estimated at the transmitter, and perceptually effective reproduction is considered at the receiver. We consider spatially distributed microphone arrays for signal acquisition, and node specific signal estimation, along with its direction of arrival (DoA) estimation. Short-time Fourier transform (STFT) domain multi-channel linear prediction (MCLP) approach is used to model the diffuse component and relative acoustic transfer function is used to model the direct signal component. Distortion-less array response constraint and the time-varying complex Gaussian source model are used in the joint estimation of source DoA and the constituent signal components, separately at each node. The intersection between DoA directions at each node is used to compute the source position. Signal components computed at the node nearest to the estimated source position are taken as the signals for transmission. At the receiver, a four channel loud speaker (LS) setup is used for spatial reproduction, in which the source spatial image is reproduced relative to a chosen virtual listener position in the transmitter enclosure. Vector base amplitude panning (VBAP) method is used for direct component reproduction using the LS setup and the diffuse component is reproduced equally from all the loud speakers after decorrelation. This scheme of spatial speech communication is shown to be effective and more natural for hands-free telecommunication, through either loudspeaker listening or binaural headphone listening with head related transfer function (HRTF) based presentation.
Who Spoke What? A Latent Variable Framework for the Joint Decoding of Multiple Speakers and their Keywords
Apr 29, 2015
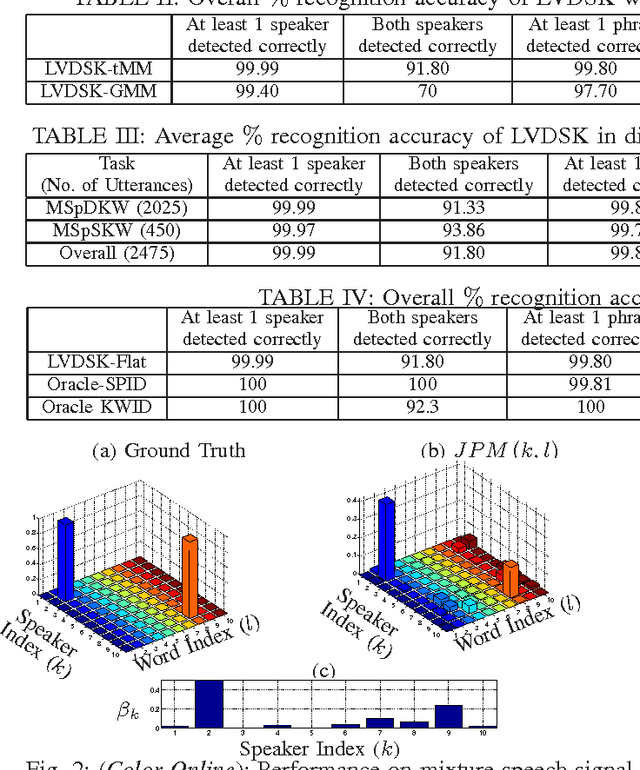
In this paper, we present a latent variable (LV) framework to identify all the speakers and their keywords given a multi-speaker mixture signal. We introduce two separate LVs to denote active speakers and the keywords uttered. The dependency of a spoken keyword on the speaker is modeled through a conditional probability mass function. The distribution of the mixture signal is expressed in terms of the LV mass functions and speaker-specific-keyword models. The proposed framework admits stochastic models, representing the probability density function of the observation vectors given that a particular speaker uttered a specific keyword, as speaker-specific-keyword models. The LV mass functions are estimated in a Maximum Likelihood framework using the Expectation Maximization (EM) algorithm. The active speakers and their keywords are detected as modes of the joint distribution of the two LVs. In mixture signals, containing two speakers uttering the keywords simultaneously, the proposed framework achieves an accuracy of 82% for detecting both the speakers and their respective keywords, using Student's-t mixture models as speaker-specific-keyword models.